一文读懂spark yarn集群搭建
文是超简单的spark yarn配置教程:
yarn是hadoop的一个子项目,目的是用于管理分布式计算资源,在yarn上面搭建spark集群需要配置好hadoop和spark。我在搭建集群的时候有3台虚拟机,都是centos系统的。下面就开始一步一步地进行集群搭建。
一、配置hosts文件
hosts文件是主机名到ip的映射,目的是为了方便地查找主机,而不用去记各个主机的IP地址,比如配置master 10.218.20.210 就是为10.218.20.210地址取名为master,在以后的url中就可以用master代替10.218.20.210。
这里我们为了在配置文件中更方便地写url,所以需要在这里配置各个节点的host-ip映射。
10.217.2.240 master 10.217.2.241 slave1 10.217.2.242 slave2
这里我的三个节点分别对应master slave1 slave2.
二、配置ssh
启动hdfs和spark的时候各个节点需要相互访问,所以要配置好ssh秘钥。可以为每个主机生成各自的rsa秘钥也可以只生成一个rsa秘钥,并发送到所有主机。
三、安装JAVA
spark是基于java写的,这里把java解压到某目录然后配置环境变量,修改/etc/profile
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77 export JRE_HOME=$JAVA_HOME/jre export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
四、安装scala
使用spark最好还是用scala语言,解压后配置环境变量,修改/etc/profile
export SCALA_HOME=/home/hadoop/scala-2.10.6
export PATH=$PATH:$SCALA_HOME/bin
五、安装配置HADOOP和YARN
yarn的包是包含在hadoop里面的,解压hadoop压缩包,tar -zcvf hadoop-2.7.5.tar.gz,配置环境变量,
export HADOOP_HOME=/home/hadoop/hadoop-2.7.5
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_HOME=/home/hadoop/hadoop-2.7.5
export YARN_CONF_DIR=${YARN_HOME}/etc/hadoop
环境变量配置完了,现在要配置hadoop自身的配置文件,目录在hadoop目录下的etc/hadoop文件夹,里面有很多配置文件.我们需要配置七个:hadoop-env.sh,yarn-env.sh,slaves,core-site.xml,hdfs-site.xml,maprd-site.xml,yarn-site.xml。
hadoop-env.sh:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
yarn-env.sh:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
slaves:
slave1 slave2
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop-2.7.2/tmp</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.7.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.7.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>fang-ubuntu:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
配置好了以后,需要调用hadoop namenode 格式化,配置改变以后就需要格式化namenode,其实就是创建一些目录,增添一些文件,以后配置不变的话就不需要再格式化。如果配置变了就需要删除tmp,dfs,logs文件夹,再进行格式化。
bin/hadoop namenode -format #格式化namenode
现在就可以启动hdfs系统和yarn系统了:
sbin/start-dfs.sh #启动dfs sbin/start-yarn.sh #启动yarn
启动成功后可以使用jps命令查看各个节点上是否启动了对应进程。
master节点上:
[root@CTUGT240X sbin]# jps 23809 SecondaryNameNode 23971 ResourceManager 24071 NodeManager 23512 NameNode 23644 DataNode 24173 Jps
slave节点上:
[root@CTUGT241X hadoop]# jps 31536 Jps 31351 DataNode 31454 NodeManager
六、安装配置spark:
解压spark压缩包
tar -zcvf spark-2.2.0-bin-hadoop2.7.tar
配置spark配置文件:
cd ~spark-2.2.0-bin-hadoop2.7/conf #进入spark配置目录
cp spark-env.sh.template spark-env.sh #从配置模板复制
vim spark-env.sh #添加配置内容
在spark-env.sh末尾添加以下内容(这是我的配置,你可以自行修改):
export SPARK_HOME=/home/hadoop/spark-2.2.0-bin-hadoop2.7
export SCALA_HOME=/home/hadoop/scala-2.11.12
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_77
export HADOOP_HOME=/home/hadoop/hadoop-2.7.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$YARN_HOME/etc/hadoop
export SPARK_MASTER_IP=20.2.217.123
SPARK_LOCAL_DIRS=/home/haodop/spark-2.2.0-bin-hadoop2.7
SPARK_DRIVER_MEMORY=1G
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
上述的版本那些根据个人的进行修改,还有运行内存那些要根据硬件配置来,太大了启动spark会失败。
slaves文件:
slave1 slave2
配置好后再各个节点上同步,scp ...
启动spark,
sbin/start-dfs.sh
sbin/start-yarn.sh
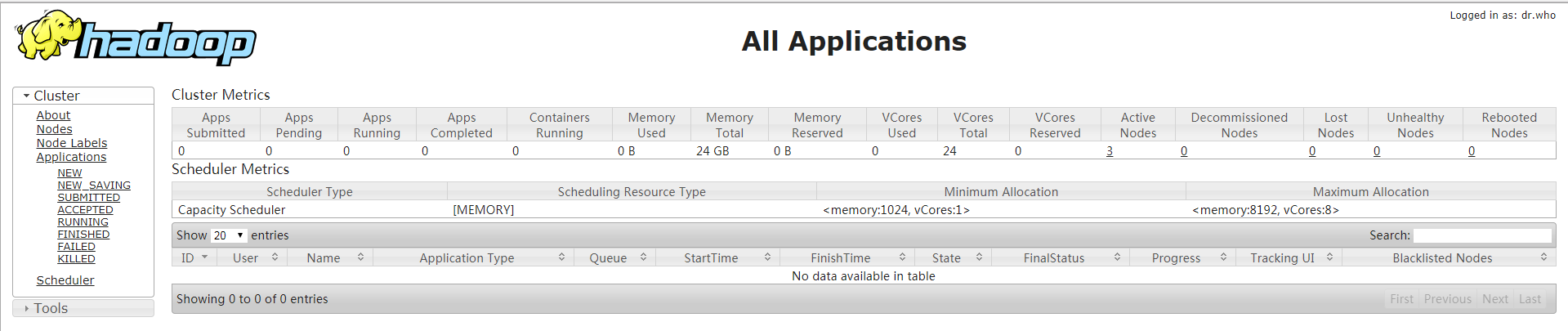
看终端报错没有,没报错基本就成功了,再去UI看看,访问:http://master:8088
posted on 2018-02-26 17:07 skyer1992 阅读(11523) 评论(0) 编辑 收藏 举报


