自己动手写docker之namespace和cgroup
主要回答的问题
- namespace和cgroup的产生原因,各自的功能
- 虚拟化技术和容器技术对比时的一个误区。
- 容器实际上是什么?
- 通过命令行感受PID和MNT这两个namespace的隔离功能
- 通过命令行感受cgroup的限制功能(cpu)
- 查看docker是如何通过cgroup做到限制cpu的
- 为什么要在init进程中执行
mount -t proc proc /proc
namespace和cgroup(CentOS7.7)
Q:difference between cgroups and namespaces
- In short:
Cgroups = limitshow much you can use;
namespaces = limitswhat you can see(and therefore use)
Cgroups involve resource metering and limiting:
Namespaces provide processes with their own view of the system.(障眼法) - 中文结论: namespace 是用来做资源隔离, cgroup 是用来做资源限制
Q: 虚拟化技术和容器技术对比时的一个误区。
A: 容器化不是又一种虚拟化技术,容器是被障眼法所迷惑的一个个主机进程。
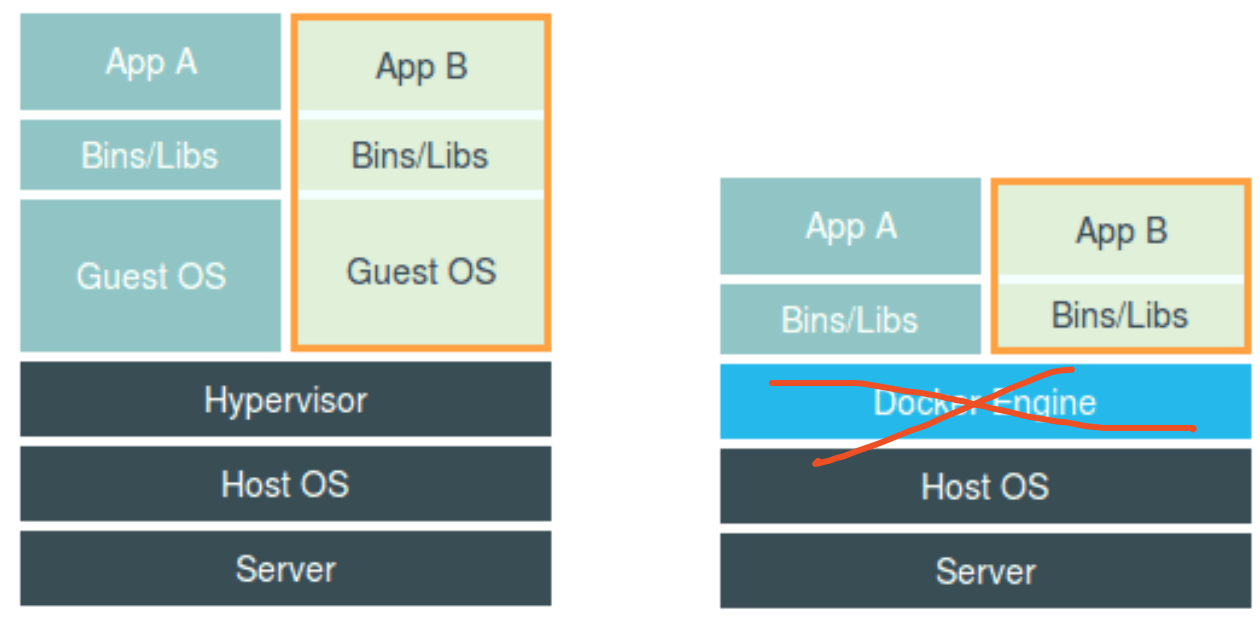
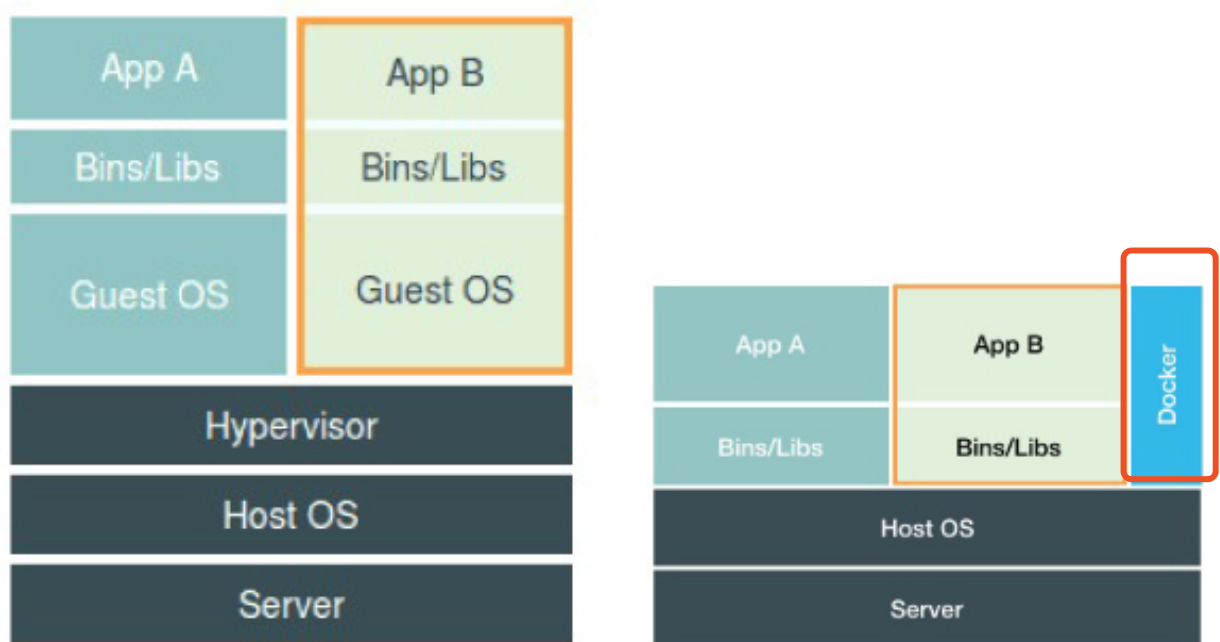
- Q: 容器实际上是什么?
A: 容器,其实是一种特殊的进程而已。
除了我们刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行障眼法操作。
比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。
所以,Docker 容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。
这样,容器就只能“看”到当前Namespace所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
05丨白话容器基础(一):从进程说开去
namespace
参考附录6(命令行和go代码实现)
6种资源可以被障眼法造成隔离效果
MNT Namespace和mount单独理解下
参考附录6
-
MNT Namespace的作用
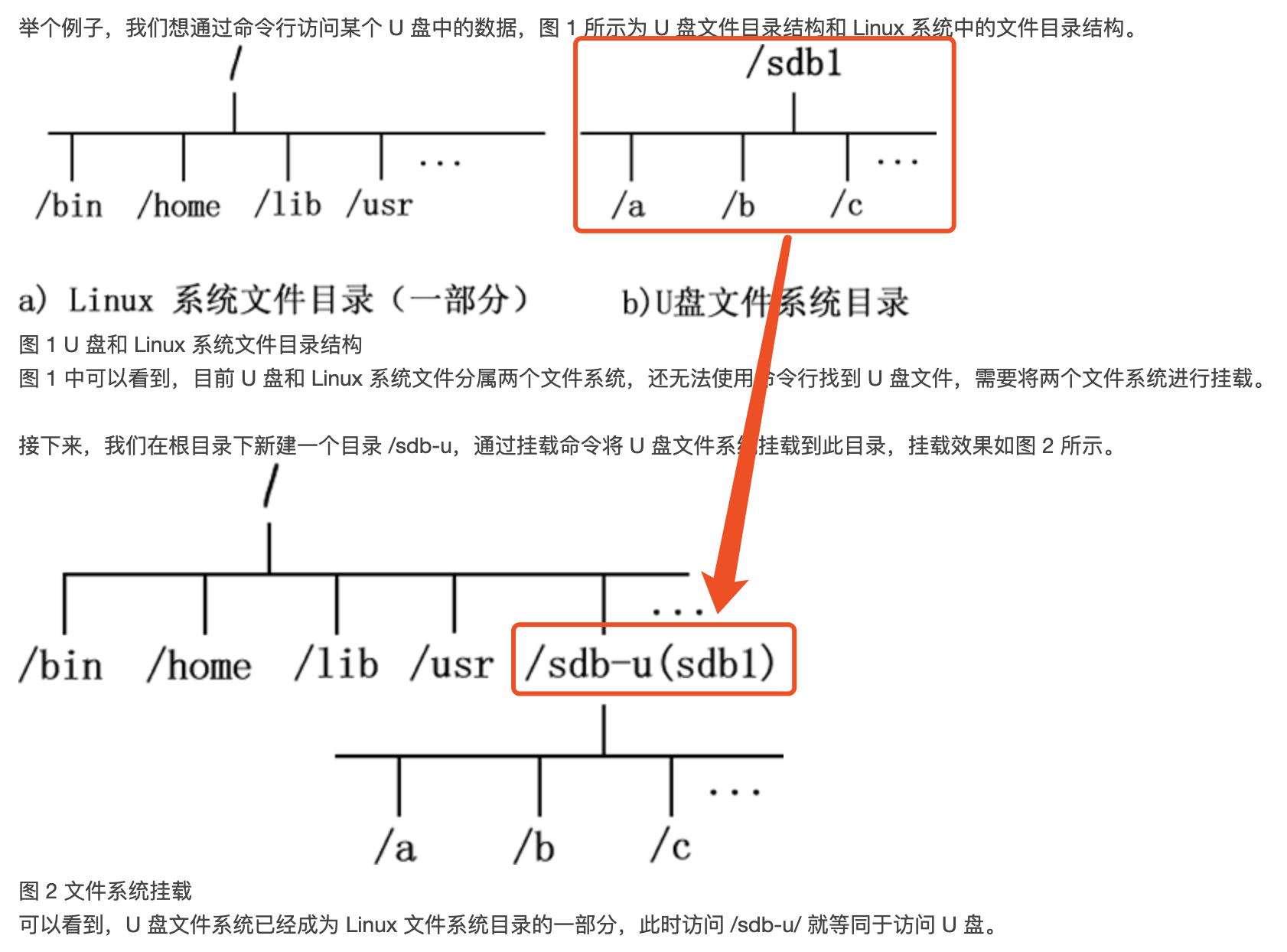
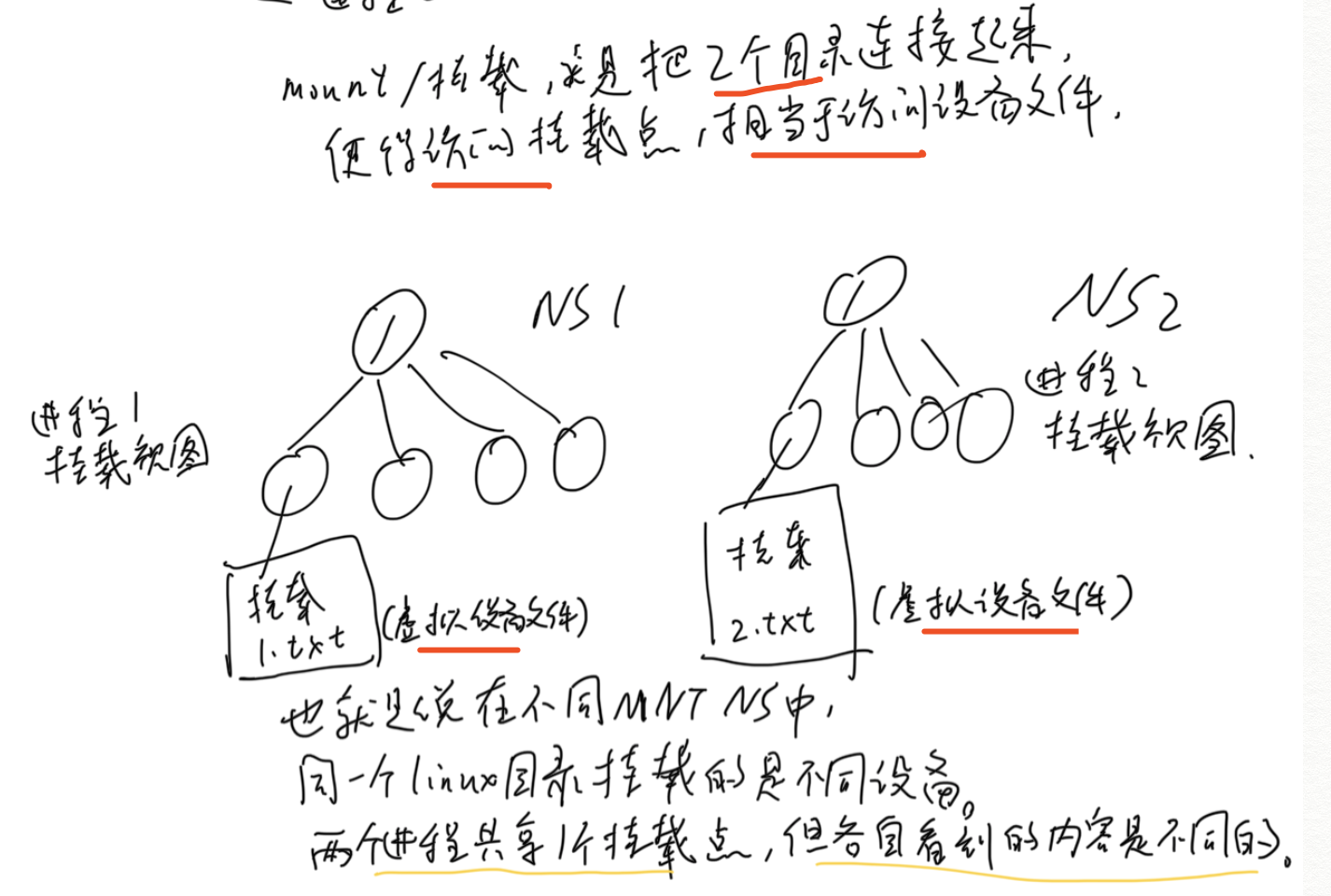
Mount Namespace用来隔离各个进程看到的挂载点视图。在不同Namespace的进程中,看到的文件系统层次是不一样的。
在Mount Namespace 中调用mount()和umount()仅仅只会影响当前Namespace内的文件系统,而对全局的文件系统是没有影响的. -
图解不同NS下的进程看到的挂载点视图不同
![]()
-
命令行演示
mkdir -p /tmp/test_mnt_namespace //在宿主机创建一个目录作为挂载点.
unshare --mount /bin/sh // 在不同的MNT NS中启动一个/bin/sh进程,随后进入该bash进程,之后的命令都是该bash进程内部执行的。
mount -t tmpfs tmpfs /tmp/test_mnt_namespace // 在新bash进程中挂载一个虚拟设备文件tmpfs到挂载点
cd /tmp/test_mnt_namespace // 访问这个挂载点,相当于访问虚拟设备文件tmpfs。
echo "pid:8493 mnt namespace" > test01.txt // 往其中放入文件text01.txt
ls // 查看当前文件
test01.txt
我们回到宿主机上查看/tmp/test_mnt_namespace是看不到text01.txt文件的。
如果我们用相同操作再创建一个bash进程放入text02.txt,那么在宿主机和第一个bash进程中都是看不到这个text02.txt的。
// 也就是说,尽管挂载点都是/tmp/test_mnt_namespace, 但是不同进程看到的内容(文件/目录)却是不同的,也就达到了隔离的效果。
- 据此可以解释为什么要在init进程中执行
mount -t proc proc /proc
/proc是他们共同的挂载点。但是每个进程看到的却可以不一样。run进程和init进程看到的不一样/proc。// PS. 第2个proc也可以理解为由内存模拟的虚拟设备文件,存放主机运行的统计信息。
如果不执行mount -t proc proc /proc,那么当执行 ps -ef时看到的就是整个宿主机的进程。因为ps -ef等命令的数据来源就是/proc下的内容。
USER Namespace
-
踩坑 内核3.10的linux中执行unshare --user /bin/bash报错Invalid argument,是什么原因?
max_user_namespaces文件记录了允许创建的user namespace数量,我的CentOS 7.5默认是0,修改之。 -
命令行演示
注意新启动的sh进程的用户是nobody,没有任何权限,也不属于任何用户组。
[root@192 invoke_other]# id
uid=0(root) gid=0(root) 组=0(root) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
[root@192 invoke_other]# unshare -U sh
sh-4.2$ id
uid=65534 gid=65534 组=65534 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
cgroup
参考附录8
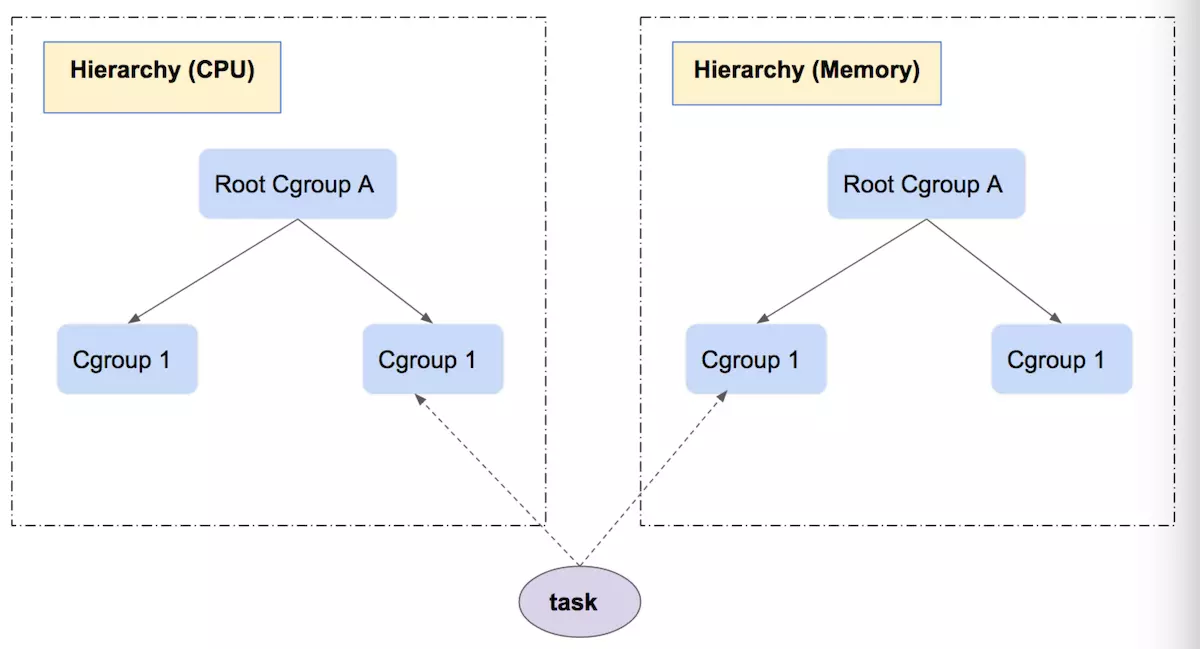
- 几个核心概念及其相互关系
tasks,cgroup(control group),hierarchy,subsystem(每种资源一棵树).
- tasks把几棵树关联起来,表示不同的资源限制组合。
- 层级关系可以传递资源限制。
![]()
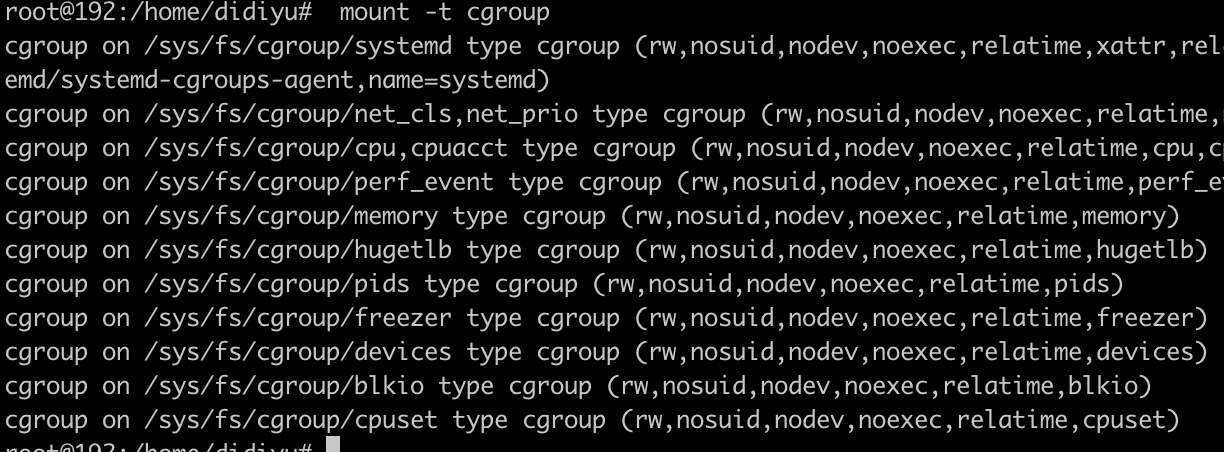
- 这几棵树实际对应着linux的几个目录树结构
/sys/fs/cgroup/目录下每个文件夹都对应一种资源的限制树。
![]()
- 自己使用cgroup实现cpu资源限制
参考附录7 - 查看docker如何利用cgroup实现cpu资源限制的 // CentOS
参考附录7
![]()

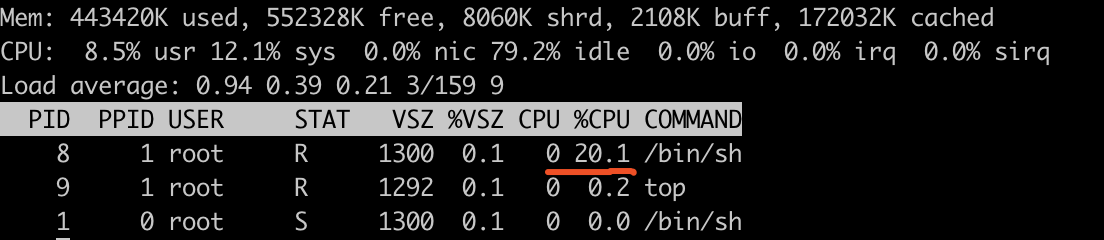
docker run -it --cpu-period=100000 --cpu-quota=20000 busybox /bin/sh // 限制100ms内只有20ms能使用,也就是20%
while : ; do : ; done & // 打满容器cpu
docker ps // 拿到运行容器的id
cd /sys/fs/cgroup/cpu/system.slice/docker-容器id.scope // 切换到该容器(进程)的对应的cpu-hierarchy目录中。
[root@192 docker-e2828f9ef030a9698c8c87025270a53768bac203d0d2e04a5289aa25c5e6697c.scope]# cat cpu.cfs_period_us cpu.cfs_quota_us // 查看配额 100ms/20ms
100000
20000
// 容器内执行top,见下图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号