NLP&Python笔记——nltk模块基础操作
nltk是一款常用的基于python的NLP工具包,本文介绍了nlkt的安装导入以及一些基础的函数操作。
1. 安装
(1)安装nltk库: pip install nlkt
(2)下载nltk库中的book文件:
import nltk
nltk.download()运行--> 弹出下载界面 --> 选择book--> 设置好路径--> Download
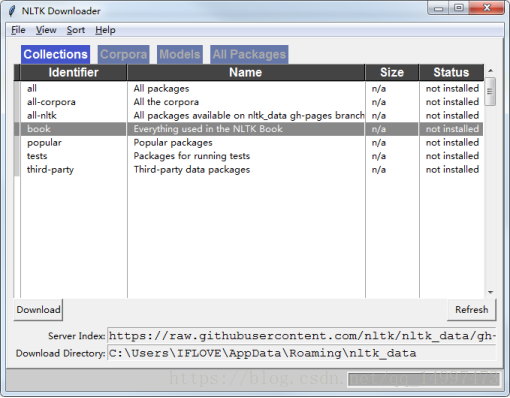
(3)下载好后,加载nltk的book模块中所有条目:
from nltk.book import *(4)加载后,就可以使用库中包含的文档了。如,text1/tex2/tex3.....
2. 几个基础函数
(1)搜索文本:text.concordance(word)
例如,在text1中搜索词”is”在文本中出现的次数以及上下文的词:text1.concordance("is")

(2)搜索上下文相似的词:text.similar(word)
例如,在text1中搜索哪些相似的词出现在词”is”的上下文中:text1.similar("is")
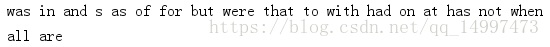
(3)搜索几个词汇上下文的公共词汇:text.common_contexts([word1,word2…])
例如,在text1中搜索哪些词是”is”和“that”上下文中的公共词汇:text1.common_contexts(["is","that"])

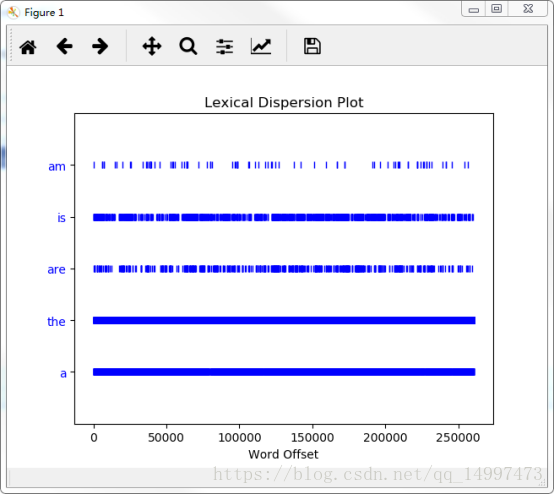
(4)离散图表示词出现的位置序列:text.dispersion_plot([word1, word2,])
例如,用离散图表示词"am","is","are","the","a"在text1中出现的位置,即从开头算起的第多少个词:text1.dispersion_plot(["am","is","are","the","a"])
(5)统计文本标示符(单词和标点符号)的个数:len(text)
(6)获取文本的词汇表(含标点符号):set(text)
(7)获取词汇表并排序:sorted(set(text))
(8)统计词汇表的大小:len(set(text))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号