
OCR
OCR(Optical Character Recognition,光学字符识别)
用于将图像中的文本转换为可编辑的文本。OCR系统可以识别印刷体或手写体的文字,并将其转换为计算机可处理的文本形式。是指电子设备 (例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程
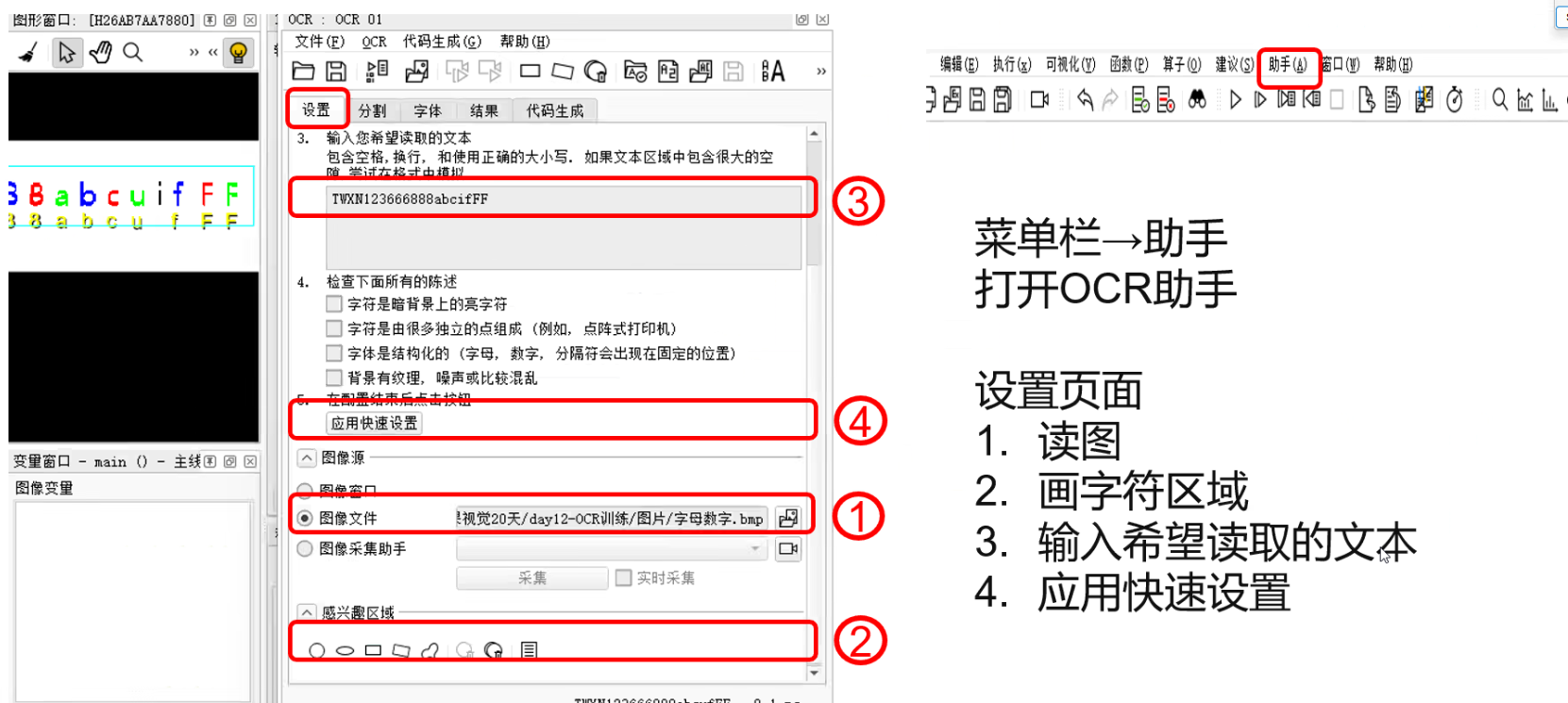
流程
1.读取图像
2.矫正字符的方向
3.分割字符区域
4.读取字符分类器
5.进行字符识别
矫正流程
*获取字符区域
gen_rectangle1(ROl 0,267.5,381.5,607.5,1129.5)
*根据刚刚所求区域获得倾斜角度
text_line_orientation (ROl_0, lmage, 25, -0.523599, 0.523599, OrientationAngle)
*仿射变换
*求单位矩阵
hom_mat2d_identity (HomMat2DIdentity)//*根据单位矩阵求旋转矩阵
hom_mat2d_rotate (HomMat2Dldentity, -OrientationAngle, Px,Py, HomMat2DRotate)*仿射变换作用到图像上
affine_trans_image (lmage, lmageAffinTrans, HomMat2D, 'constant false')
预处理
*灰度膨胀矩形
gray_dilation rect (lmage, lmageMax,7, 7)
*灰度腐蚀矩形
gray_erosion_rect (lmage, lmageMin, 11, 11)
灰度开运算矩形
gray_opening_rect (lmage, ImageOpening, 11,11)
灰度闭运算矩形
gray_closing_rect (lmage, lageClosing, 11, 11)
*图像取反
invert_image (lmage, lmagelnvert)
区域排序
sort_region (Region, SortedRegions, first point, 'true', 'row')区域排序
参数1:原区域
参数2:排序后的区域
参数3:排序模式
按照第一个点排序:一个区域的第一行的最前面的点'first point':last _point':按照最后一个点排序:一个区域的最后一行最后一列的那个点
upper_left:外接矩形的左上角
upper_right:外接矩形的右上角
lower_left:外接矩形的左下角
lower_right:外接矩形的右下角
character'从左到右,从上到下的顺序*参数4:确定排列顺序是递增的还是递减的。'true':递增;'false':递减参数5:输入参数,先按照行排列还是列排列
区域划分
gen_rectangle1(ROl_0,120,120,220,220) //图1
partition_rectangle (ROI_0, PartitionedRectangle,10,10) //图2
partition_dynamic(ROl_0, PartitionedDynamic,10,10)//图3

partition_dynamic(Region : Partitioned : Distance, Percent :)
定义:在垂直范围较小的位置对区域进行水平分区
使用说明: partition_dynamic将输入Region水平划分为具有大约Distance宽度的区域
Region:输入的区域
Partitioned:输出分割后的区域
Distance:输入的分割距离
Percent:(百分比)最终拆分位置与初始拆分位置的最大偏差为Distance*Percent*0.01
partition_rectangle(Region : Partitioned : Width, Height :)
定义:将区域划分为大小大致相等的矩形。
使用说明: partition rectangle将输入区域划分为范围为WidthxHeight的矩形
Region:输入的区域
Partitioned:输出分割后的区域
Width:矩形的宽
Height:矩形的高
点状特征提取
dots_image(lmage : Dotlmage : Diameter, FilterType, PixelShift : )
*点状物增强运算
dots_image (lmageMean, Dotlmage,5, light'0)
dots_image增强输入图像image中直径为diameter的圆形点
dots_image特别适合于点打打印的分
例,对于直径=5,过滤掩模由下式给出:

Diameter:点的直径
FilterType:选择是否应该增强图像中的“暗 (dark)”“亮(light)”或“所有(all)”点。
PixelShift:可用于增加输出图像的对比度(PixelShift > 0)或抑制极亮区域的值,否则这些区域会被切断(PixelShift = -1)。
-
OCR的工作原理是什么?
OCR工作的基本原理是通过图像处理和模式识别技术,将图像中的字符识别为文本。典型的OCR流程包括:
1.预处理:对图像进行处理,例如去噪、二值化等。
2.分割:将图像中的文本分割成单个字符或单词。
3.特征提取:提取每个字符的特征,以便进行识别。
4.分类:使用模型将字符映射到相应的文本。
5.后处理:对识别结果进行校正和修正。
-
OCR可用于哪些应用?
OCR广泛应用于许多领域,包括:
6.文字扫描:将纸质文档转换为数字文本。
7.数字化档案:将印刷的文档转换为可编辑的数字文档。
8.自动化数据输入:从印刷材料中提取数据,如发票、表格等。
9.手写文本识别:识别手写体文字。
10.识别车牌号码等。
·证件识别、车牌识别、智慧医疗、pdf文档转换为Word、拍照识别、截图识别、网络图片识别、无人驾驶、无纸化办公、稿件编辑校对、物流分拣、文档检索、字幕识别、文献资料检索等
-
OCR的精度如何?
OCR的精度取决于多个因素,包括图像质量、字体、文字大小、语言等。先进的OCR系统在标准条件下通常能够达到高精度,但在复杂条件下可能会受到影响。
4. 常见的OCR工具有哪些?
有许多OCR工具和库可供使用,包括:
11.Tesseract:由Google开发的开源OCR引擎。
12.ABBYY FineReader:商业OCR软件,具有强大的文本识别能力。
13.Adobe Acrobat OCR:Adobe Acrobat中集成的OCR功能。
14.Amazon Textract:Amazon Web Services(AWS)提供的云端OCR服务。
-
如何使用OCR?
使用OCR通常涉及选择适当的OCR工具或库,然后将其集成到你的应用程序或流程中。具体步骤包括加载图像、进行预处理、执行OCR、获取识别结果并进行后处理。
6. OCR的局限性是什么?
OCR在处理低分辨率图像、模糊图像或特殊字体时可能会面临挑战。此外,手写体识别相对复杂,依赖于写字人的风格。
使用OCR时,要根据具体的应用场景选择适当的工具,并进行适当的参数调整和优化以提高识别精度。
1.Iindustrial可用于读取以Arial,OCR-B或其他sans-serif字体等打印的字符。例如,这些字体通常用于打印标签
2.Universal可用于读取各种不同的字符。这种基于CNN训练的字体的基于Document,DotPrint,SEMI和Industrial'等字符
3.0CR-AOCR-B可用于读取以字体OCR-A、OCR-B打印的字符。(OCR-A和 OCR-B 字体有能够被 OCR 扫描设备准确读取的字符形状,包括银行支票、护照、序列标签和邮件。OCR-A 字体打印工业标准字符集,OCR-B 字体已从工业标准字符集扩展到包括完整的 Latin 1和 Latin 2支持。)
4.DotPrint可用于读取用点式打印机打印的字符。它不包含小写字符.
5.Document可用于读取以Arial,Courier或Times New Roman等字体打印的字符。这些是用于打印文档或字母的典型字体。
后缀带NoRe或Rei的字库内只相差了拒绝字符 032',拒绝字符表示当前字符并不在识别的模型中
1.卷积神经网络CNN
需要对输入图进行背景预分割,获取前景字符region部分,再送进分类器进行识别。
2支撑向量机SVM&最近邻KNN
未内置预训练好的模型,需要添加自定义的训练数据
3.多层感知机MLP
识别率高且分类速度更快,但是训练速度不及SVM
建议:用MLP初识别,CNN验证。预训练文件中CNN对应.occ文件,MLP对应.omc文件
识别模式
一、
使用TextModel 模式直接对输入图识别字符,无需进行先图形分割:
*创建自动文本阅读器模型
create_text_model_reader ('auto',Universal 0-9A-Z Rej, TextModel)
*设定参数文本包含点阵打印字符
set_text_model_param (TextModel, dot print, 'true')“
*设定参数字符与背景对比度40
set_text_model_param (TextModel, 'min contrast, 40)
*识别文本
find_text (lmage, TextModel, TextResultlD)
*获取识别的字符区域对象
get_text_object (Characters, TextResultlD, 'all lines'“
*获取识别的字符结果
get_text_result (TextResultlD, 'class', Class)
二、
通过需要经过预处理提取出字体对应的region对象,送入字符模型识别:
1.读取分类器
read_ocr_class_mlp (Industrial 0-9A-Z Rej.omc,OCRHandle)
2.进行ocr识别
do_ocr_multi_class_mlp(Character, lmage ::OCRHandle : Class, Confidence使用OCR分类多个字符
Character是字符区域
lmage是字符图片
OCRHandle是分类器句柄
Class是输出的类别
Confidence是输出的分类精度
single_class_mlp(CharacterSelected, lmagePart, OCRHandle1, Class, Confidence)do ocr
分类单个字符,其分类效果比上述同时分类多个字符的效果要好

