
Python批量采集某东评论,实现可视化分析
女朋友没事就喜欢网购,买一大堆又不用,总说不合适,为了不让她花冤枉钱,于是我决定用Python写一个采集商品评论的脚本,然后对商品进行分析,这样就不怕踩到坑了!

让我们直接开始本次操作
准备工作
环境安装
Python 3.10
Pycharm
模块使用
采集数据模块
-DrissionPage -> pip install DrissionPage
-csv
-time
数据可视化
-pandas -> pip install pandas
-pyecharts -> pip install pyecharts
-jieba -> pip install jieba
-wordcloud -> pip install wordcloud
源码和视频讲解都打包好了,为了让大家更好的学会本次内容,我加班熬夜录制了详细的视频讲解,希望对大家有帮助。

基本流程
一、数据来源分析
1.明确需求
明确采集的网站以及数据内容
网址: https://****/10088121691070.html#comment
数据: 评论相关内容
2.抓包分析
通过浏览器开发者工具分析对应数据位置
打开开发者工具
F12 / 右键点击检查选择 network 网络刷新网页
通过关键字搜索找到对应数据位置
关键字: 需要什么数据就搜什么数据
数据包地址: https://api.***/
二. 代码实现步骤
requests数据请求
基本步骤: (requests)

drissionpage自动化模块
模拟人的行为对于浏览器进行操作: 点击 输入 拖拽 获取数据
打开浏览器
监听数据包 -> 直接监听数据链接
-看数据包是否加载
-监听数据在执行动作之前
访问网站
直接获取响应数据
解析数据
保存数据
准备工作
新建一个临时 py 文件,并输入以下代码,填入您电脑里的 Chrome 浏览器可执行文件路径,然后运行。

这段代码会把浏览器路径记录到配置文件,今后启动浏览器皆以新路径为准。
另外,如果是想临时切换浏览器路径以尝试运行和操作是否正常,可以去掉 .save()

【完整源码+v Python1018 备注(圆圆)即可获得】
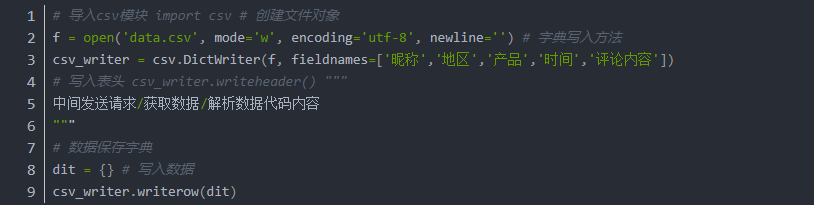
csv保存数据基本格式
根据你获取的数据不同:
fieldnames 根据提取数据保存在字典中键
encoding=‘utf-8’
如果使用utf-8打开表格文件出现乱码, 改成utf-8-sig
json字典取值

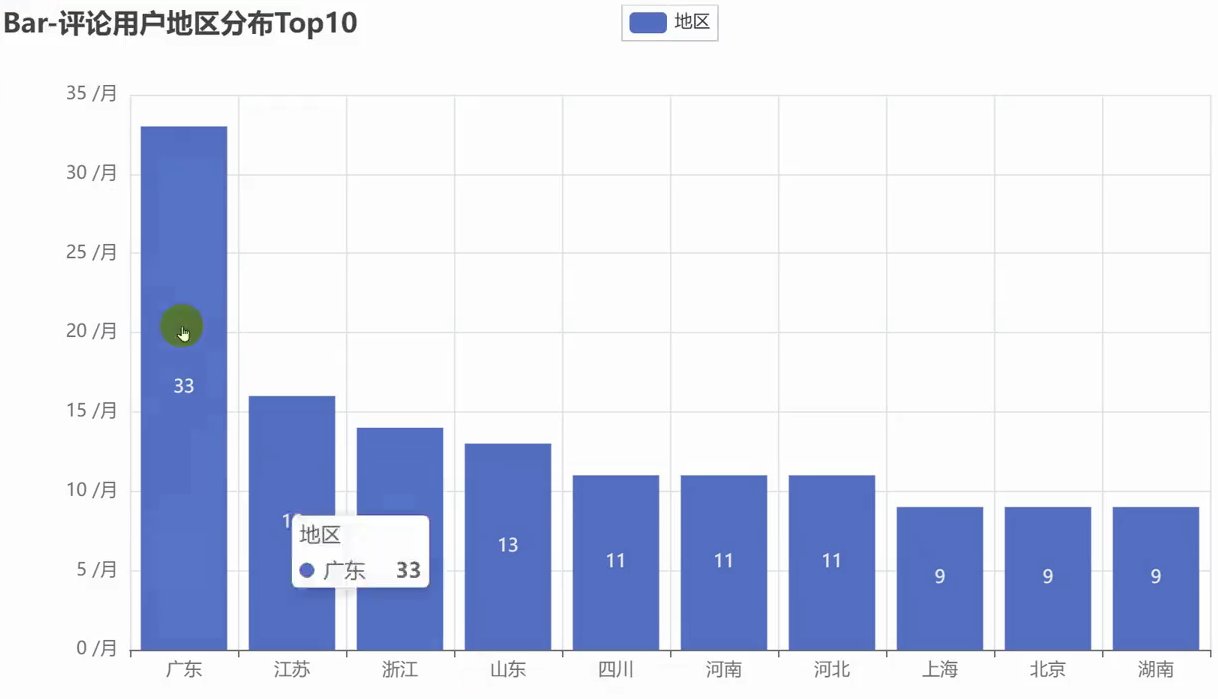
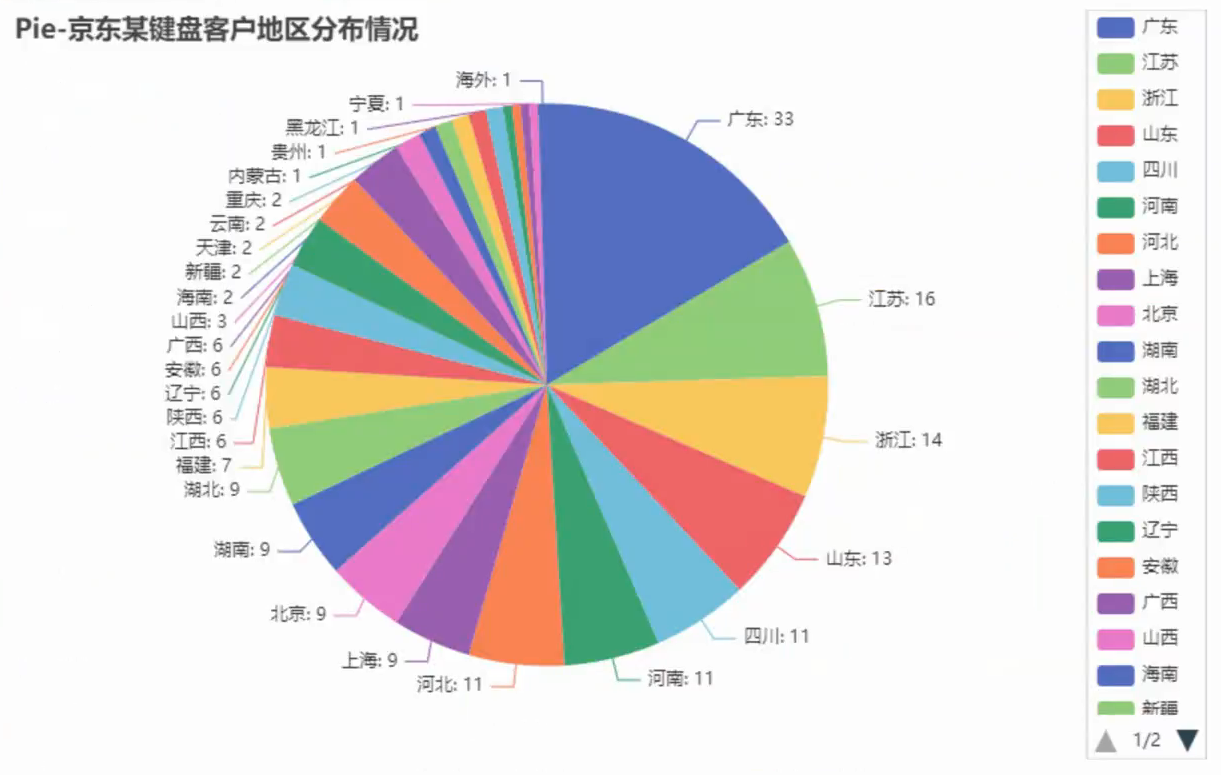
数据可视化
pyecharts可视化
官方文档: https://gallery.pyecharts.org/#/README



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人