

Redis分布式锁
概述
为了防止分布式系统中的多个进程之间相互干扰,我们需要一种分布式协调技术来对这些进程进行调度。而这个分布式协调技术的核心就是来实现这个分布式锁。
为什么要使用分布式锁
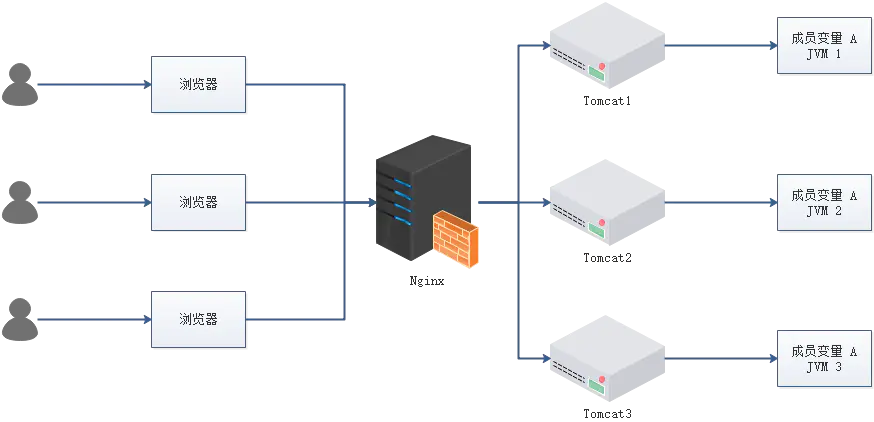
- 成员变量 A 存在 JVM1、JVM2、JVM3 三个 JVM 内存中
- 成员变量 A 同时都会在 JVM 分配一块内存,三个请求发过来同时对这个变量操作,显然结果是不对的
- 不是同时发过来,三个请求分别操作三个不同 JVM 内存区域的数据,变量 A 之间不存在共享,也不具有可见性,处理的结果也是不对的
注:该成员变量 A 是一个有状态的对象
如果我们业务中确实存在这个场景的话,我们就需要一种方法解决这个问题,这就是分布式锁要解决的问题
分布式锁应该具备哪些条件
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行
- 高可用的获取锁与释放锁
- 高性能的获取锁与释放锁
- 具备可重入特性(可理解为重新进入,由多于一个任务并发使用,而不必担心数据错误)
- 具备锁失效机制,防止死锁
- 具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁的实现有哪些
- Memcached:利用 Memcached 的
add命令。此命令是原子性操作,只有在key不存在的情况下,才能add成功,也就意味着线程得到了锁。 - Redis:和 Memcached 的方式类似,利用 Redis 的
setnx命令。此命令同样是原子性操作,只有在key不存在的情况下,才能set成功。 - Zookeeper:利用 Zookeeper 的顺序临时节点,来实现分布式锁和等待队列。Zookeeper 设计的初衷,就是为了实现分布式锁服务的。
- Chubby:Google 公司实现的粗粒度分布式锁服务,底层利用了 Paxos 一致性算法。
分布式锁的Redis实现
1 2 3 4 5 6 7 8 9 | 加锁:String threadId = Thread.currentThread().getId()set(key,threadId ,30,NX)、<br>解锁:if(threadId .equals(redisClient.get(key))){ del(key)} |
但是,这样做又隐含了一个新的问题,判断和释放锁是两个独立操作,不是原子性。
出现并发的可能性
还是刚才第二点所描述的场景,虽然我们避免了线程 A 误删掉 key 的情况,但是同一时间有 A,B 两个线程在访问代码块,仍然是不完美的。怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续航”。
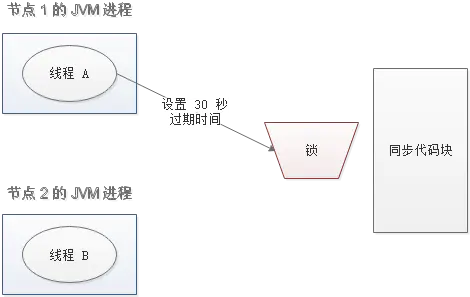
当过去了 29 秒,线程 A 还没执行完,这时候守护线程会执行 expire 指令,为这把锁“续命”20 秒。守护线程从第 29 秒开始执行,每 20 秒执行一次。
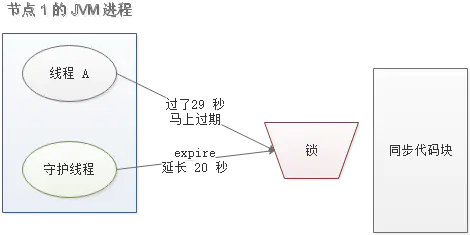
当线程 A 执行完任务,会显式关掉守护线程。
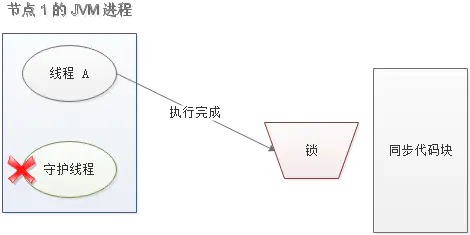
另一种情况,如果节点 1 忽然断电,由于线程 A 和守护线程在同一个进程,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了。
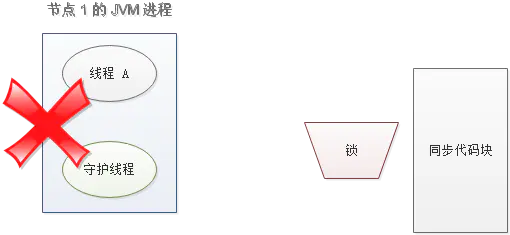
正确实现写法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | /** * 尝试获取分布式锁 * @param jedis Redis客户端 * @param lockKey 锁 * @param requestId 请求标识 * @param expireTime 超期时间 * @return 是否获取成功 */ public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) { String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime); if (LOCK_SUCCESS.equals(result)) { return true; } return false; } /** * 释放分布式锁 * @param jedis Redis客户端 * @param lockKey 锁 * @param requestId 请求标识 * @return 是否释放成功 */ public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) { String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId)); if (RELEASE_SUCCESS.equals(result)) { return true; } return false; } |
对比
数据库分布式锁实现
缺点:1.db操作性能较差,并且有锁表的风险
2.非阻塞操作失败后,需要轮询,占用cpu资源;
3.长时间不commit或者长时间轮询,可能会占用较多连接资源
Redis(缓存)分布式锁实现
缺点:1.锁删除失败 过期时间不好控制
2.非阻塞,操作失败后,需要轮询,占用cpu资源;
ZK分布式锁实现
缺点:性能不如redis实现,主要原因是写操作(获取锁释放锁)都需要在Leader上执行,然后同步到follower。
总之:ZooKeeper有较好的性能和可靠性。
从理解的难易程度角度(从低到高)数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高)Zookeeper >= 缓存 > 数据库
从性能角度(从高到低)缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低)Zookeeper > 缓存 > 数据库



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具