C++ 面试题(施工中...)
作用域解析运算符(scope resolution operator)::
在C++中,双冒号 :: 被称为范围解析运算符或者域解析运算符。它有以下几个主要用途:
-
命名空间作用域:当一个标识符(如函数、变量或类)被定义在某个命名空间内时,使用
::可以明确指出该标识符属于哪个命名空间。例如,std::cout表示cout是标准命名空间std中的一个对象。namespace MyNamespace { void myFunction() { // 函数实现 } } // 调用命名空间内的函数 MyNamespace::myFunction(); -
全局作用域:在类的内部,如果想要引用全局作用域中的同名变量或函数,需要使用
::来指定全局作用域。这样可以避免与类内的同名成员发生冲突。int globalVar = 10; class MyClass { public: int localVar = 5; void showVar() { // 显示全局变量globalVar的值 std::cout << "::globalVar = " << ::globalVar << ", this->localVar = " << localVar << std::endl; } }; -
静态成员访问:在类的外部,如果要访问静态成员变量或静态成员函数,可以直接使用
::运算符结合类名来访问,而不需要实例化对象。class MyClass { public: static int staticVar; static void staticFunc() { // 函数实现 } }; int MyClass::staticVar = 20; // 正确地初始化静态成员变量 // 调用静态成员函数 MyClass::staticFunc(); -
基类访问:在派生类中,使用
baseClass::function()或baseClass::variable可以明确地访问基类的成员,尤其是在派生类中重写了基类的成员函数时。class Base { public: virtual void print() { std::cout << "Base" << std::endl; } }; class Derived : public Base { public: void print() override { std::cout << "Derived" << std::endl; // 明确调用基类的print函数 Base::print(); } };
综上所述,:: 运算符在C++中非常重要,它帮助区分不同作用域中的标识符,使得代码的意图更加清晰,同时支持跨作用域的访问。
C++中单例模式为什么设置成静态的
在C++中,单例模式通常被实现为静态的,主要出于以下几个原因:
- 全局访问:静态成员变量和函数在全局范围内都是可见的,这意味着无论你在代码的哪个位置,都可以直接通过类名来访问它们。这对于单例模式来说非常重要,因为单例模式的目的是确保一个类只有一个实例,并提供一个全局访问点。
- 生命周期:静态成员变量在程序的生命周期内只会被初始化一次,这符合单例模式的要求,即在整个程序运行期间,单例类只应该有一个实例。
- 线程安全:如果你使用静态本地变量来实现单例(这种方法称为“Meyers' Singleton”),则可以利用C++的静态本地变量的初始化特性,确保在多线程环境下仍然是线程安全的。这是因为静态本地变量的初始化是懒加载的,并且由编译器保证在多线程环境下是线程安全的。
- 简化实现:静态成员变量和函数使得单例模式的实现更加简洁。你可以直接在类定义中声明一个静态成员变量来保存单例实例,并通过一个静态成员函数来获取这个实例。
下面是一个简单的C++单例模式的实现示例:
class Singleton {
private:
static Singleton* instance_;
Singleton() {}
~Singleton() {}
public:
static Singleton* getInstance() {
if (instance_ == nullptr) {
instance_ = new Singleton();
}
return instance_;
}
// 其他成员函数和变量...
};
Singleton* Singleton::instance_ = nullptr;
在这个示例中,instance_是一个静态成员变量,用于保存单例实例。getInstance()是一个静态成员函数,用于获取单例实例。由于instance_是静态的,它会在整个程序运行期间只被初始化一次,并确保只有一个实例。
C++中 子类可以重写父类中的非虚函数吗
在C++中,子类不能直接“重写”父类中的非虚函数。重写(override)是面向对象编程中的一个概念,它指的是子类可以提供一个与父类中虚函数(virtual function)签名相同的函数。当子类对象调用这个函数时,会执行子类中的实现,而不是父类中的实现。
如果父类中的函数不是虚函数,那么子类中的同名函数并不会重写父类的函数,而是会隐藏(hide)父类的函数。这意味着如果通过子类的指针或引用来调用这个函数,将会调用子类中的实现;而如果通过父类的指针或引用来调用,将会调用父类中的实现。
下面是一个展示子类隐藏父类非虚函数的例子:
#include <iostream>
// 父类
class Parent {
public:
void function() {
std::cout << "这是父类的非虚函数!" << std::endl;
}
};
// 子类
class Child : public Parent {
public:
void function() {
std::cout << "这是子类的函数,它隐藏了父类的非虚函数!" << std::endl;
}
};
int main() {
Parent* parentPtr = new Child();
// 通过父类指针调用,将会调用父类的函数
parentPtr->function(); // 输出 "这是父类的非虚函数!"
Child* childPtr = new Child();
// 通过子类指针调用,将会调用子类的函数
childPtr->function(); // 输出 "这是子类的函数,它隐藏了父类的非虚函数!"
delete parentPtr;
delete childPtr;
return 0;
}
在这个例子中,Child 类提供了一个与 Parent 类中同名的非虚函数 function。当我们通过 Parent 类型的指针来调用这个函数时,它调用的是 Parent 类中的实现;而当我们通过 Child 类型的指针来调用时,它调用的是 Child 类中的实现。
通常,如果你想让子类能够重写父类的函数,并且无论是通过父类还是子类的指针或引用来调用都执行子类的实现,你应该将父类中的函数声明为虚函数。
C++中static变量的加载时机
在C++中,静态变量的加载时机取决于它们在代码中的声明位置和作用域。
- 全局静态变量:全局静态变量在程序开始执行时被加载,并且只被加载一次。这意味着无论程序运行多少次,全局静态变量都只会被初始化一次。
- 局部静态变量:局部静态变量在它们所在的函数被调用时被加载,并且只被加载一次。与全局静态变量类似,局部静态变量也只会被初始化一次。
需要注意的是,静态变量的初始化顺序与它们的声明顺序有关,而不是它们在代码中的出现顺序。因此,如果一个静态变量依赖于另一个静态变量,那么初始化顺序可能会成为一个问题。在这种情况下,可以使用静态初始化器(static initializer)来确保正确的初始化顺序。
另外,C++11引入了线程安全的静态局部变量的概念,即thread_local关键字。thread_local变量在每个线程中都有自己的存储空间,并且只在该线程中被初始化一次。每个线程都可以修改自己的thread_local变量副本,而不会影响其他线程的副本。thread_local变量的加载时机与它们所在的线程相关,而不是与全局或局部静态变量的加载时机相同。
C++11中静态变量和静态初始化器的作用域是什么
在C++11中,静态变量的作用域是它们所在的代码块或文件。具体来说,全局静态变量的作用域是整个程序,而局部静态变量的作用域是它们所在的函数或代码块。静态变量在声明它们的块或文件的作用域内是可见的,并且它们在程序的生命周期内一直存在。
静态初始化器(static initializer)用于初始化静态变量。静态初始化器的执行时机是在静态变量初始化之前。它们的作用域是包含静态变量的代码块或文件。静态初始化器是在全局范围内执行的,而不是在它们所在的函数或代码块中执行。这意味着无论包含静态变量的函数或代码块是否被调用,静态初始化器都会被执行。
需要注意的是,静态变量的初始化顺序与其声明的顺序有关,而不是与其在代码中的出现顺序有关。因此,如果一个静态变量依赖于另一个静态变量,那么初始化顺序可能会成为一个问题。在这种情况下,可以使用静态初始化器来确保正确的初始化顺序。
在C++中,当类被加载到内存时,以下类型的变量会被构建
在C++中,当类被加载到内存时,以下类型的变量会被构建:
- 全局变量:全局变量是在程序范围内可见的变量,它们在类装载时被初始化。
- 静态成员变量:静态成员变量属于类而不是类的特定实例,因此它们在类装载时只会被初始化一次。
- 静态局部变量:静态局部变量在函数或代码块中声明,并且只在该函数或代码块被调用时才会被初始化。
需要注意的是,C++中的类加载时机取决于类的使用方式。如果一个类被引用(例如,通过指针或引用),则该类会被加载。如果一个类从未被引用,则它可能永远不会被加载,从而节省内存空间。此外,类的加载时机还可能受到操作系统和编译器的特定行为的影响。
C++中 i++和++i的区别
在C++中,i++和++i之间有很大的区别。在前缀版本(即++i)中,i的值会被递增,表达式的值是i的新值。而在后缀版本(即i++)中,i的值也会被递增,但表达式的值是i的原始值。换句话说,i++先给表达式赋值,然后再递增变量;而++i先递增变量,然后再返回表达式的值。
下面是一个示例代码,以便更好地理解:
#include <iostream>
using namespace std;
int main() {
int x = 3, y, z;
y = x++;
z = ++x;
cout << x << ", " << y << ", " << z;
return 0;
}
这段代码的输出是:5, 3, 5。为什么会这样呢?让我们详细看一下:
- 将x初始化为3
- 将y赋值为x++表达式的值,即递增前的x的值,然后再递增x
- 递增x,然后将z赋值为++x表达式的值,即递增后的x的值
- 打印这些值
希望这能帮助你理解++i和i++之间的区别。
C++多态虚函数表内存布局
假设有一个基类Base,一个继承了该基类的派生类Derived,并且基类中有虚函数,派生类实现了基类的虚函数。
我们在代码中运用多态这个特性时,通常以两种方式起手:
class Base {
};
class Derived : public Base {
};
// (1) 分配在堆上
Base* a = new Derived();
// (2) 分配在栈上
Derived b;
Base* a = &b;
以上两种方式都是用基类指针去指向一个派生类实例,区别在于第1个用了new关键字而分配在堆上,第2个分配在栈上。
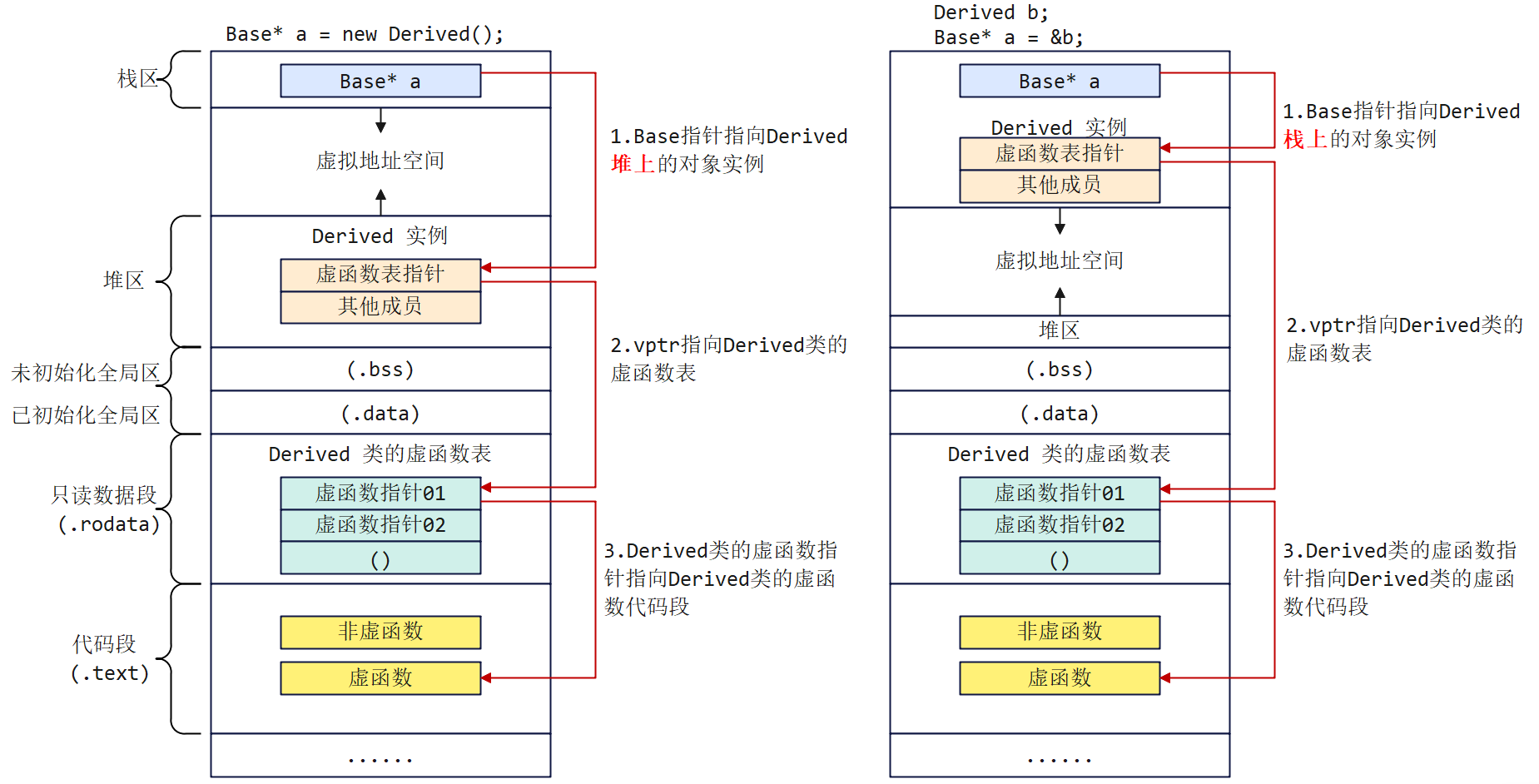
请看上图,不同两种方式起手仅仅影响了派生类对象实例存在的位置。
以左图为例,Base* a是一个栈上的指针,该指针指向一个在堆上实例化的子类对象。基类如果存在虚函数,那么在子类对象中,除了成员函数与成员变量外,编译器会自动生成一个指向该类的虚函数表(这里是类Derived)的指针,叫作虚函数表指针。通过虚函数表指针,父类指针即可调用该虚函数表中所有的虚函数。
构造函数不能声明为虚函数
在C++中,构造函数不能声明为虚函数。这是因为在执行类的构造函数时,内存中还没有虚表,也就是还没有定义虚指针。因此,构造函数必须始终是非虚的。这是C++语言设计的一部分,以确保在对象构造期间能够正确地初始化虚函数表和虚指针。因此,构造函数不能声明为虚函数。
但是,C++中可以有虚析构函数。以下是一个示例代码:
#include<iostream>
using namespace std;
class Base {
public:
Base() {
cout << "Constructing base \n";
}
virtual ~Base() {
cout << "Destructing base \n";
}
};
class Derived : public Base {
public:
Derived() {
cout << "Constructing derived \n";
}
~Derived() {
cout << "Destructing derived \n";
}
};
int main(void) {
Derived *derived = new Derived();
Base *bptr = derived;
delete bptr;
return 0;
}
输出结果为:
Constructing base
Constructing derived
Destructing derived
Destructing base
这个例子展示了虚析构函数的用法。
虚函数表是如何在C++中被初始化的?
在C++中,虚函数表(vtable)是在对象的构造期间被初始化的。虚函数表是一个存储类的虚函数指针的数组,用于实现多态性。在对象构造期间,虚函数表会被填充为指向正确的虚函数的指针。
具体来说,虚函数表是在执行类的构造函数期间被初始化的。在构造函数执行期间,会为对象分配内存并初始化虚函数表。这确保了在对象构造期间能够正确地设置虚函数表和虚指针,以便在运行时进行正确的多态调用。
以下是一个示例代码,展示了虚函数表是如何在C++中被初始化的:
#include <iostream>
using namespace std;
class Base {
public:
virtual void func() {
cout << "Base::func()" << endl;
}
};
class Derived : public Base {
public:
void func() override {
cout << "Derived::func()" << endl;
}
};
int main() {
Base* basePtr = new Derived();
basePtr->func(); // 输出 "Derived::func()"
delete basePtr;
return 0;
}
在这个示例中,Base 类和 Derived 类都有一个虚函数 func。在 main 函数中,我们创建了一个 Derived 类的对象,并将其赋值给 Base 类的指针。当调用 basePtr->func() 时,会根据虚函数表中的指针调用 Derived::func(),实现了多态性。
虚函数表和虚函数指针在内存中的具体存储方式是什么?
- 虚函数表(vtable)和虚函数指针在内存中的具体存储方式是这样的:虚函数表是一个指针数组,存储了该类的虚函数的地址。
- 每个类有一个虚函数表,其中存储了该类的虚函数的地址。
- 而虚函数指针是一个指向虚函数表的指针,它存储了虚函数表的地址。
- 当调用一个虚函数时,实际上是通过虚函数指针找到对应的虚函数表,再从虚函数表中找到对应的虚函数地址进行调用。
这样的设计实现了多态性,使得在运行时能够正确地调用对象的实际类型的虚函数。
虚函数表和虚函数指针在内存中的存储方式对性能有何影响?
虚函数表和虚函数指针在内存中的存储方式会对性能产生一定影响。在C++中,虚函数表和虚函数指针是实现多态性的关键。它们的存储方式会影响程序的运行效率和内存占用。
具体影响包括:
-
内存占用:虚函数表和虚函数指针会占用额外的内存空间,每个对象都需要存储虚函数指针,而每个类都需要存储虚函数表。这会增加程序的内存占用。
-
性能开销:虚函数调用需要通过虚函数指针和虚函数表进行间接访问,这会引入额外的性能开销。相比于非虚函数调用,虚函数调用可能会更耗时。
-
缓存效率:虚函数表和虚函数指针的存储方式可能会影响CPU缓存的效率。由于虚函数表和虚函数指针存储在内存中,对于大型的类层次结构,可能会导致缓存未命中,从而影响程序的性能。
总的来说,虚函数表和虚函数指针的存储方式会对程序的性能产生一定的影响,特别是在对性能要求较高的场景下,需要谨慎设计类的继承结构和虚函数的使用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)