

A java implementation of wc
A java implementation of wc
1. github repo
https://github.com/YinshenYuan/wc
2. PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
60 | 80 |
|
· Estimate |
· 估计这个任务需要多少时间 |
1000 | 1100 |
|
Development |
开发 |
800 | 800 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
50 | 60 |
|
· Design Spec |
· 生成设计文档 |
30 | 30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
10 | 10 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
5 | 5 |
|
· Design |
· 具体设计 |
800 | 900 |
|
· Coding |
· 具体编码 |
800 | 900 |
|
· Code Review |
· 代码复审 |
20 | 25 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
200 | 200 |
|
Reporting |
报告 |
60 | 60 |
|
· Test Report |
· 测试报告 |
20 | 20 |
|
· Size Measurement |
· 计算工作量 |
10 | 10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 | 30 |
|
合计 |
1100 | 1200 |
3. 解题思路
看到题目后,我感觉不是很难,就是比较繁琐,而且需求的定义中有很多模糊的地方,后来事情的发展也果然如此。
看到题目后,因为对java不是很熟悉,所以需要先了解java的各种库与方法。我参考的绝大部分资料都来源于java的官方turorial[1]。因为是对文本文件进行处理,字符串[2]和正则表达式[3]的了解肯定少不了。而且还涉及读写文件,所以文件操作[4][5]的了解也少不了。高级功能还涉及GUI[6],所以GUI也看了看。这些在java的官方tutorial以及document中都有很详细的说明。
4. 程序设计实现过程
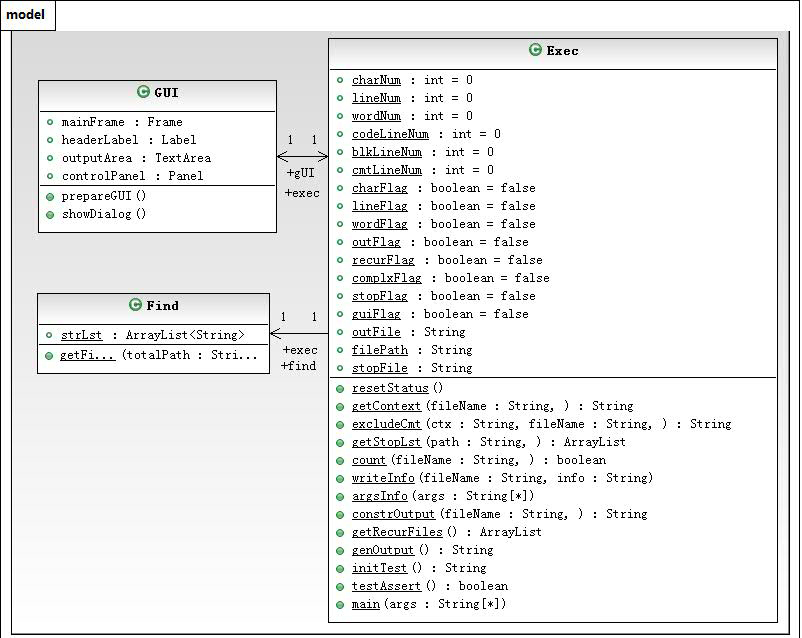
我的程序由3个类组成,分别是
- Exec:负责参数解析、计数等主要功能,也是程序的入口
- Find:负责递归地匹配glob风格的通配符
- GUI: 负责GUI界面的实现
其中Exec类调用Find类的方法来实现通配符,以及调用GUI类的方法实现界面的绘制以及事件的处理。类图如下所示
5. 代码说明
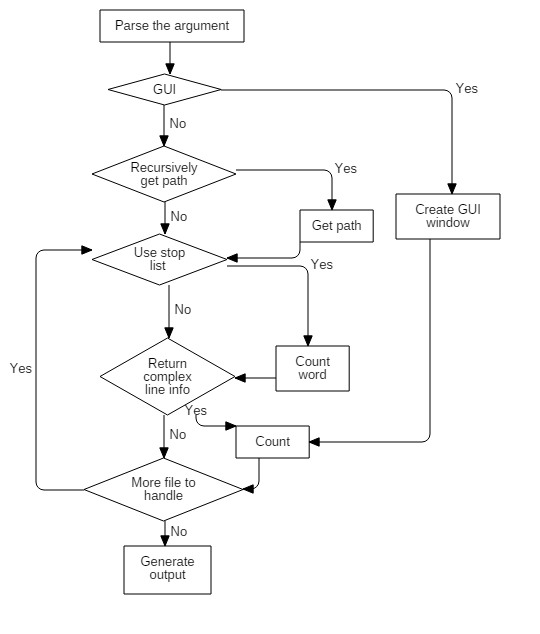
1)程序总体流程见下图
2)重点介绍:返回复杂的数据这一功能
像基本功能、GUI和glob风格的通配符都比较简单(对这些而言难的反而是理解相应的需求)。我就说说唯一让我苦手的返回更复杂的数据这一功能。在刚开始做这个功能时,我先是想用正则表达式来对每个单独的行进行匹配,来判断它是什么类型的行。但我发现对单独的行进行匹配对块注释无能无力。所以我另辟蹊径,想到了另一个方法,就是在原来的文本中,对每一个单独的行进行是否是空行的匹配,这可以很容易地用正则表达式实现;然后将文本中的所有注释去除,那么在去除了注释的文本中,所有不是空行的行就是代码行,实现的方法只不过是空行匹配的取反。剩下的注释行可以用下述的公式求解。
注释行数 = 总行数 - 空行数 - 代码行数
那么剩下的问题就只有怎么去除文本中的注释了。我用了状态机的思想,设计了如下的状态图:
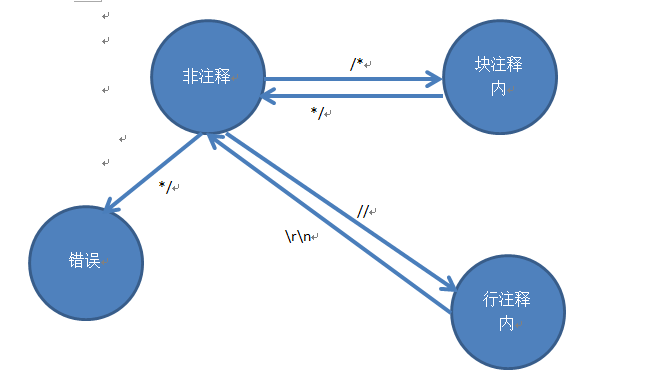
然后只要依次读入文件中的字符,就可以判断字符属于哪个类别了。我在老师给的范例上跑了跑,效果拔群。但是,我上述的设计还是有一些小bug,而且有点隐晦。那就是我没有考虑双引号中出现的"//" "/*" "*/"。这些表示字符串的在双引号中出现的注释符号在进行判定时不应该考虑在内,所以遇到双引号中的注释符号时,非注释的状态保持不变。进行计数的代码如下
// ctxEC is used to denote the text excluding comments
String ctxEC = excludeCmt(ctx, fileName);
String[] linesEC = ctxEC.split("\r\n", -1); // Split the text into lines
// Reset the variables' value, corresponding to the number of code lines,
// blank lines, comment lines respectively
codeLineNum = blkLineNum = cmtLineNum = 0;
Pattern blkPtn = Pattern.compile("\\s*\\W?\\s*"); //Pattern used to match the blank lines
// Match blank lines in the original text
for(String line: lines)
if(blkPtn.matcher(line).matches())
++blkLineNum;
// Match code lines in the text excluding comments
for(String line: linesEC)
if(!blkPtn.matcher(line).matches())
++codeLineNum;
// Use the formula to calculate the number of comment lines
cmtLineNum = lineNum - blkLineNum - codeLineNum;
6. 测试设计过程
- 如何设计测试用例
可以利用前文中的流程图来进行圈复杂度分析,可以得到圈复杂度为6,那么我的测试用例的设计是先对单独的功能进行测试,然后对将多个功能总和在一起进行测试,同时测试用例中一部分内容具有典型性,一部分内容具有高风险,至于哪些地方有高风险,在后续中讨论。其中将多个功能总和在一起进行测试的因为代码最多最复杂,所以作为主路径,用10个用例可以很好地覆盖所有独立路径,并且可以做到条件覆盖。下面的代码用于初始化测试用例。(具体的测试用例所读取并计数的文件存放在了项目的testcase目录下)
// // Use case 1: use various characters to test -c argument
// String[] args = {"-c", "testcase/test1.txt"};
// // Use case 2: use various words to test -w argument
// String[] args = {"-w", "testcase/test2.txt"};
// // Use case 3: use some lines to test -l argument
// String[] args = {"-l", "testcase/test3.txt"};
// // Use case 4: use -o argument to test the output function
// String[] args = {"-c", "-w", "-l", "testcase/test4.txt", "-o", "testcase/result.txt"};
// // Use case 5: use -s argument to test the glob wildcard matching and recursion
// String[] args = {"-c", "-w", "-l", "-s", "*.txt" };
// // Use case 6: use -a argument to test whether complex results can be returned
// String[] args = {"-l", "-a", "testcase/test6.txt"};
// // Use case 7: use -e argument to test whether the stop list function works just fine
// String[] args = {"-w", "-e", "testcase/stopList.txt","testcase/test7.txt"};
// // Use case 8: use -x argument to start GUI and select some files to test it
// String[] args = {"-x"};
// // Use case 9: use -w -c -l -a -s -o -e arguments altogether and test whether it works out
// String[] args = {"-c", "-w", "-l", "-s", "*.txt", "-e", "testcase/stopList.txt", "-a", "-o", "testcase/togResult.txt"};
// // Use case 10: use some wrong arguments to test whether the program crashes when unexpected input is given
// String[] args = {"-c","a","b"};
- 哪些地方会导致高风险
具有程序中具有高风险的集中在两个方面。
1)一个是程序面对正确但不典型的输入,能否产生正确的输出,比如统计字符数中的特殊字符,统计行数中的空行,统计单词数时不能将空字符串考虑在内(特别容易出现在文本的两端),以及我在前面提到的双引号中的注释符号等等这些问题。
2)另一个是程序面对错误的输入时,是否会崩溃,能否给出正确的错误信息,比如参数不正确,要读取的文件不存在等等。
- 测试代码的设计
关于测试代码的设计,我先在程序开始处初始化要测试的相关信息,比如要调用哪些参数,测试哪些功能。然后在程序结尾处根据预测的输出插入相应的断言(assert),然后根据是否产生了断言中断来判断程序是否给出了预测的输出。以上两个部分的代码分别位于initTest()和testAssert()方法中,可以成对地取消注释来进行测试。
另外还有单元测试,我选择分别对3个类进行单元测试,分别如下:(我在代码的注释中声明哪些内容可以取消注释来进行单元测试,可以在3个类的代码中中直接搜索unit testing定位)
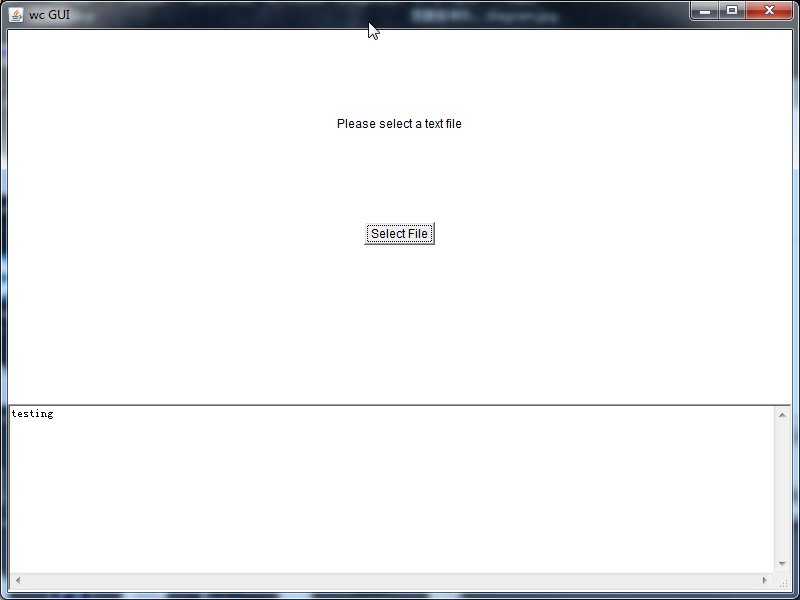
1)对GUI类的单元测试
在GUI类中编写main函数,直接调用GUI类的绘制方法,同时将GUI类中使用了Exec类的方法的代码注释,手动地原来用方法调用获得的输入,完成测试。结果如下
2)对Find类的单元测试
因为Find类没有调用别的类,所以Find类的单元测试较为简单,直接在Find类中添加main函数,调用自身的方法来测试。
3)对Exec类的单元测试
对Exec类进行单元测试,只要将Find类获得的路径替换为手动编写的路径,然后进行测试即可。
7. 参考文献链接
[1] java tutorial
[2] java string
[3] regular expression
[4] java file system
[5] find path recursively
[6] awt FileDialog
