

0.PTA得分截图

1.本周学习总结(0-4分)
1.1 总结线性表内容
数据结构:
- 定义:相对之前存在一种或多种特定关系的数据元素的集合
- 内容:
- 数据的逻辑结构
- 定义:数据的逻辑结构在计算机中的表示,也就是将数据结构转化为计算机能够存储的结构。
- 包括:顺序存储(数组)和链式存储(链表)
- 数据的存储结构
- 定义:描述数据元素之间的逻辑关系。
- 包括:
- 集合结构:各个元素之间一般没有明显的逻辑关系。
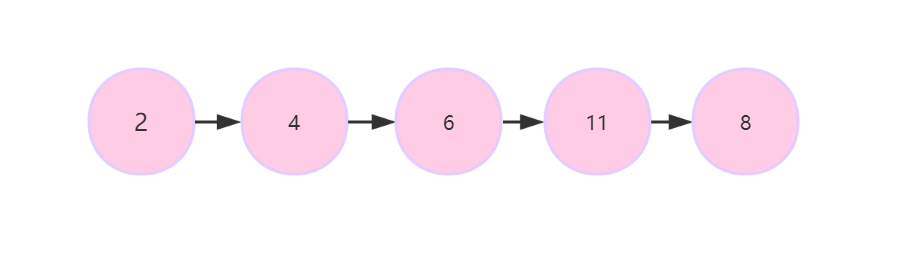
如: - 线性结构:节点之间有一一对应的关系。
如:
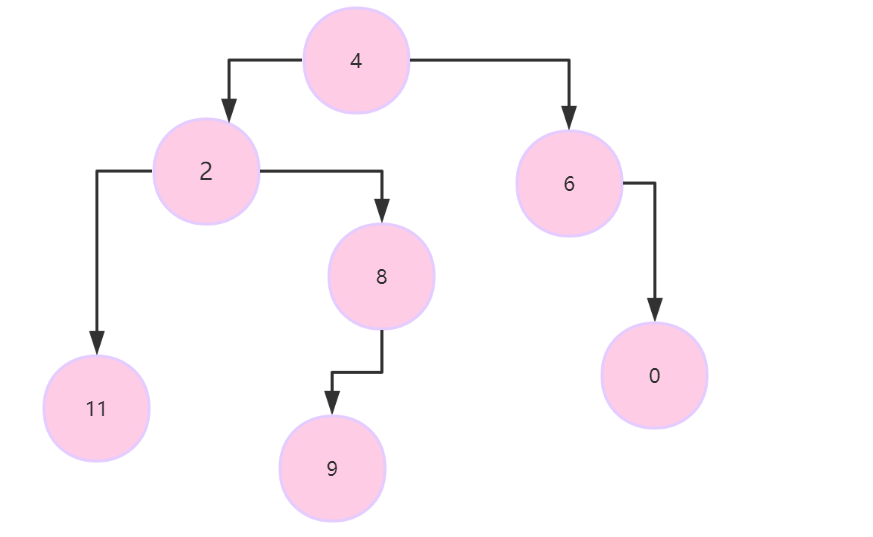
- 树形结构:节点之间有一对多的关系。
如:
- 图形结构:节点之间有多对多的关系。
如:

- 集合结构:各个元素之间一般没有明显的逻辑关系。
- 数据的操作:是施加在数据上的操作,如:插入、删除、更改等。
- 数据的逻辑结构
- 新增:bool类型
- bool用作逻辑判断,取值false和true,0为false,非0为true。支持C++语法,C中不能直接使用。
- 在C中如果非要用,可以这么写:
typedef enum {false, true} bool;
算法:
- 定义:对特定问题求解步骤的一种描述。
- 特征:
- 可行性:能在计算机上执行
- 确定性:每个解题步骤无歧义
- 有穷性:有限步骤解决问题
- 输入:一般需要输入数据
- 输出:至少有一个输出告诉结果
- 算法的评价:(正确性、可读性、健壮性、时间效率高和存储量低)
- 时间复杂度:用于描述算法的运行时间
- 空间复杂度:是对一个算法在运行过程中临时占用存储空间大小的量度
顺序表
- 结构体定义
typedef int ElemType;
typedef struct
{
ElemType data[MaxSize];//存放顺序表元素
int length ;//存放顺序表的长度
} List;
typedef List *SqList;
- 销毁顺序表
void DestroyList(SqList &L)
{
delete L;
}
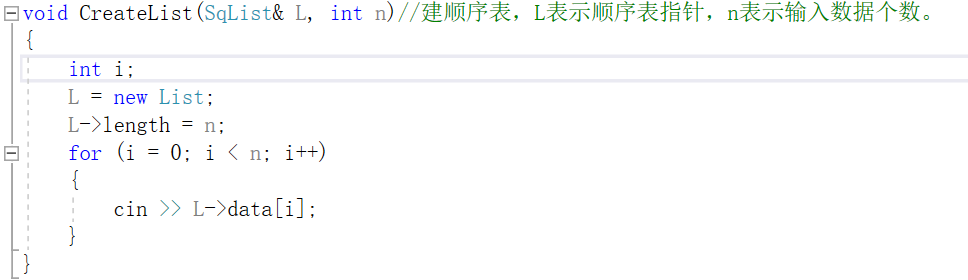
-
建顺序表
-
输出
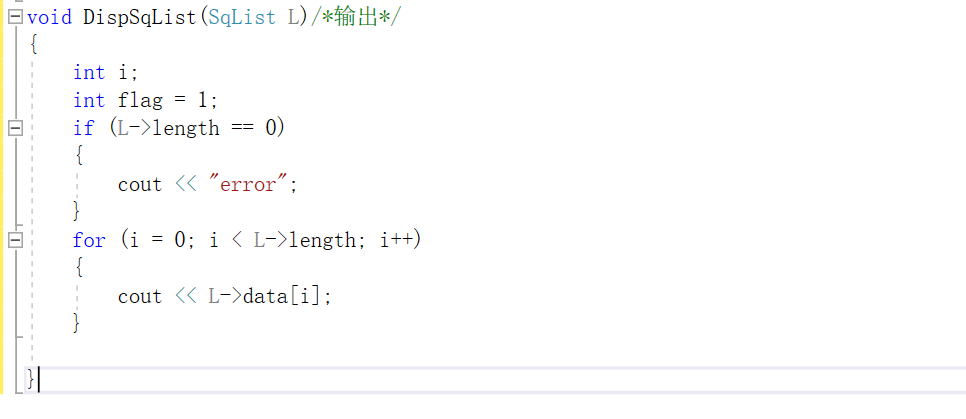
-
删除
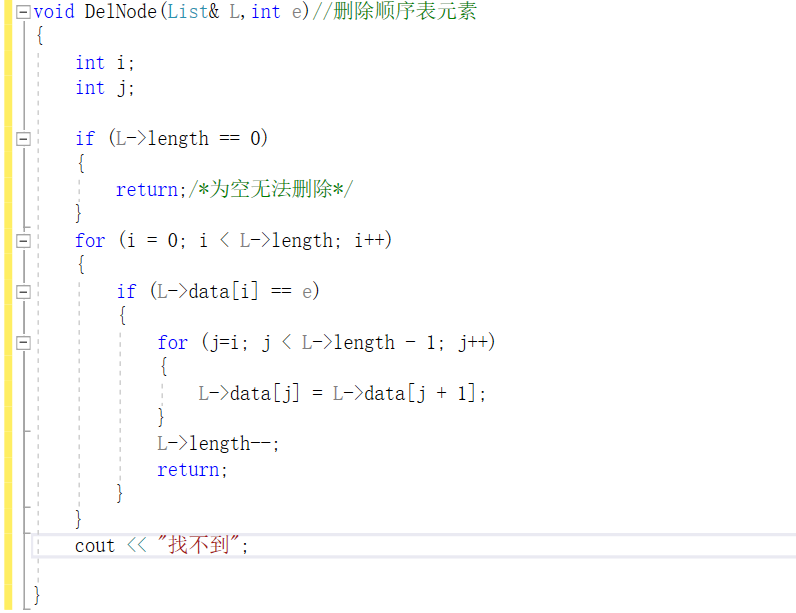
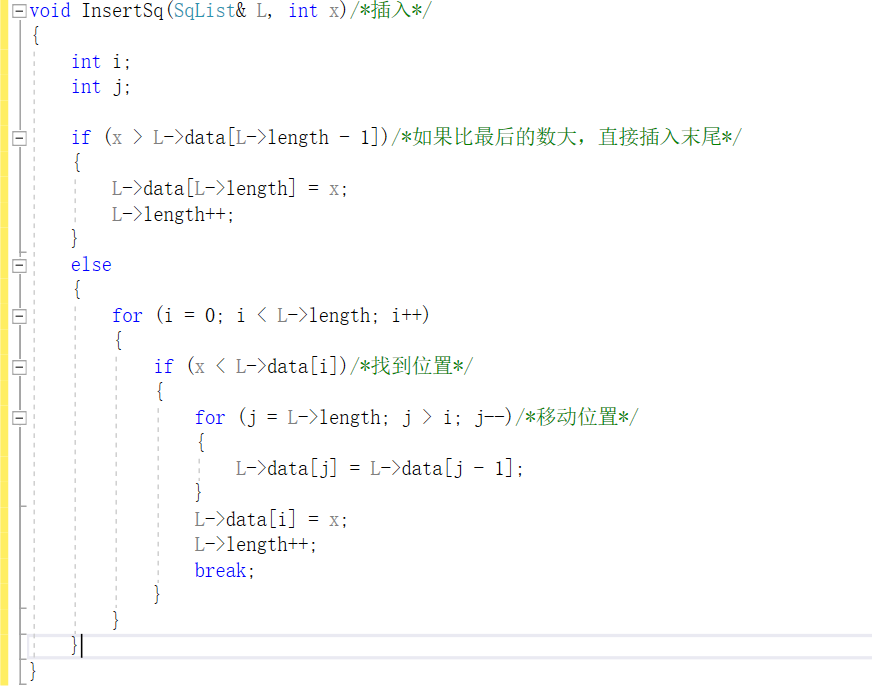
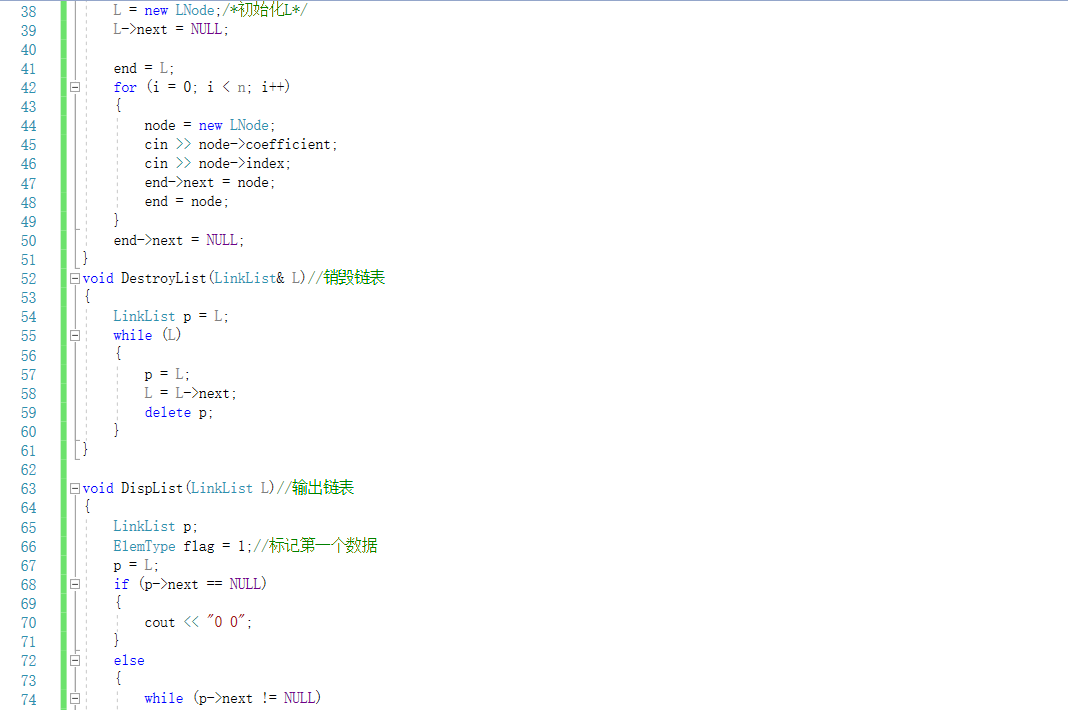
单链表
- 结构体定义
typedef int ElemType;
typedef struct LNode//定义单链表结点类型
{
ElemType data;
struct LNode *next;//指向后继结点
} LNode,*LinkList;
-
销毁
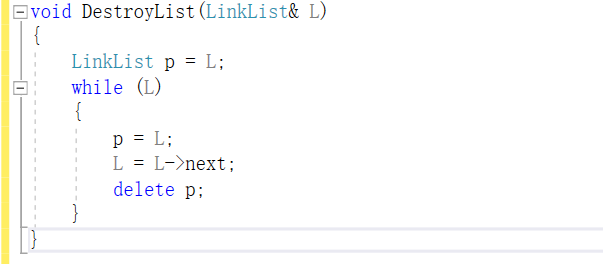
-
输出
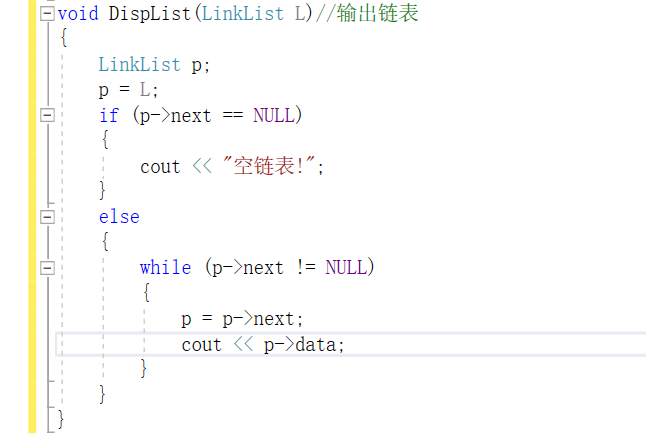
-
头插法
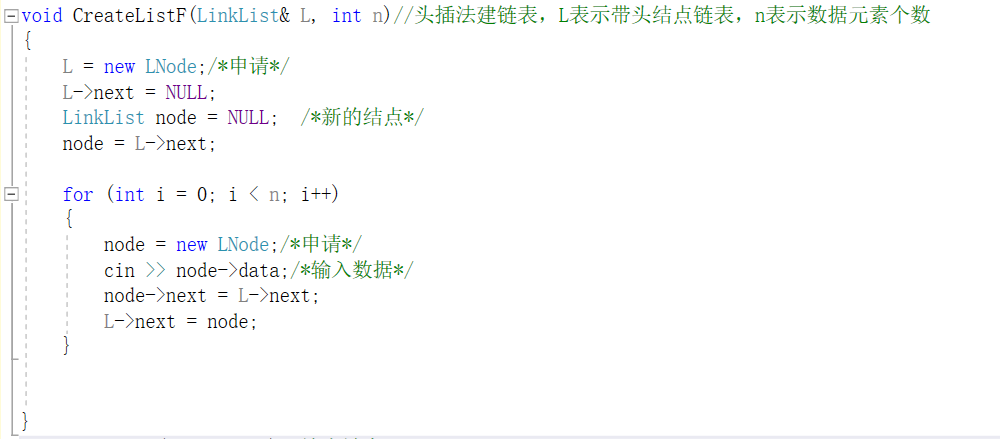
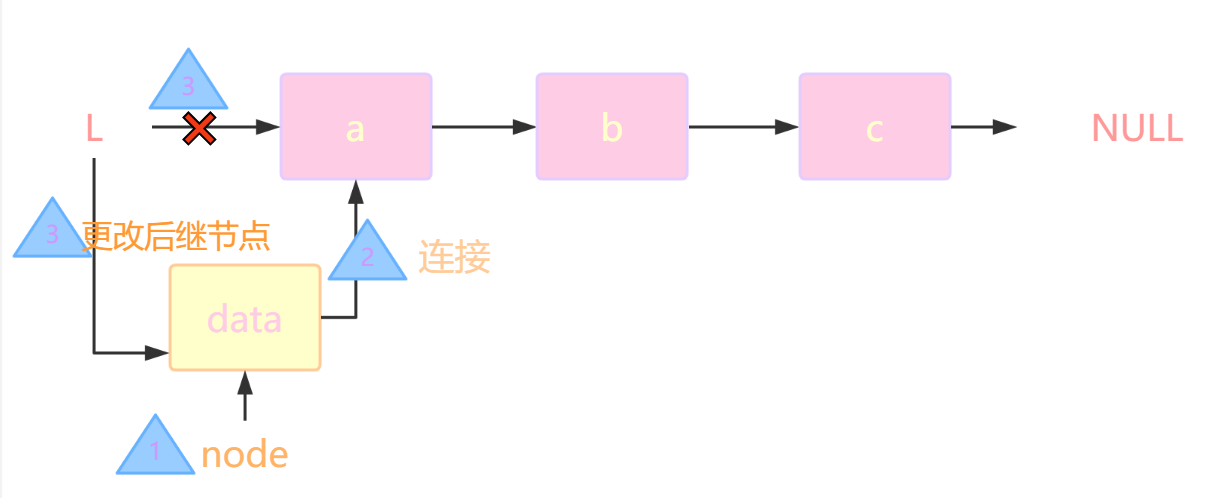
-
尾插法
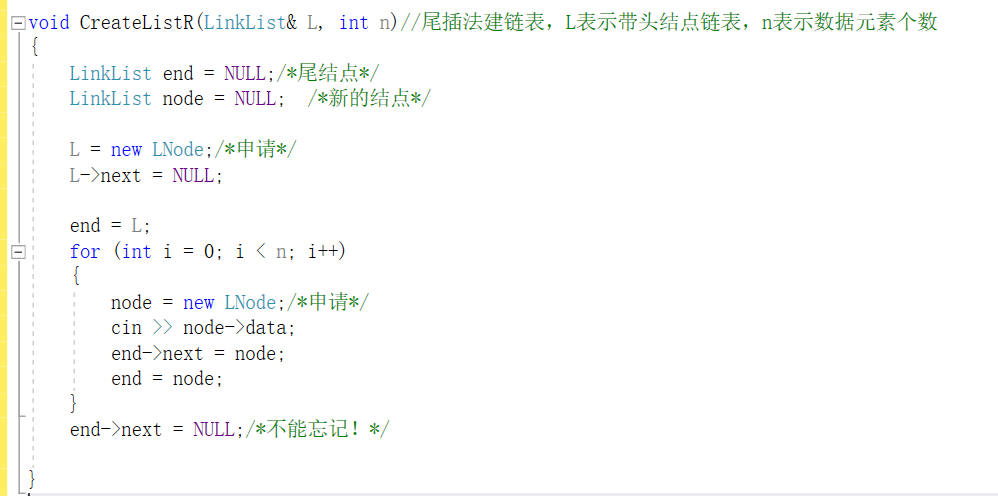

-
链表插入
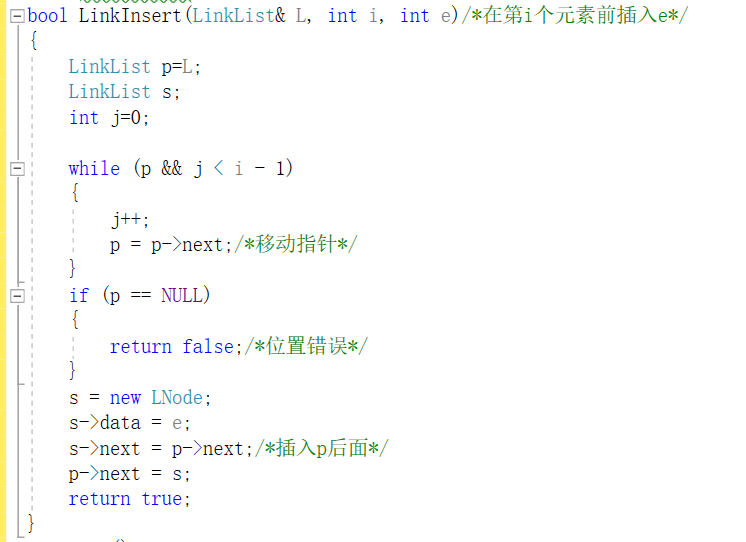

-
删除
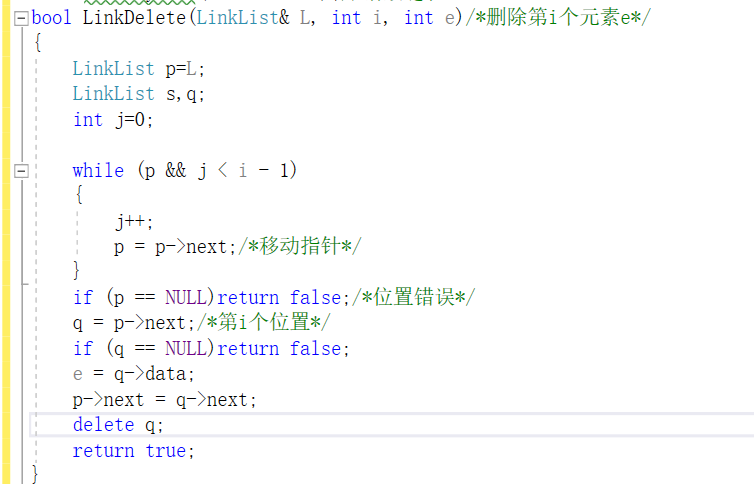
(别问为什么没图了,问就是画不动了)
有序表的操作
-
插入

-
删除
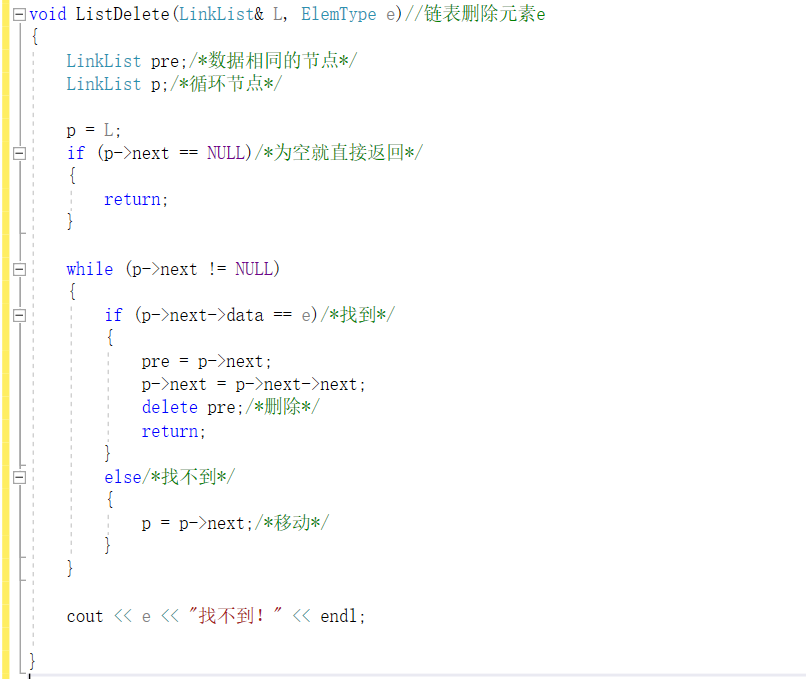
-
有序表合并
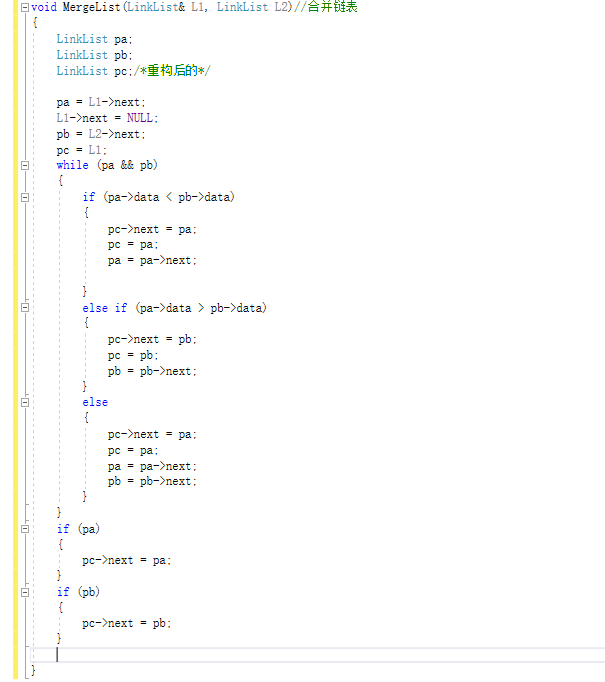
循环链表
- 定义:循环链表是另一种形式的链式存贮结构。它的特点是表中最后一个结点的指针域指向头结点,整个链表形成一个环。
- 循环单链表与单链表的区别:
- 从循环链表中的任何一个节点的位置都可以找到其他所以节点,而单链表做不到。
- 循环链表中没有明显的尾端。单链表的循环结束条件是
p->next!=NULL(带头结点) ,p!=NULL(不带头结点) 。循环单链表的循环结束条件是p->next!=L(带头结点) ,p!=L(不带头结点) 。
- 循环双链表与双链表的区别:
- 循环双链表中没有空指针域。
- 循环双链表中,p所指节点为尾结点的条件是
p->next==L. - 循环双链表中,只需一步操作
L->prior可以找到尾结点。
双链表
- 每个节点有两个指针域,一个指向前驱节点,一个指向后继节点。
- 类型定义:
typedef struct DNode//声明双链表结构类型
{
ElemType deta;
struct DNode* peior;//指向前驱节点
struct DNode* next;//指向后继节点
}DLinkList;
- 优点:
- 从任一节点出发可以访问其它节点。
- 从任一节点出发可以快速找到其前驱节点和后继节点。
1.2.谈谈你对线性表的认识及学习体会。
- 学习线性表,主要是分顺序表和单链表。顺序表稍微好一些,它其实就类似我们之前学过的数组,数组的话,因为做过的题比较多,特别是因为我上学期的课设就是用数组做的,所以两者比较起来,我对于顺序表的掌握度稍微要好一些。但是对于单链表来说,目前还不是很熟练,容易出现非法访问,偶尔会忘记考虑是否为空的情况。最直观的感受,是读代码的时候,它需要我画图,当然,这可能与我对代码的运用能力有一些关系,虽然大部分能读懂,但是花费的时间会比较多。我个人认为,写代码的时候最好在旁边加上适当的注释,不然后期改代码的时候,还需要重新理解之前写的代码,我指的是,代码比较长且很可能隔天还需要改的情况。(这周,我就有一题,写了一天,从下午写完,改代码到第二天晚上😳)原先我觉着链表不是很好用,后继节点换来换去,很容易乱,(虽然现在有时候也有点)这段时间用的多了,就觉着,其实也还好,各有各的好处吧。
2.PTA实验作业(0-2分)
2.1.6-10 jmu-ds-有序链表的插入删除
2.1.1代码截图
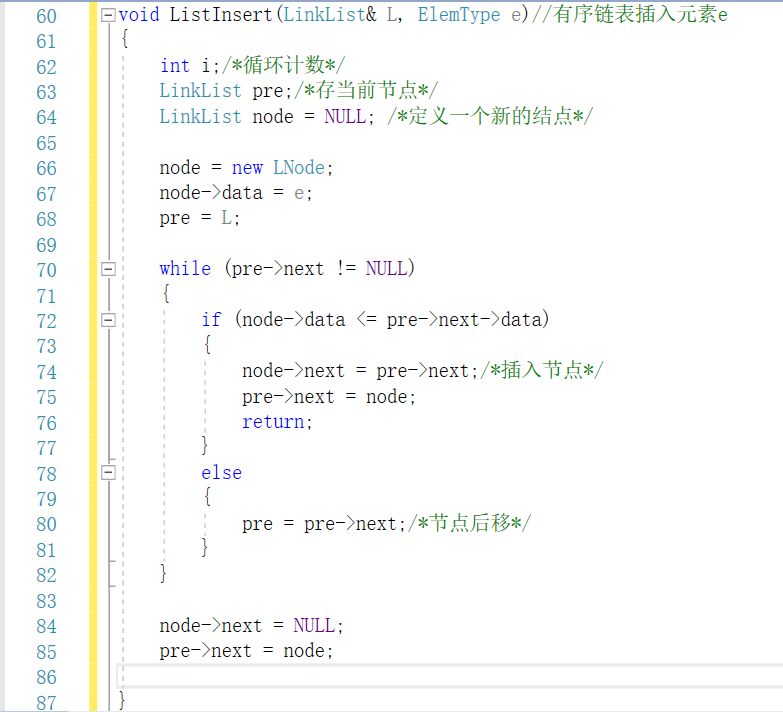
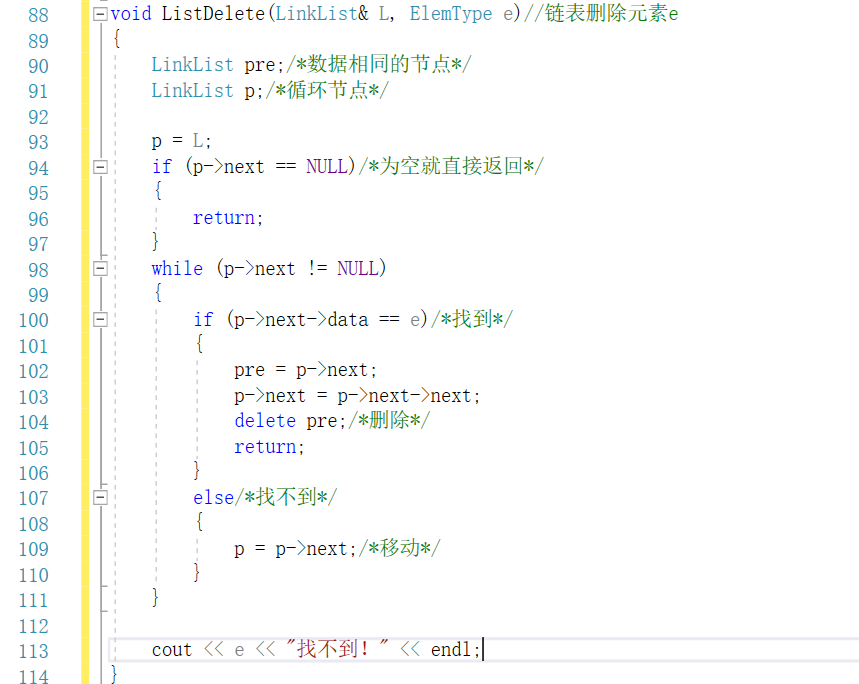
2.1.2本题PTA提交列表说明。
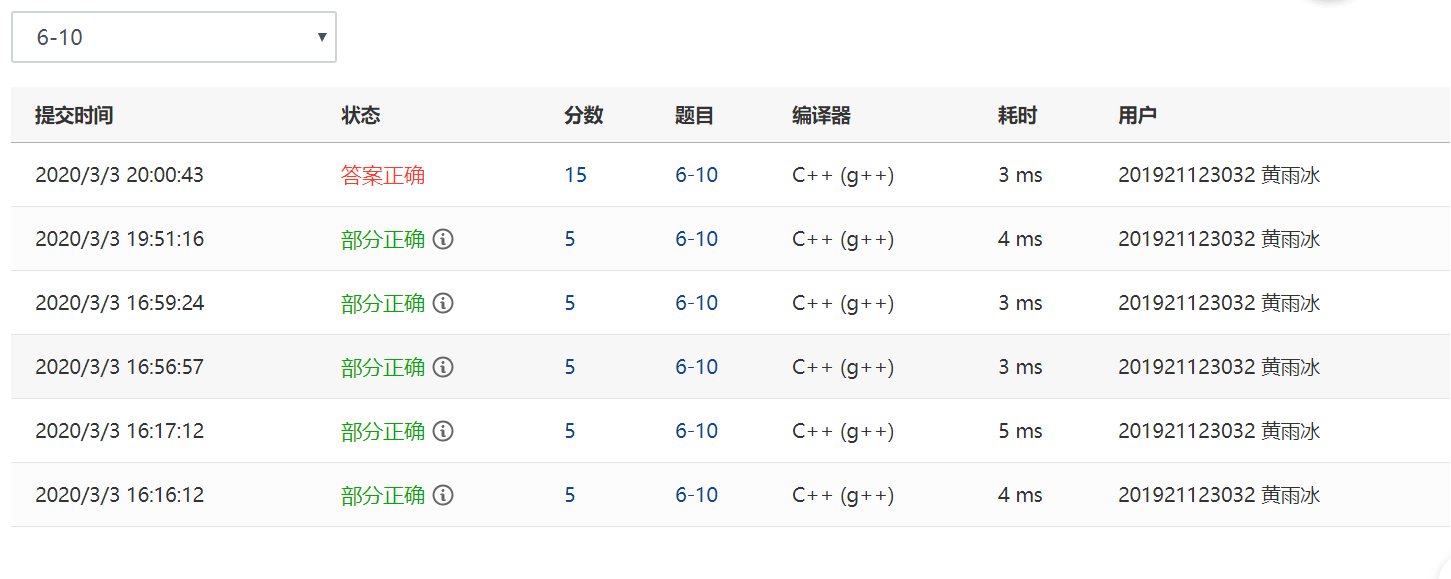
说明:
- 前两个部分正确:错误原因相同,我忽略了插入的数与原链表节点所指元素相同的条件,然后电脑有点卡,相同的代码我提交了两次;
- 部分正确:我把插入函数中,在循环结束也没有插入即需要插入在链表末尾的步骤改了,令插入节点的
next=NULL; - 部分正确:我发现我的格式出了问题,在找不到删除的数的时候,输出这个提示需要换行,但是我没有;
- 部分正确:我加上了插入时存在相等数的条件;
- 答案正确:我开始的时候,插入删除条件都是用flag来标记后续是否需要再额外进行操作,用break来跳出循环,然后我仅仅,用return来代替这一个操作,(其他代码都没有发生变化,我个人认为,改动的只是方法)然后就正确了。
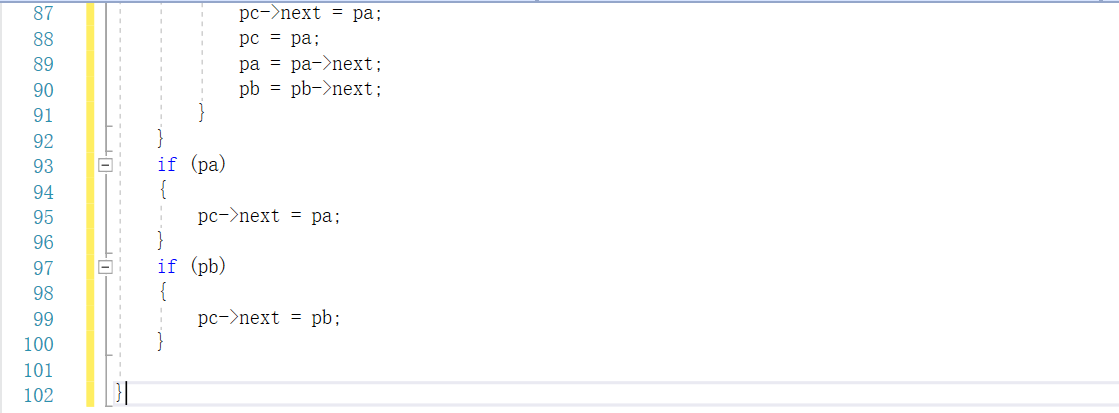
2.2 6-9 jmu-ds-有序链表合并
2.2.1代码截图
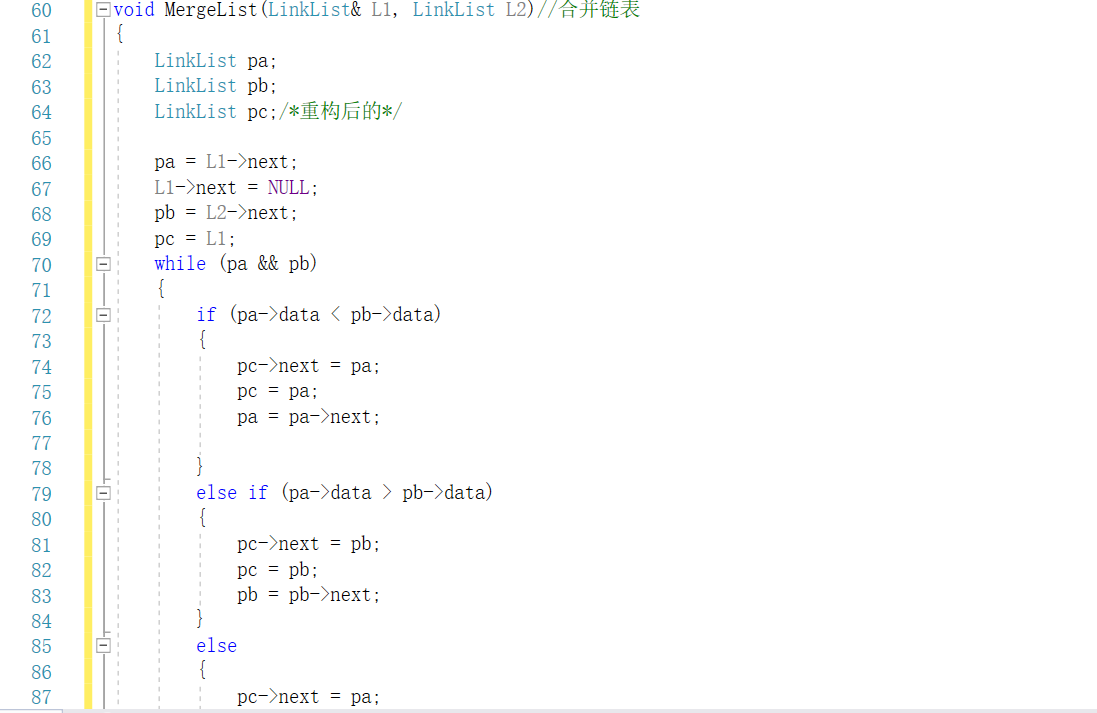
2.2.2PTA提交列表说明
说明:
- 部分正确:最开始的时候,我判断取哪个链表中的数的时候,没有单独考虑数据相等的情况,等于说,这样输出的结果,相同数据会有2个;
- 部分正确:我把数据相等的条件单独出来,只存入一个数据,但是原位置的等号忘记删除了,(按顺序执行下来,等于说,我没有更改);
- 答案正确:我把那个等号去掉之后就正确了。
- 编译错误:这是我在写最后一题的的过程中,提交的时候,不小心黏贴错了地方,我那会儿还纳闷,明明vs可以,为什么说我编译错误。
- 答案正确:然后我就把之前的代码再提交了一次。
其实不交也是可以的,但是我有一点强迫症,最后一次的提交,必须是正确的。
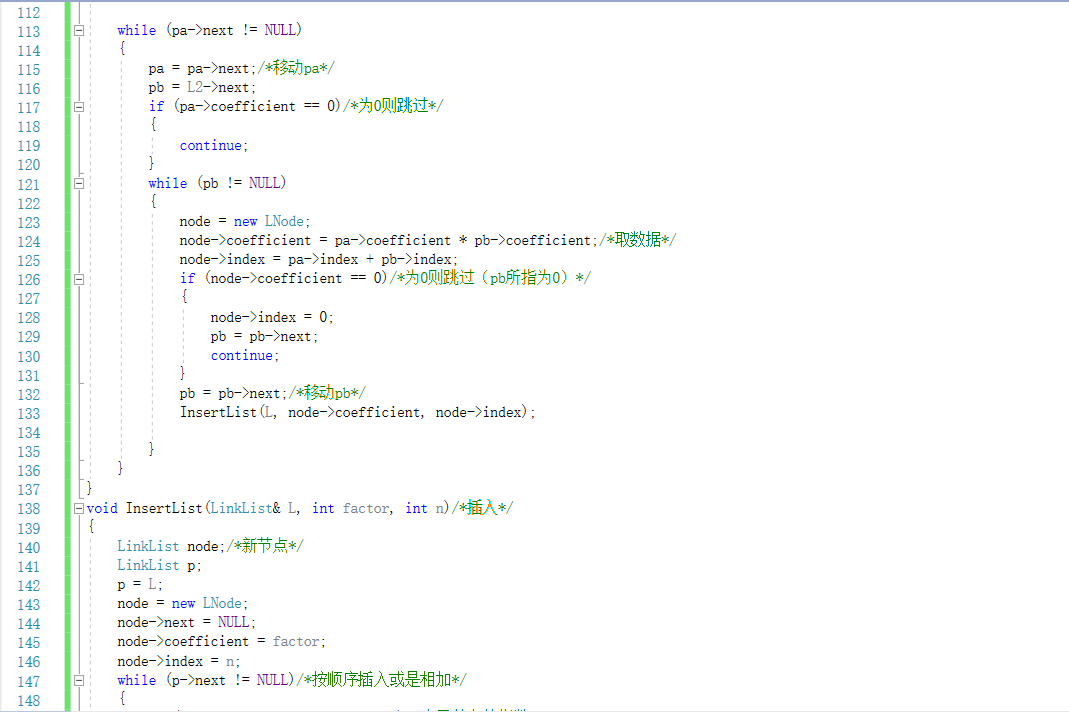
2.3 7-2 一元多项式的乘法与加法运算
2.3.1代码截图


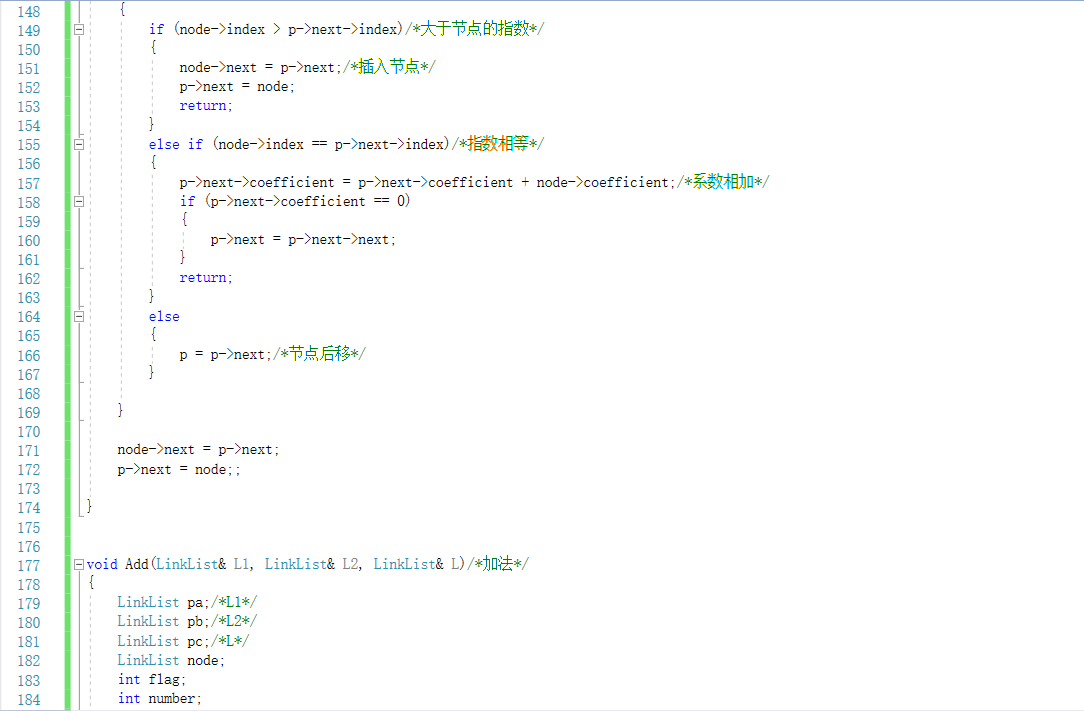
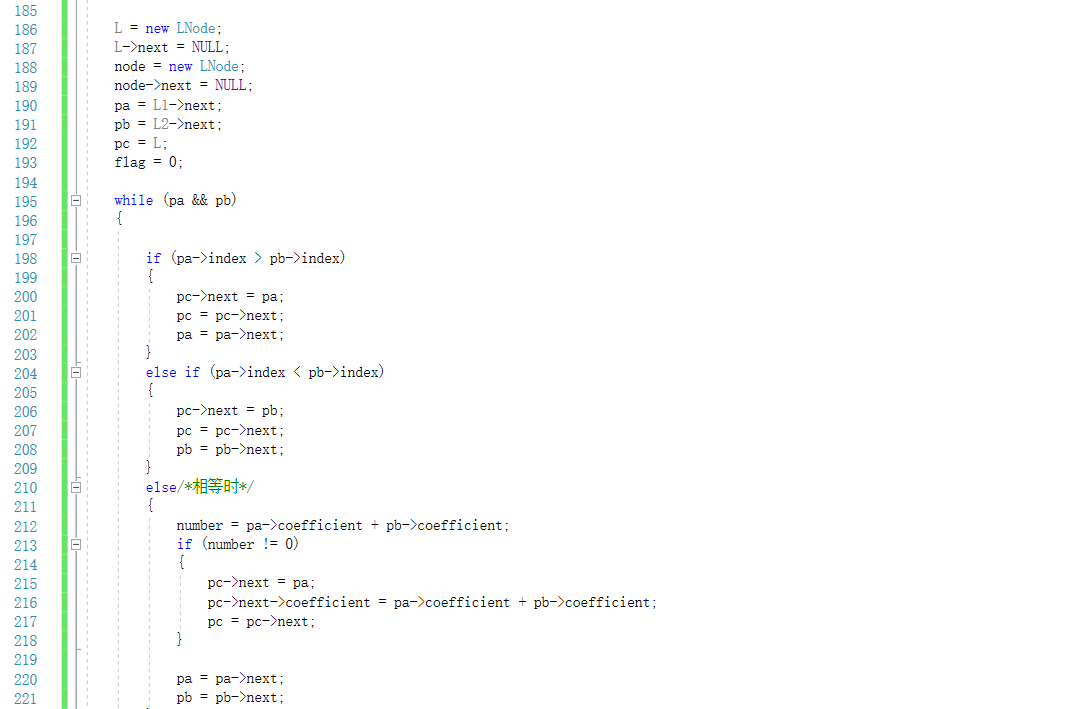

2.3.2PTA提交列表说明

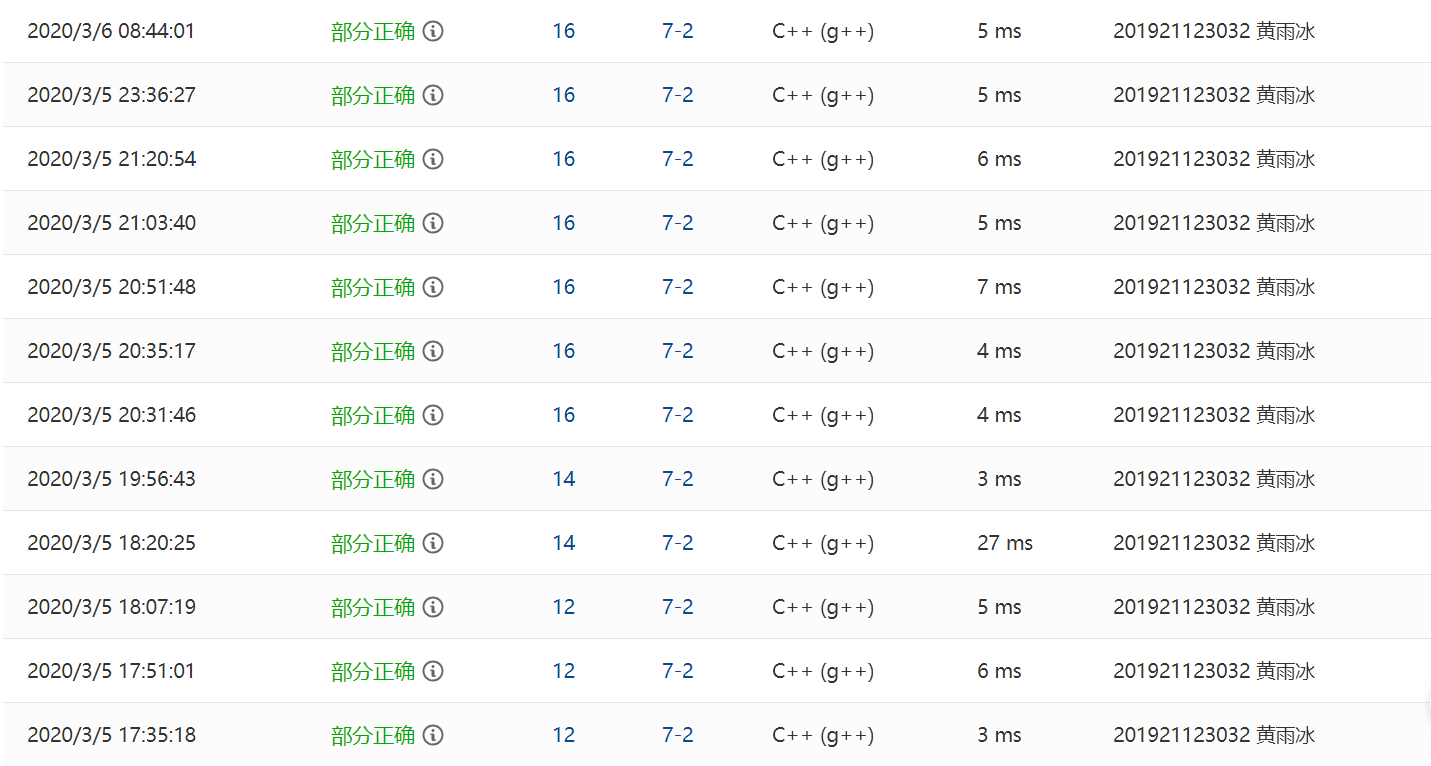
说明:(错的太多了,有些差异不大的,我就合起来写了。)
- 前两个部分正确:我出现了段错误,我新建的一个链表的结点p的next为空的情况下,我对它的一个结构体中的数据进行了操作;
- 部分正确:我把上面出现的问题改了,然后得到了第三个12分,好歹代码没有出错;
- 两个14分的部分正确:我以为,如果出现合并情况,不论链表是不是为空,都要输出
0 0,但是我只改了加法的部分,机缘巧合之下,居然让我过了一个测试点。🤔 - 第一个16分:从14分的16分的进步,是我把我输出的函数改了,我老是默认,链表为空输出的是
空链表!,然后改为0 0就,又过了一个测试点。 - 两个部分正确:我特定加了一个函数,如果出现合并的情况,在链表中要插入
0 0,改了半天,完全背离了题意。😳 - 两个部分正确:我就发现,它除了空链表,根本就不需要输出
0 0,然后我把刚刚写好的函数删了。 - 四个部分正确:合并抵消的情况,需要把原来的那个
0 0删除,而我之前没有发现。然后我把原先的那个删除了,还是没过。 - 答案正确:我终于,终于发现,我的加法的函数,只考虑了两个链表有一方未结束时末尾的情况,没有考虑如果二者同时结束,末尾需要加上NULL。
注:这道题,我改了超级久,过了的那一瞬间,真的开心到爆炸!

3.阅读代码(0--4分)
3.1 题目及解题代码
-
题目:
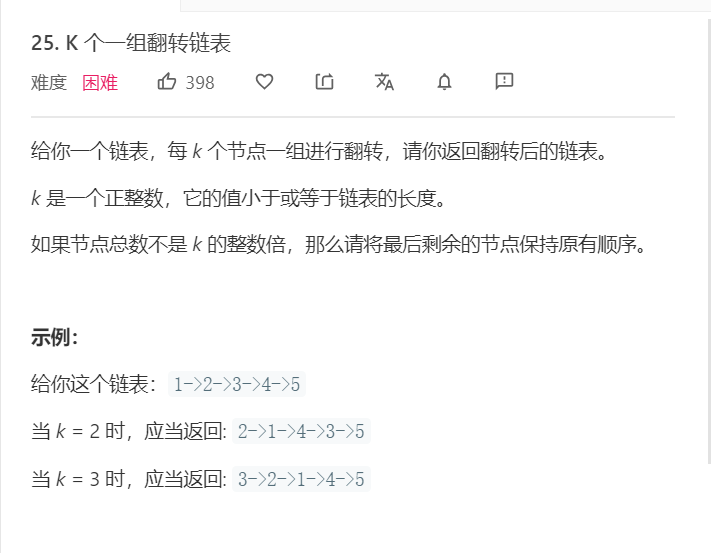
-
代码:
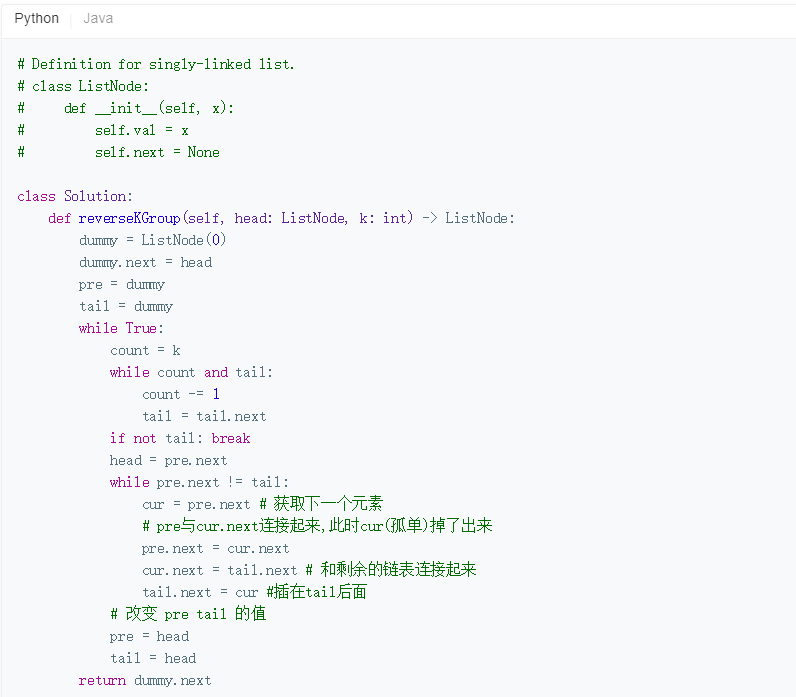
3.1.1 该题的设计思路
- 过程图解如下:(这个图,是直接用电脑自带的画图,画出来的,比较糙,我画了好久,然后发现有一种东西叫做流程图,,,)😅

- 思路:
先找到一组K,保存第一个元素前的位置和最后一个位置,然后用令一个指针,将最后一个位置前的部分,一个个插入最后那个元素的后面(尾插法)。 - 时间复杂度O(n),空间复杂度为O(1)
3.1.2 该题的伪代码
定义dummy存这个链表的头结点,pre为每一个k组第一个元素的前驱,tail指向每一个k组的最后一个元素,head指向每一个k组的第一个元素,count用于计数。
while 1
count初始化为k
while count不为0且tail不为空
count--;
tail指向后一个节点;
end while
if tail为空
跳出循环
end if
head=pre->next;
while pre的后继不是tail
cur=pre->next;
将cur插入tail的后面
end while
pre重新定位到head;
tail也移到head;
end while
返回dummy的后继节点
3.1.3 运行结果

3.1.4分析该题目解题优势及难点。
-
优势:
- 不需要额外的空间,直接在原链表上进行修改。
- 巧用尾插法来达到倒序的效果。
- 代码较为简单,易于阅读。
- 我原先看到这一题的时候,我的思路是,先定义一个循环变量number=0,然后遍历链表直到number=k,然后另外写一个函数用来逆序排列,我的逆序方法则是把后面的最后一个插到前面来,思路差不多,但他这个代码感觉就比较精简。
-
难点:
- 判断一组k逆序完成的条件是什么。
- 在进行逆序之前,这一组数据的前驱和后继都要知道。
- 下一个逆序的链表的头也需要知道。
3.2 题目及解题代码
-
题目:

-
代码:
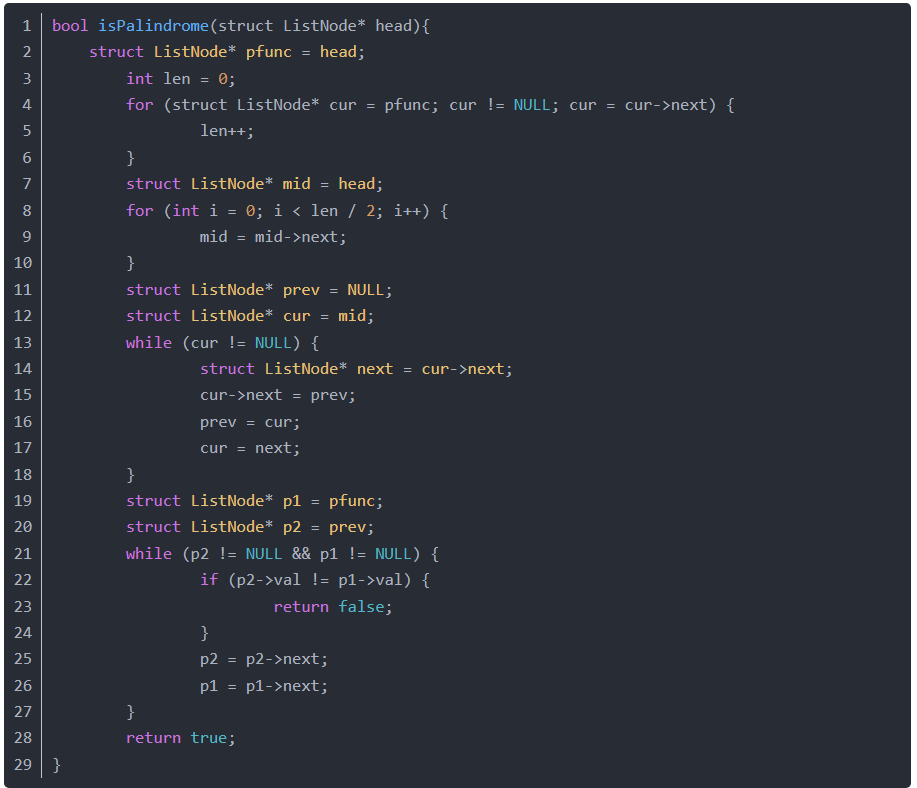
3.2.1 该题的设计思路
- 思路:先计算出链表的长度,然后将链表对半分,把后半部分的链表逆置,然后将原链表的前半部分与逆置的后半部分进行比较,如果一直都相同,则为回文
- 时间复杂度O(n),总共完整遍历了2次链表;空间复杂度O(1),没有再多申请空间。
- 图解:(我尝试用流程图画,发现这样画也很麻烦,果然,直接手写还是最方便了,就是可能不太好看。)
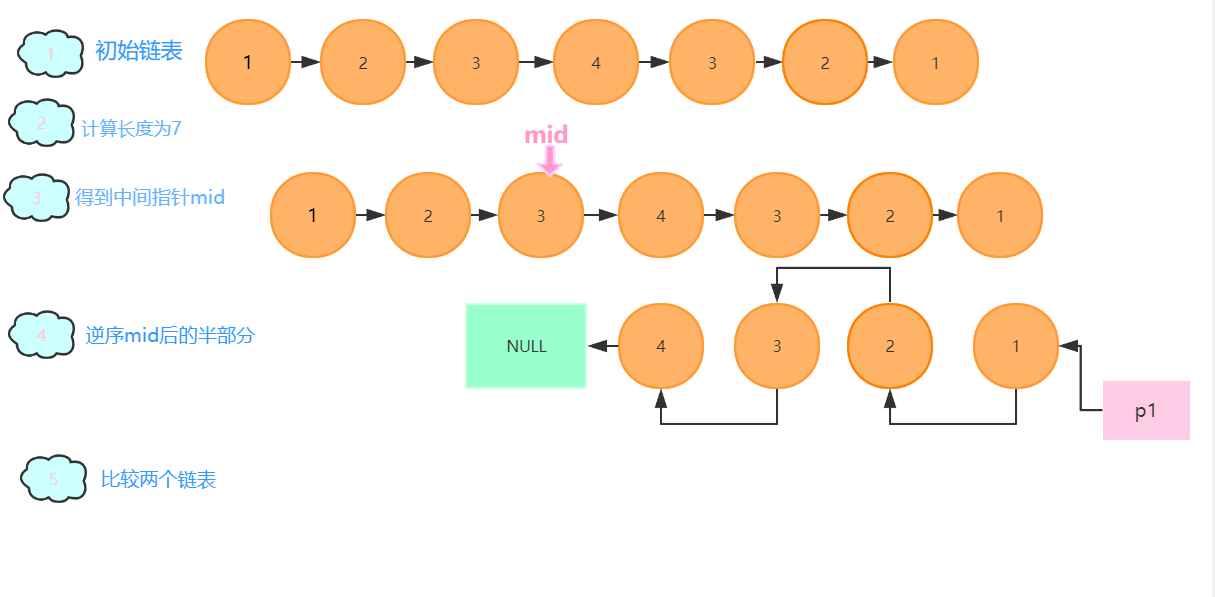
3.1.2 该题的伪代码
定义pfunc存原链表的头结点,len存链表长度,mid为中间节点位置,prev为后半部分逆序的头结点,cur为临时节点,next存放当前节点的后继,p1指向原链表,p2指向逆置后的后半部分的头结点
for 头结点 to 尾节点
计算长度len
end for
for 0 to 长度的一半
移动mid到中间节点
end for
cur=mid;
while 后半部分未结束
头插法逆序后半部分链表
end while
p1指向原链表
p2指向逆序后的后半部分链表
while p1和p2都不为空
if 两者数据不等
返回false
end if
移动节点指针
end while
全部比较完,返回true
3.1.3 运行结果

3.1.4分析该题目解题优势及难点。
- 优势:
- 我最开始的思路是整个链表逆序,逆序的同时计算长度,然后比较到中间的位置,看了他们的代码后发现,可以直接逆序一半的链表,然后进行比较。
- 直接取一半,一定程度上节省了时间。
- 难点:
- 如何获取尾节点位置
- 单链表,没有办法从后往前读
