
pytesseract实现识别pdf文件并将内容写入word文档中
步骤一:先安装tesseract-ocr-w64-setup-5.4.0.20240606 (安装记得语言包只安装需要的即可)
步骤二:将安装目录添加到系统环境变量中
(网上很多这一步之后就说可以运行程序了其实不然,一直报错没有添加到环境变量中)
步骤三:
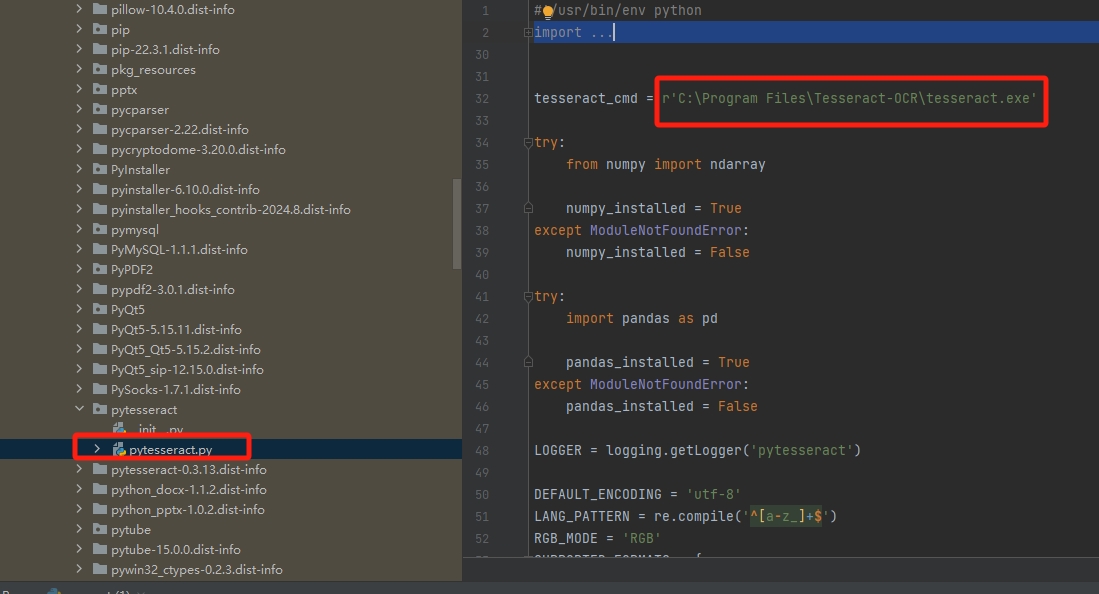
第四步:可以正常运行啦
==========================================================================================
from PyPDF2 import PdfReader
from docx import Document
import pytesseract
from PIL import Image
import io
def pdf_to_word_with_ocr(pdf_path, word_path):
import os
# 检查文件是否存在
if not os.path.exists(pdf_path):
raise FileNotFoundError(f"指定的文件 {pdf_path} 不存在。")
# 创建Word文档对象
doc = Document()
# 打开PDF文件
reader = PdfReader(pdf_path)
# 遍历PDF中的每一页
for page_number, page in enumerate(reader.pages):
# 尝试提取页面文本
text = page.extract_text()
if text:
# 如果能直接提取到文本,就添加到Word文档中
doc.add_paragraph(text)
else:
# 如果页面没有文本,尝试使用OCR提取图像中的文本
images = page.images
if images:
for image_index, img in enumerate(images):
# 将图像数据从PDF中提取出来
image = Image.open(io.BytesIO(img.data))
# 使用OCR识别图像中的文本
ocr_text = pytesseract.image_to_string(image, lang='chi_sim')
doc.add_paragraph(f"第{page_number+1}页, 图像{image_index+1}: {ocr_text}")
else:
# 如果页面既没有文本也没有图像,添加一个占位符
doc.add_paragraph(f"第{page_number+1}页无文本或图像。")
# 保存Word文档
doc.save(word_path)
使用函数
pdf_path = '45.pdf'
word_path = 'output.docx'
pdf_to_word_with_ocr(pdf_path, word_path)
分类:
python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律