
学号20189220 2018-2019-2 《密码与安全新技术专题》第三周作业
学号20189220 2018-2019-2 《密码与安全新技术专题》第三周作业
课程:《密码与安全新技术专题》
班级: 1892
姓名: 余超
学号:20189220
上课教师:谢四江
上课日期:2019年2月26日
必修/选修: 选修
1.本次讲座的学习总结
本次讲座主要学习了机器学习、深度学习方面的基础知识以及与密码设计、密码分析相关的研究热点。主要分为以下四个方面来介绍:密码分析与机器学习、深度学习简介与现状、深度学习与密码分析、深度学习与密码设计。
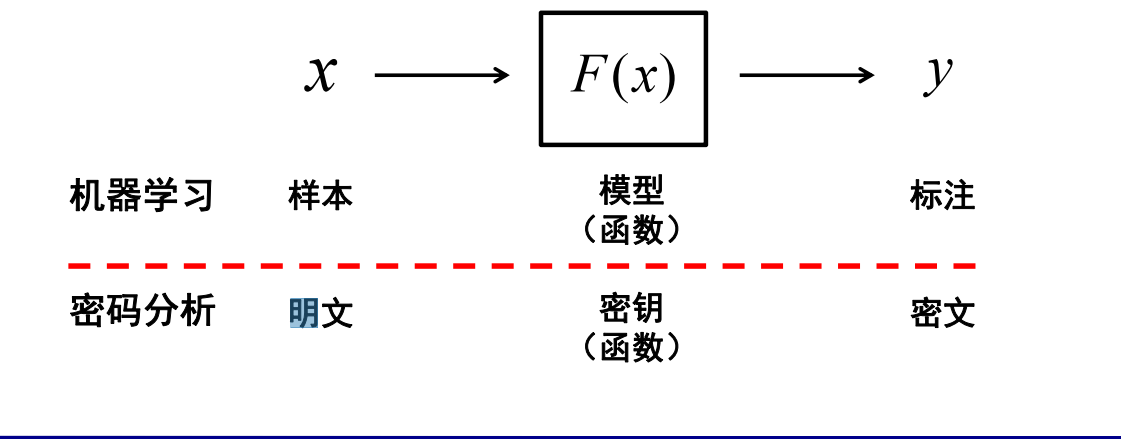
机器学习和密码分析
- 首先,密码分析与机器学习之间有天然的相似性,在密码分析中,攻击者试图通过推算出密钥来破解密码系统。解密函数是从一个由密钥索引的已知函数空间(解空间)求解出。攻击者的目的是发现解密函数的精确解。如果攻击者能够获取多个获取密文与明文配对来进行密码分析,其与机器学习的概念相似:机器学习的研究人员也是试图从多个样本与标签配对来进行机器学习模型的求解(训练)。
![]()
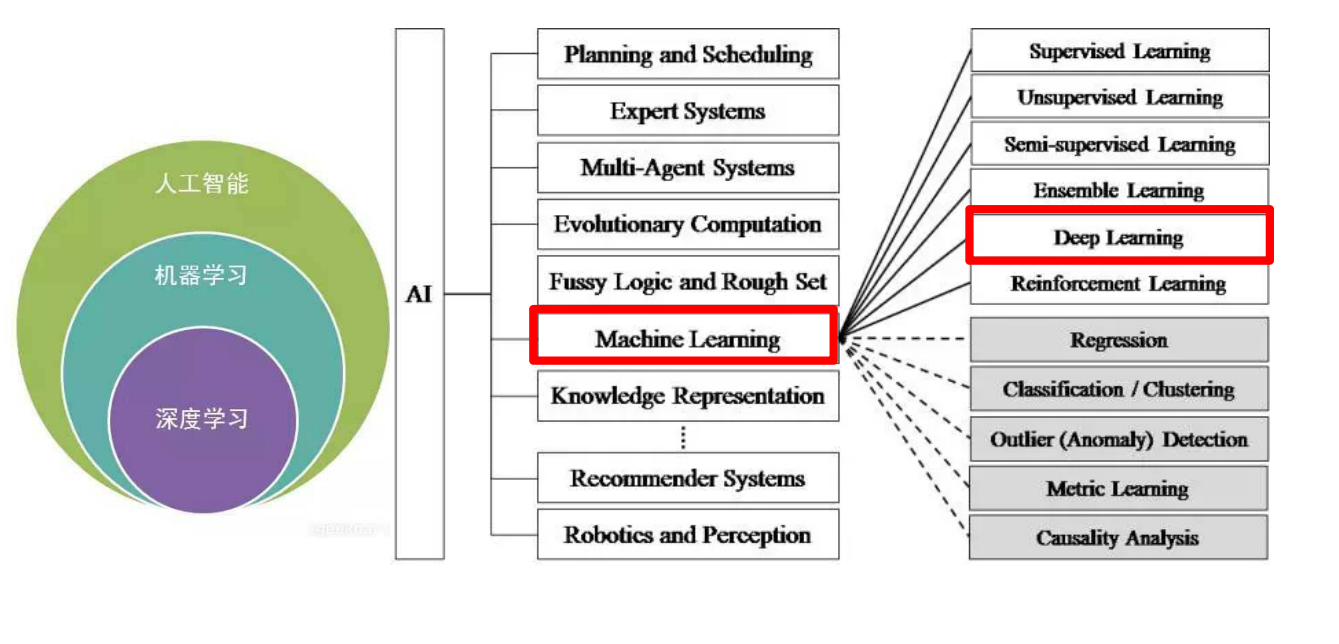
- 人工智能是一个很大的方面,机器学习知识其中的一个研究方向,而深度学习是机器学习的重点研究内容,发展的最为迅速和成熟,这三者是包含的关系。
![]()
深度学习的研究现状
深度学习极大地促进了机器学习的发展,收到世界各国相关领域研究人员和高科技公司的重视,语音、图像和自然语言处理是深度学习算法应用最广泛的三个主要研究领域:
1.深度学习在语音识别领域研究现状
长期以来,语音识别系统大多是采用高斯混合模型(GMM)来描述每个建模单元的概率模型。由于这种模型估计简单,方便使用大规模数据对其训练,该模型有较好的区分度训练算法,保证了该模型能够很好的训练。在很长时间内占据了语音识别应用领域主导性地位。但是GMM实质上一种浅层学习网络模型,特征的状态空间分布不能够被充分描述。而且,使用GMM建模数据的特征为数通常只有几十维,这使得特征之间的相关性不能被充分描述。最后GMM建模实质上是一种似然概率建模方式,即使一些模式分类之间的区分性能够通过区分度训练模拟得到,但是效果有限。
从2009年开始,微软亚洲研究院的语音识别专家们和深度学习领军人物Hinton合作。2011年微软公司推出基于深度神经网络的语音识别系统,这一成果将语音识别领域已有的技术框架完全改变。采用深度神经网络后,样本数据特征间相关性信息得以充分表示,将连续的特征信息结合构成高维特征,通过高维特征样本对深度神经网络模型进行训练。由于深度神经网络采用了模拟人脑神经架构,通过逐层的进行数据特征提取,最终得到适合进行模式分类处理的理想特征。
2.深度学习在图像识别领域研究现状
对于图像的处理是深度学习算法最早尝试应用的领域。早在1989年,加拿大多伦多大学教授Yann LeCun就和他的同事提出了卷积神经网络(Convolutional Neural Networks, CNN)它是一种包含卷积层的深度神经网络模型。通常一个卷机神经网络架构包含两个可以通过训练产生的非线性卷积层,两个固定的子采样层和一个全连接层,隐藏层的数量一般至少在5个以上。CNN的架构设计是受到生物学家Hube和Wiesel的动物视觉模型启发而发明的,尤其是模拟动物视觉皮层的V1层和V2层中简单细胞和复杂细胞在视觉系统的功能。起初卷积神经网络在小规模的问题上取得了当时世界最好成果。但是在很长一段时间里一直没有取得重大突破。主要原因是卷积神经网络应用在大尺寸图像上一直不能取得理想结果,比如对于像素数很大的自然图像内容的理解,这使得它没有引起计算机视觉研究领域足够的重视。2012年10月,Hinton教授以及他的学生采用更深的卷神经网络模型在著名的ImageNet问题上取得了世界最好结果,使得对于图像识别的领域研究更进一步。
自卷积神经网络提出以来,在图像识别问题上并没有取得质的提升和突破,直到2012年Hinton构建深度神经网络才去的惊人的成果。这主要是因为对算法的改进,在网络的训练中引入了权重衰减的概念,有效的减小权重幅度,防止网络过拟合。更关键的是计算机计算能力的提升,GPU加速技术的发展,使得在训练过程中可以产生更多的训练数据,使网络能够更好的拟合训练数据。2012年国内互联网巨头百度公司将相关最新技术成功应用到人脸识别和自然图像识别问题,并推出相应的产品。现在的深度学习网络模型已经能够理解和识别一般的自然图像。深度学习模型不仅大幅提高了图像识别的精度,同时也避免了需要消耗大量时间进行人工特征的提取,使得在线运行效率大大提升。
3.深度学习在自然语言处理领域研究现状
自然语言处理问题是深度学习在除了语音和图像处理之外的另一个重要的应用领域。数十年以来,自然语言处理的主流方法是基于统计的模型,人工神经网络也是基于统计方法模型之一,但在自然语言处理领域却一直没有被重视。语言建模时最早采用神经网络进行自然语言处理的问题。美国NEC研究院最早将深度学习引入到自然语言处理研究中,其研究院从2008年起采用将词汇映射到一维矢量空间和多层一维卷积结构去解决词性标注、分词、命名实体识别和语义角色标注四个典型的自然语言处理问题。他们构建了一个网络模型用于解决四个不同问题,都取得了相当精确的结果。总体而言,深度学习在自然语言处理上取得的成果和在图像语音识别方面相差甚远,仍有待深入研究。
深度学习与密码分析
这一节主要讲了基于卷积神经网络的侧信道攻击、基于循环神经网络的明文破译、基于生成对抗网络的口令破解、基于深度神经网络的密码基元识别。
两类算法,一种寻找内在的相关性,一种尽量使相关性降到最低。对于一个已经经过实践检验的加密算法(如 RAS),要在未知加密密钥或者解密密钥的情况下利用机器学习寻找内在联系是近乎不可能的,所以,我们先从已被废弃,健壮性弱的加密算法入手。
或者从另一方面,两种算法,一种要寻找随机,一种要建立关联,在两者之间可以用与生成对抗神经网络类似的算法,进行训练,或许就可以得到两个加密解密能力较强的神经网络。
除此之外,对于加密解密而言,假设有对于每个比特有90%的准确率,但是,由于有那些10%错误的影响,解密出来的信息也是无法识别的。比如在计算机里,一个英文字符占8个字节,则在每个比特只有90%的准确率下,能够解密出真正的明文的概率只有0.98=0.430.98=0.43左右,而且,就算解密出来一个字符,你也不能知道是否正确。假如用utf-8编码的汉字,准确率只有0.079.
2.学习中遇到的问题及解决
-
问题1:深度学习为什么需要深层次的网络?
问题1解决方案:
(1)、神经网络层数的增多会使每一层任务变得简单。 例如:计算乘法,我们可以在第一层计算按位加法,第 二层计算两个数的加法,第三层再计算乘法,这样使算法的逻辑更加简单,清晰。也就是说中间层可以做更深的抽象。
(2)、数学上可以证明只有一层隐藏层的神经网络可以表示任意的函数,但是神经元的数量却是指数级的递增,因此,通过使用深层的神经网络可以解决这个问题。 -
问题2:深度学习的局限性有哪些方面?
问题2解决方案:
第一局限,现今的人工智能技术,尤其是以深度学习为代表的,需要大量的标注数据,来让我们能够训练一个有效的模型,它不太依赖于人的先验知识,要learning from scratch。如果想从零开始学习就需要有大量的样本提供规律。比如,图像分类,现在通常会用上千万张图像来训练;语音识别,成千上万小时的有标注的语音数据;机器翻译一般都是在千万量级的双语语对上去做训练,这样的数据之前是不可想象的,但是我们这个时代是大数据时代,所以有了这些数据,就使得深度学习训练成为了可能。但这是不是一剂万能的灵药呢?其实在很多领域里是不可能或者是很难获得类似的数据的。比如医疗上面,很多疑难杂症,全世界也没有几例,那怎么能够对这个类别搜集大数据。所以从这个意义上讲,如果我们能够找到一种方法克服对大的标注数据的需求,我们才能够使得现在的人工智能技术突破目前数据给它划定的边界,才能够深入到更多的领域里面去。第二个局限是关于模型大小以及模型训练难度的问题,前面提到了深度神经网络有很多层,而且一般参数都很大,几十亿的参数是家常便饭。面对这样的网络,至少有两个困难,一个是我们经常提到的梯度消减和梯度爆炸的问题,当深层网络有非常多层次的时候,输出层和标签之间运算出来的残差或者是损失函数,是很难有效地传递到底层去的。所以在用这种反向传播训练的时候,底层的网络参数通常不太容易被很有效的训练,表现不好。人们发明了各种各样的手段来解决它,比如加一些skip-level connection,像我们微软亚洲研究院发明的ResNet技术就是做这件事情的,还有很多各种各样的技巧。但这些其实都只是去解决问题的技巧,回过头来,原来的这个问题本身是不是必要的,是需要我们反思的。
第三个局限,我把它叫做调参黑科技,难言之隐。这件事情特别有趣,我前一段时间参加过一个论坛,一位嘉宾的一句话给我印象特别深,他说大家知道为什么现在很多公司都有深度学习实验室吗,以前没听说过有一个叫支持向量机实验室的,为什么?这是因为像SVM这样的技术训练过程非常简单,需要调节的超参数很少,基本上只要按部就班去做,得到的结果都差不多。但深度学习这件事情,如果不来点调参黑科技,就得不到想要的结果。所谓深度学习实验室,就是一批会调参的人,没有他们深度学习就没那么好用。虽然是句玩笑,但是深度学习力要调的东西确实太多了,比如说训练数据怎么来,怎么选,如果是分布式运算怎么划分,神经网络结构怎么设计,10层、100层还是1000层,各层之间如何连接,模型更新的规则是什么,学习率怎么设,如果是分布式运算各个机器运算出来的结果怎么聚合,怎么得到统一的模型,等等,太多需要调的东西,一个地方调不好,结果可能就大相径庭。这就是为什么很多论文里的结果是不能重现的,不是说论文一定不对,但至少人家没有把怎么调参告诉你,他只告诉了你模型长什么样而已。
第四个局限,叫做黑箱算法,不明就里。这不仅仅是神经网络的问题,更是统计机器学习多年来一直的顽疾,就是用一个表达能力很强的黑盒子来拟合想要研究的问题,里面参数很多。这样一个复杂的黑盒子去做拟合的时候,结果好,皆大欢喜。如果结果不好,出现了反例,该怎么解决呢,这里面几亿、几十亿个参数,是谁出了问题呢,其实是非常难排错的事情。相反,以前有很多基于逻辑推理的方法,虽然效果没有神经网络好,但是我们知道每一步是为什么做了决策,容易分析、排错。所以最近几年有一个趋势,就是把基于统计学习的方法和基于符号计算的方法进行结合,造出一个灰盒子,它既具备很强的学习能力,又能在很大程度上是可理解、可支配、可调整的。
3.本次讲座的学习感悟、思考等
1.通过本次讲座,初步了解到了机器学习,深度学习相关的知识以及一些前沿的研究方向和热点。理解到了机器学习的原理、以及与密码分析的相似之处。我发现机器学习的一切应用都是建立在现有的大数据的基础上来实现的,这些应用可以用来替代一些大量的,重复性,危险性的工作。还学习到深度学习包含有大量性能优秀的深度神经网络( DNN: Deep Neura lNetworks ),例如卷积神经网络( CNN: Convolutional Neural Networks)、循环神经网络(RNN: Recurrent Neural Networks)、生成对抗网络(GAN: Generative Adversarial Networks)等,在大数据分析、图像识别、机器翻译、视频监控中取得了较大进步。这次讲座使我受益匪浅,对机器学习、深度学习有了一个浅浅的了解,扩大了我的知识面,我以后我继续关注机器学习方面的研究,并尝试寻找兴趣点来进行学习。
2.通过查阅一些论文和资料,发现深度学习,卷积神经网络的技术可以广泛的应用到图像处理、医学检测、数据安全保护。其中图像处理,计算机视觉方面的研究最为成熟和突出。在深度学习方面图像处理最基本的方法就是基于现有的图像数据集用算法对机器不断的进行训练来达到一个相对较高的准确识别率。但是假如现有的图像数据集不包含某种事物、或者已有的事物可以组合使用等等这些问题,那么它的准确率将会直线下降。这个问题我相信可以作为深度学习的一个研究方向。
4.机器学习、深度学习最新研究现状
根据老师所讲的内容,我对机器学习、深度学习十分感兴趣,并利用学校的图书资源在IEEE上查找了一些最新的论文和资料。
- 第一篇
- 首先我找了一篇发布在 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)上的论文“Privacy Preserving Deep Computation Model on Cloud for Big Data Feature Learning”。
- Qingchen Zhang Laurence T. Yang Zhikui Chen
3.为了提高大数据特征学习的效率,本文提出了一种通过将昂贵的操作卸载到云中来保护隐私的深度计算模型。 隐私问题变得明显,因为智能城市中的各种应用程序存在大量私人数据,例如政府的敏感数据或企业的专有信息。为了保护私有数据,所提出的模型使用BGV加密方案来加密私有数据,并使用云服务器对加密数据执行高阶反向传播算法,以进行深度计算模型训练。 此外,所提出的方案将Sigmoid函数近似为多项式函数,以支持BGV加密的激活函数的安全计算。在这个的方案中,只有加密操作和解密操作由客户端执行,而所有计算任务都在云上执行。 实验结果表明,与传统的深度计算模型相比,这个方案在训练效率上提高了大约2.5倍,而没有使用包括十个节点的云计算来公开私有数据。 更重要的是,这个方案通过使用更多云服务器而具有高度可扩展性,尤其适用于大数据。为了实现隐私保护的高阶反向支持算法,需要BGV加密方案的安全操作,包括加密,解密,安全添加和安全乘法。BGV方案的实现过程如下:
![]()
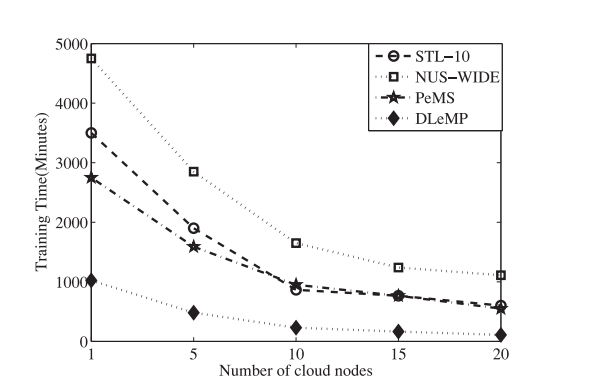
最后用不同分类数据集的性能分析图来进行证明:
![]()
实验结果表明:从图10可以看出,随着云计算平台中计算节点数量的增加,所提出的训练四个三个数据集的方案的训练时间逐渐减少,这表明添加节点可以显着提高系统容量。 特别是,对于STL-10数据集,PeMS数据集和小于NUS-WIDE数据集的DLeMP数据集,当云节点数量较多时,通过使用更多云服务器,我们提出的方案的效率会略有提高 因此,10个云节点足以用于三个训练数据集。 但是,对于NUS-WIDE数据集,当云的数量时,我们提出的方案的效率会显着提高由于我们提出的方案的性能可以通过为大数据使用更多的云服务器来进一步提高,因此我们提出的方案特别适用于大数据特征学习。

- 第二篇
- 第二篇论文我找的是发布在:: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)上的论文,论文的题目为Fully convolutional networks for semantic segmentation
- 作者信息:Jonathan Long ; Evan Shelhamer ; Trevor Darrell
3.卷积网络是一种功能强大的可视化模型,可以生成特征层次结构。我们发现卷积网络本身,训练端到端,像素到像素,超过了最先进的语义分割技术。我们的关键见解是建立“完全卷积”的网络,它接受任意大小的输入,并通过有效的推理和学习产生相应大小的输出。我们定义并详细描述了完全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并与先前的模型建立了联系。我们将当代分类网络(Alexnet[20]、vgg net[31]和googlenet[32])调整为完全卷积网络,并通过微调将其学习到的表示转移到分割任务中。然后,我们定义了一个跳过架构,它将来自深层、粗层的语义信息与来自浅层、细层的外观信息结合起来,以生成准确和详细的分段。我们的全卷积网络实现了Pascal VOC(2012年平均IU为62.2%,相对改善20%)、NYUDV2和SIFT流的最先进分割,而典型图像的推理时间不到五分之一秒。
最后的实验结果如下:
![]()
上图展现了完全卷积分割网络在PASCAL上产生最先进的性能。 左栏显示了输出我们表现最好的网络FCN-8。 第二个方法是由先前最先进的系统分割技术是作者:Hariharan等。第三列是真实的扫描。对比可以发现FNC-8S在第一、二、三张图片中可以大部分完整的展现图像的轮廓,在第四张图片中存在一定的偏差,表明完全卷积网络是一类丰富的模型,其中现代分类网络是一种特殊情况。 认识到这一点,将这些分类网络扩展到分段,并通过多分辨率层组合改进架构,大大提高了现有技术的水平,同时简化了加快学习和推理。

- 第三篇
- 第三篇论文我找的是发布在IEEE Transactions on Medical Imaging ( Volume: 35 , Issue: 5 , May 2016 )*上的论文,论文题目为Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning**。
- 作者信息:Hoo-Chang Shin ; Holger R. Roth ; Mingchen Gao ; Le Lu ; Ziyue Xu ; Isabella Nogues ;
- 本文的研究背景是在图像识别方面取得了显着进展,主要是由于大规模注释数据集和深度卷积神经网络(CNN)的可用性。 CNN使得能够从足够的训练数据中学习数据驱动的,高度代表性的分层图像特征。然而,获得在医学成像领域中作为ImageNet全面注释的数据集仍然是一个挑战。目前有三种主要技术成功地将CNN应用于医学图像分类:使用现成的预先训练的CNN特征从头开始训练CNN,以及通过监督微调进行无监督的CNN预训练。另一种有效的方法是转移学习,即将从自然图像数据集预训练的CNN模型微调到医学图像任务。
4.本文主要研究了利用三个重要但以前未充分考虑的因素,即将深度卷积神经网络用于计算机辅助检测问题。首先探索和评估不同的CNN架构。研究的模型包含5千万到1亿6千万个参数,并且层数不同。然后,评估数据集规模和空间图像上下文对性能的影响。最后,研究何时以及为什么从预先训练的ImageNet(通过微调)转移学习可能是有用的。本文还研究了两种特定的计算机辅助检测(CADe)问题,即胸腹淋巴结(LN)检测和间质性肺病(ILD)分类。在纵隔LN检测上实现了最先进的性能,并报告和预测了具有ILD类别的轴向CT切片的前五次交叉验证的分类结果。本文广泛的实证评估,CNN模型分析和有价值的见解可以扩展到用于其他医学成像任务的高性能CAD系统的设计。
- 第四篇
- 这是一篇发布在IEEE Transactions on Image Processing ( Volume: 24 , Issue: 12 , Dec. 2015 )的论文,论文题目为PCANet: A Simple Deep Learning Baseline for Image Classification?-
- 作者信息如下:Tsung-Han Chan ; Kui Jia ; Shenghua Gao ; Jiwen Lu ; Zinan Zeng ; Yi Ma
3在本文中,提出了一个非常简单的图像分类深度学习网络,它基于非常基本的数据处理组件:1)级联主成分分析(PCA); 2)二进制散列; 3)块状直方图。在所提出的架构中,PCA用于学习多级滤波器组。接下来是简单的二进制散列和块直方图,用于索引和汇集。因此,该架构称为PCA网络(PCANet),可以非常容易和有效地设计和学习。为了进行比较并提供更好的理解,其次还介绍和研究了PCANet的两个简单变体:1)RandNet和2)LDANet。它们与PCANet具有相同的拓扑结构,但它们的级联滤波器可以随机选择,也可以从线性判别分析中学习。本文已经针对不同的任务在许多基准视觉数据集上广泛测试了这些基本网络,包括用于面部验证的野外标记面(LFW);用于人脸识别的MultiPIE,扩展耶鲁B、AR,面部识别技术(FERET)的数据集;和MNIST用于手写数字识别的数据集。令人惊讶的是,对于所有任务而言,这种看似简单的PCANet模型与先进的,高度手工制作的或通过深度神经网络(DNN)精心学习的最先进的功能相提并论。更令人惊讶的是,该模型为扩展耶鲁B、AR和FERET数据集以及MNIST变体上的许多分类任务设置了新记录。其他公共数据集的其他实验也证明了PCANet作为纹理分类和对象识别的简单但高度竞争的基线的潜力。
4.实验的结果表明:虽然本文研究简单PCANet架构的初衷是获得一个简单的基线来比较和证明其他更先进的深度学习组件或架构,但本文的研究结果会带来各种令人愉快但发人深思的惊喜:非常基本的PCANet,在公平实验比较,几乎所有的图像分类任务,包括面部图像,手写数字,已经与最先进的功能(前缀,手工制作,或从DNN学习)相当,并且往往更好。纹理图像和对象图像。更具体地,对于每人具有一个图库图像的面部识别,该模型在扩展的耶鲁B数据集上实现99.58%的准确度,并且在AR数据集中的伪装/照明子集上实现大于95%的准确度。在FERET数据集上,该模型获得了97.25%的最新平均精度,并且在Dup-1和Dup-2子集上分别达到了95.84和94.02%的最佳精度.1在LFW数据集上,该模型在“无监督设置”下实现了86.28%的有效面部验证。在MNIST数据集上,该模型实现了基础,背景随机和背景图像等子任务的最新结果;有关详细信息,请参见第III节和第IV节。压倒性的经验证据证明了所提出的PCANet在学习各种图像分类任务的鲁棒不变特征方面的有效性
- 第五篇
- 这是一篇发布在2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)上的论文,论文的题目为Going Deeper with Convolutions
- 作者信息:Christian Szegedy ; Wei Liu ; Yangqing Jia ; Pierre Sermanet ; Scott Reed ; Dragomir Anguelov
3.本文提出了一种深度卷积神经网络架构,代号为Inception,在2014年ImageNet大规模视觉识别挑战赛(ILSVRC14)中实现了分类和检测的最新技术水平。 该体系结构的主要标志是提高了网络内计算资源的利用率。 通过精心设计,本文增加了网络的深度和宽度,同时保持计算预算不变。 为了优化质量,架构决策基于Hebbian原则和多尺度处理的直觉。 本文在提交的ILSVRC14中使用的一个特定化身称为GoogLeNet,一个22层深的网络,其质量在分类和检测的背景下进行评估。
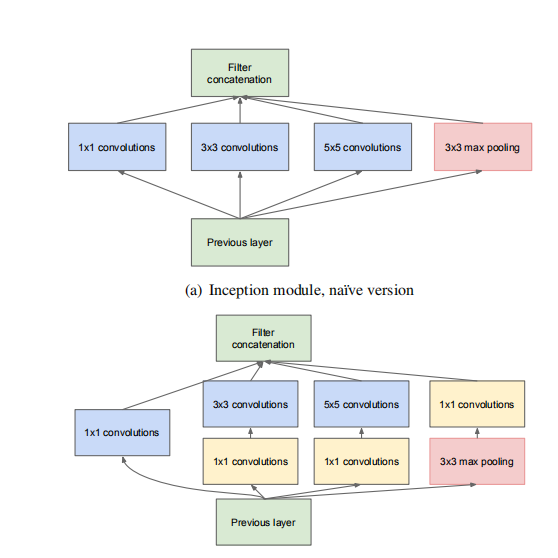
4.本文的卷积神经网络的架构:初始架构的主要思想是考虑如何通过容易获得的密集组件来近似和覆盖卷积网络的最优局部稀疏结构。请注意,假设平移不变性意味着我们的网络将基于构造构建块构建。我们所需要的只是找到最佳的局部结构并在空间上重复它。 Arora等人建议采用逐层构造,其中应该对最后一层的相关统计进行分析,并将它们聚类成具有高相关性的单元组。这些聚类形成下一层的单元,并连接到前一层中的单元。我们假设来自较早层的每个单元对应于输入图像的某个区域,并且这些单元被分组为滤波器组。在较低层(靠近输入的那些层)中,相关单元将集中在局部区域中。因此,我们最终将大量聚类集中在一个区域中,并且如下[12]中所建议的,它们可以在下一层中被一层1×1卷绕覆盖。然而,人们还可以预期会有更少数量的空间扩散的聚类,可以通过更大的补丁上的卷积来覆盖,并且在越来越大的区域上将有越来越少的补丁。为了避免贴片对齐问题,Inception架构的当前版本仅限于1×1,3×3和5×5的滤波器尺寸;这个决定更多地基于方便而不是必要性。这也意味着建议的体系结构是所有这些层的组合,其输出滤波器组连接成单个输出向量,形成下一级的输入。此外,由于汇集操作对于当前网络连接的成功至关重要,因此它建议在每个这样的阶段添加一个替代的,平行的汇集路径应该有额外的有益效果(见图2(a))
![]()
除此之外,Inception架构还有第二个想法:除非计算要求增加太多,否则明智地减少尺寸。 这是基于嵌入的成功:即使是低深度嵌入也可能包含大量关于相对较大的图像补丁的信息。 但是,嵌入式表示密集,压缩形式的信息,压缩信息难以处理。 代表应在大多数地方保持稀疏(根据[2]的条件要求)并仅压缩信号每当他们必须集体聚集。 也就是说,在昂贵的3X3和5X5卷积之前,使用1X1个卷积来计算减少量。 除了用作减少之外,它们还包括使用矫正耳激活使它们成为双重用途。 最终结果如图2(b)所示
参考资料
- Privacy Preserving Deep Computation Model on Cloud for Big Data Feature Learning
- Fully convolutional networks for semantic segmentation
- Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning
- PCANet: A Simple Deep Learning Baseline for Image Classification?
- Monitoring and physical-layer attack mitigation in SDN-controlled quantum key distribution networks

 浙公网安备 33010602011771号
浙公网安备 33010602011771号