
Django
目录
- Django
- 27、CBV添加装饰器
- 28、中间件
- 29、csrf跨站请求
- 30、csrf相关装饰器
- 31、auth
- Django操作数据库的SQL语句查看
Django
1、web应用的概念
http的默认端口号 :80
https的默认端口号 :443
1.1、web应用是什么?
就是通过浏览器访问的应用都是web应用
1.2、软件开发模式
C/S:client:客户端 server:服务端
B/S:browser:浏览器 server:服务端
# 本质:B/S架构也是C/S架构
服务端需要具备的特征:
24小时对外提供服务
1.3、web应用程序的优点
1、只需要一个浏览器
2、充当多个应用的客户端,可以减少硬盘空间的占用
3、客户端不需要主动更新,服务端更新即可
4、支持跨平台使用
1.4、web应用的缺点
1、一旦服务端出现问题,客户端立刻受到影响
2、兼容性问题。同样的代码在不同的浏览器渲染出来的效果可能不一样
1.5、web框架
框架:就是在固定的位置书写固定的代码(主体)
1.6、Python中的三大主流框架
1、Django框架
大而全,类似于航空母舰
2、flask框架
小而精,轻量级框架,依赖于第三方模块
3、tornado框架
异步高性能框架
2、MVC和MTV模型
2.1、MVC
MVC:
M:model(跟数据打交道) 模型
V:View(html页面) 视图
C:controller(逻辑相关) 控制器
S:sevice(服务层)--->>公共的功能
C层逻辑特别多的时候,就会分出S层
# python之外的
2.2、MTV
MTV
M:model(模型层:跟数据相关) --- model(跟数据打交道)
T:template(模板:html页面) --- View(html页面)
V:view(主要写逻辑的) --- controller(逻辑相关)
# Python中的说法
# MVC与MTV中的层次一一对应
3、Django下载与安装
3.1、Django的版本问题
Django1.x:老项目再用
Django2.x:现在的新项目再用
Django3.x:刚出来的新版本
3.2、安装Django
# 命令行
pip install django
pip3 install django # 安装最新版本
pip3 install django==1.11.11 # 指定版本
# pycharm
scttings
Python interpreter
搜索点击安装即可
3.3、验证是否成功
在cmd中,输入:django-admin,如果有输出信息,就代表安装成功
django-admin
3.4、创建Django项目
3.4.1、命令行创建
# 提前切换到项目要保存的文件夹内
创建项目
django-admin startproject 项目名
3.4.2、pycharm创建
File
new project
Django
选择Python解释器
3.4.3命令行和pycharm创建项目的区别
pycharm创建:
自动生成templates文件夹
settings.py文件:
TEMPLATES = [{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')]}
命令行创建:
没有templates文件夹
settings.py文件:
TEMPLATES = [{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [] # 需要手动添加路径
3.4.4、启动Django项目
"""前提:先切换到manage.py 所在的文件夹下"""
命令行启动:
python manage.ot runserver # 默认本机ip+端口
python manage.ot runserver 127.0.0.1:8000 # 启动其他ip + 端口
python manage.ot runserver 8000 # 默认本机ip可以更改端口
pycharm启动
找到对应的项目点击绿色箭头就可以启动

3.4.5、创建应用
# 创建应用:
python manage.py startapp app名
eg:
用户模块 应用
订单模块
收货地址管理
...
命令行创建:
python manage.py startapp app名
"""
app名:见名知意
"""
# 一个Django项目至少要有一个应用
pycharm创建:
tools
run manage.py task
startapp app名
# 创建应用完成之后,第一件事就到配置文件中配置文件
INSTALLED_APPS = [
'app名'
]
4、主要文件介绍
mysitel # 项目名
- app01 # 应用名
--migrations # 迁移数据库的时候,会把迁移记录保存到这里
__init__.py
--admin.py # Django自带的后台管理系统
--apps.py
--models.py # 模型成,跟数据相关的
-- tests.py # 测试脚本
--views.py # view层,核心逻辑、
-mysitel # 项目同名文件夹
--__init__.py
--settings.py # 配置文件
--urls.py # 路由层,路径与视图函数的对应关系
--wsgi.py # wsgiref服务器,WSGI协议,uwsgi服务器
-templates # html文件
db.sqlite3 # Django自带的小型数据库
-manage.py # 启动文件(入口文件)
5、Django三板斧
# Django自动重启的现象:热更新
locals() # 获取局部名称空间的变量名(内存地址),必须在局部名称空间
globals() # 获取全局名称空间的变量名
5.1、HttpResponse
HttpResponse 返回字符串类型数据
-----------------------------------------------------------------
from app01 import views
# urls.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/',views.index) # 函数名不能加括号
]
-----------------------------------------------------------------
# views.py
from django.shortcuts import render, HtttpResponse, redirect
def index(request):
return HttpResponse('Hello Django!')
5.2、rener
render 返回request对象,html页面,还可以传值
-----------------------------------------------------------------
from app01 import views
# urls.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/',views.index) # 函数名不能加括号
]
-----------------------------------------------------------------
# views.py
from django.shortcuts import render, HttpResponse,redirect
from time
def index(request):
ctime = time.strftime('%Y-%m-%d %X')
return render(request,'index.html',{'ctime':ctime}) # 将ctime返回到前端页面
-----------------------------------------------------------------
# index.html
<p>{{ ctime }}</p>
5.3、redirect
redirect 重定向
可以将用户访问重定向到其他网址
或者自身其他的url
-----------------------------------------------------------------
from app01 import views
# urls.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/',views.index) # 函数名不能加括号
]
-----------------------------------------------------------------
# views.py
from django.shortcuts import render, HttpResponse,redirect
def index(request):
ctime = time.strftime('%Y-%m-%d %X')
return redirect('/home/')
-----------------------------------------------------------------
6、静态文件的配置
什么是静态文件?
静态文件是网站页面所使用到的提前已经写好的文件,如css,js,第三方组件 bootstrap,sweetalert,fontawesome等
静态文件的储存路径一般是 static 文件夹。
创建项目的时候默认是没有该文件夹的,需要手动创建
在项目的根路径下创建即可。
在static 文件夹可以根据不同的功能进行不同的划分
static
- JS
- CSS
- IMG
- ...
http://127.0.0.1:8000/static/css/...不能访问是因为没有开通接口,需要在配置文件中添加。
STATICFILES_DIRS = [
os.path.join(BASSE_DIR, 'static') # 将静态文件路劲添加到环境变量,相当于开通接口
]
配置文件中的STATIC_URL = '/static/' # 相当于令牌
# 动态引入
{% load static %}
<link rel='stylesheet' href="{% 'static' 路径 %}">
7、request请求
request.method
获取当前请求方式,是大写的字符串
request.GET :获取GET请求的数据:<QueryDict: {}>
request.GET.get() :根据括号内的参数指定获取数据
request.GET.getlist :获取全部数据,以列表的形式展现
request.POST :获取POST请求的数据:<QueryDict: {}>
request.POST.get() :根据括号内的参数指定获取数据
request.POST.getlist() :获取全部数据,以列表的形式展现
8、form表单
form action=" " # 提交地址
method='' # 提交方式
"""
action=''
1、什么都不写:提交到当前页面
2、全写:可以提交到任何地址
3、只有后缀:/index/ 会自动提交到这里,ip 端口默认
"""
# 面试题
get 和 post区别
get:get可以携带非常小的参数,对数据大小有限制,没有请求体
post:有请求体,对数据大小没限制,传输比get安全
HTTP四大特征
基于请求响应
基于TCP/UDP协议之上
无状态
无/短连接
MySQL可能会出现的安全问题:
SQL注入
前端当中可能会出现的安全问题
XSS攻击:用户在输入框输入某些代码,后端使用
Django可能会出现的安全问题
csrf请求
9、pycharm链接MySQL
pycharm >>> databases >>> Date Source >>> MySQL >>> 按照提示输入即可
10、Django链接MySQL
需要更改配置文件
更改配置文件
DATEBASE = {
'default':{
'ENGINE':'djang0.db.backends.mysql',
'NAME':'' # 库名字
'PORT':3306 # 端口
'USER':'root' # 用户名
'PASSWORD':'' # 密码
'CHARSET':'utf8' # 字符集
'HOST':'127.0.0.1' # ip
}
}
# Django默认的操作MySQL的模块是MySQLdb
"""
在python3.6版本以下,需要在任意__init__加入下面两句话
pip install pymysql
import pymysql
pymysql.install_as_MySQLdb()
"""
# mysqlclient 模块:安装之后不用各种乱七八糟的,但不容易安转
11、Django操作ORM
1、什么是ORM
关系映射对象
2、特点
在操作数据库的时候不需要写原生SQL语句
"""相对而言执行效率变低了"""
3、ORM书写位置
models.py
4、代码指向
类名 >>> 表名
对象 >>> 记录
属性 >>> 字段(对应的数据)
11.1、创建表
"""
如果创建表的主键字段名为 id 那么可以默认不写,也是唯一且自增的
如果创建主键的字段为 uid pid 等都需要书写出来
uid = models.AutoField(primary_Key=True)
"""
# 创建表
from django.db import models
class User(models.Model):
# id int primary key auto_increment
id = AutoField(primary_Key=True)
# username varchar(32)
username = CharField(max_length=32)
passworf = CharField(max_length=32)
操作数据的代码书写完毕之后需要执行数据库迁移命令
python manage.py makemigrations
python manage.py migtate
# django_migrations表
内部数据可以随意删除,之后执行数据库迁移命令即可
11.2、ORM对字段的增删改查
from django.db import models
class User(models.Model):
# id int primary key auto_increment
id = AutoField(primary_Key=True)
# username varchar(32)
username = CharField(max_length=32)
passworf = CharField(max_length=32)
# 增加,直接书写然后数据库迁移命令
age = IntegerField()
之后出提示输入字段默认值
终端提示,输入:1 # 直接添加数据
# 增加2,在创建的时候直接输入
方式1:
age = IntegerField(null=True) # 即该字段可以为空
方式2:
age = IntegerField(default='默认值') # 直接输入默认值
# 删除,直接注释或者删除代码,数据库迁移
# age = IntegerField() 即删除字段
"""
在操作models.py的时候一定要细心
千万不要注释一些字段
执行迁移命令之前最好检查一下自己写的代码
"""
# 修改,直接修改代码,数据库迁移
age1 = IntegerField()
注:任何与数据库相关的命令全都要执行数据库迁移命令
11.3、ORM对数据的增删改查
filter():过滤。and关系
first():取出第一个数据
1、增加数据
from app名字 impore models
方式1
# insert into user(username,password) values('username','password');
res = models.User.object.create(username='username',passwoed='password')
方式2
user_obj = models..User(username='username',password='passwore') # 只是产生一个User类的对象
user_obj.save() # 这个才是真正的增加保存时局
2、删除数据
# delete from user where id=1;
models.User.object.filter(id=1).delete()
3、修改数据
方式1
# update user set username='username' where id=1;
models.User.object.filter(id=1).update(username='username')
update只修改筛选出来的字段
方式2
user_obj = models.User.filter(id=1).first()
user_obj.username = 'username'
user_obj.save() # save会自动判断对象是否存在,存在就是update更新,不存在就是insert插入
# 方法2从头到尾将所有字段全部更新一遍,无论改数据是否被修改
4、查看数据
res = models.User.object.filter() # 获取User表的所有数据
res = models.User.object.filter(id=1) # 获取id=1字段的所有数据
res = models.User.object.all() # 获取表所有数据
11.4、ORM创建表关系
什么是外键:
代表两张表之间的关系
MySQL关系型数据库
一对一
一张表与另外一张表记录一一对应
一对多
一张表中的一条记录对应另外一张表中多条记录
多对多
两张表中的任意多条记录对应另外一张表的多条记录
外键关系建立在第三张表中
# ORM创建表关系
# 图书表
class Book(models.Model):
title = CharField(max_length=32)
price = DecimalField(max_digits=8,decimal_places=2)
# 外键字段,一对多
publish = models.ForeignKey(to='Publish',to_field='id') # 如果关联的字段是 id 字段,那么可以忽略不写to_field='id'
# 外键,多对多
authors = models.ManyToManyField(to='Author')
"""
authors是虚拟字段,不会真正的在book表中东创建出来
"""
# 出版社
class Publish(models.Model):
addr = models.CharField(max_length=32)
# 作者
class Author(models.Model):
name = models.CharField(max_length=128)
# 外键:一对一方式1
author_detail = OneToOneField(to='AuthorDetail')
# 一对一方式2
models.FormaryField(unique=True)
# 作者详情
class AuthorDetail(models.Model):
phone = models.CHarField(max_length=32)
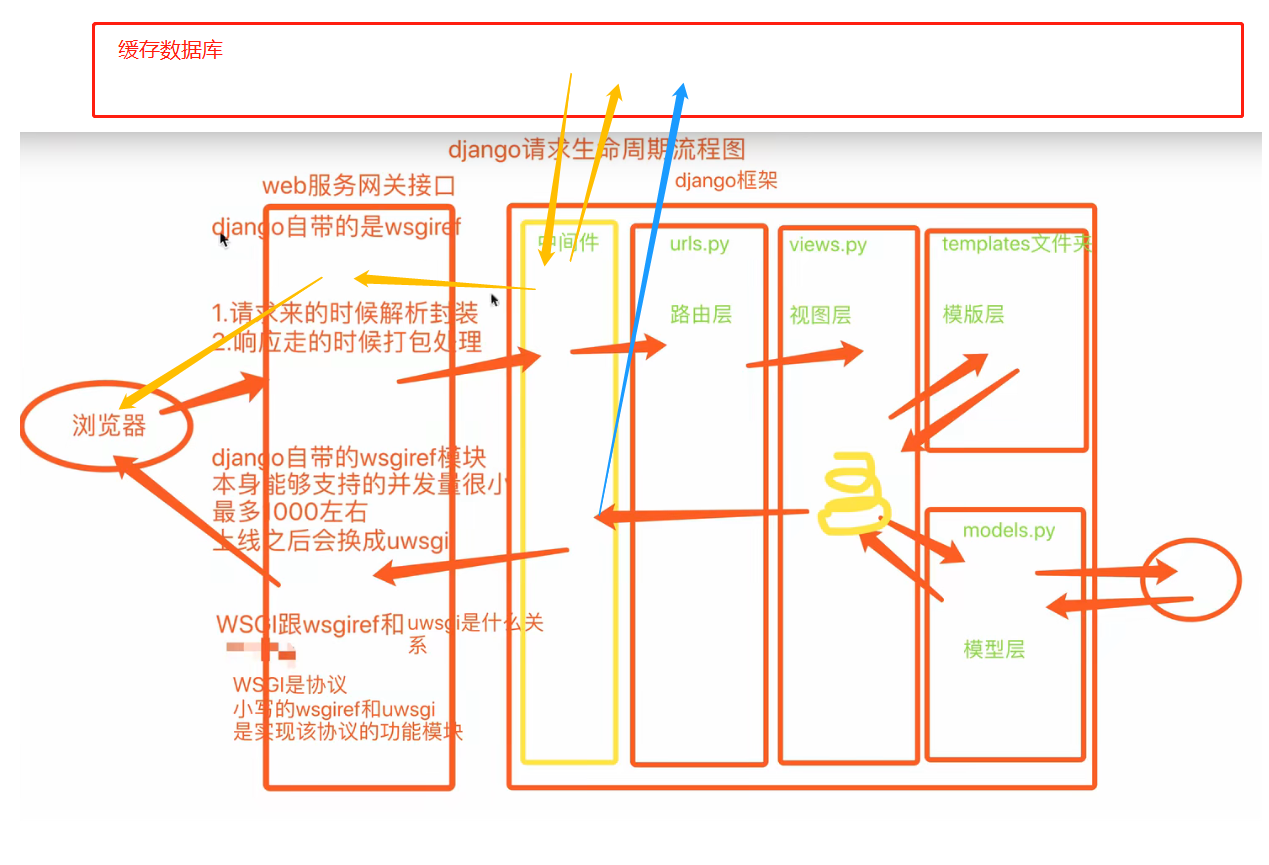
12、Django请求周期流程图
# 浏览器
发送请求
# 第一层:web服务网关接口
swgiref模块:socket服务端
# 第二层:Django框架
# 中间件
# 路由层
urls.py
# 视图函数层
views.py
# 模板层
templates
# 模型层
models.py
1、并行
同时执行任务
2、并发
看起来像是同时执行任务
13、路由层
'''
1、路由匹配:urls.py
url :Django1.x版本的url匹配为正则匹配
:2.x及以上为精准匹配
'''
# 书写:
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin', admin.site.urls),
url(r'^home/', views.home) # 基本书写规则
]
"""
可以将url看成一个函数
第一个参数为正则匹配的规则
自上而下寻找匹配的内容
第二个参数为对应的视图函数
找到匹配内容触发相对应的视图函数
第三个参数
第四个参数
别名:通过解析可以获取相对应的路由地址
"""
# url代码
def url(regex, view, kwargs=None, name=None):
if isinstance(view, (list, tuple)):
# For include(...) processing.
urlconf_module, app_name, namespace = view
return RegexURLResolver(regex, urlconf_module, kwargs, app_name=app_name, namespace=namespace)
elif callable(view):
return RegexURLPattern(regex, view, kwargs, name)
else:
raise TypeError('view must be a callable or a list/tuple in the case of include().')
# url注意事项
url(r'index', views.index) # 这样书写但凡匹配中出现index都执行该视图函数
http://127.0.0.1:8000/indexxxxxxx
http://127.0.0.1:8000/iiiiiindex
url(r'^index', views.index) # 这样书写凡是以index开头的都会被匹配到
http://127.0.0.1:8000/indexxxxxxx
url(r'^index$', views.index) # 精准匹配不出现相对应的字符都不会被匹配到
http://127.0.0.1:8000/index
# 但是这样书写太过于绝对
"""
GET请求的两种传值方式:
方式1:
http://111.1.1.1:8000/index/?a=1
后端:需要在视图函数设置形参
前端:需要匹配相对应的规则
方式2:
http://111.1.1.1:8000/index/1
后端:需要在视图函数设置形参
前端:需要匹配相对应的规则
"""
13.1、无名有名分区
# 分组:将相对应的数据传输到视图函数中
# 无名分组
url(r'index/(\d+)', views.index) # 需要匹配:/index/数字
http://127.0.0.1:8000/index/4 # 同时会将“数字”当成参数传入到后端的视图函数中,需要位置形参接收
def index(request, xx):
print(xx)
return HttpResponse('index')
# 有名分组
url(r'index/(?P<name>\d+)', views.index) # 需要匹配:/index/数字
http://127.0.0.1:8000/index/4 # 同时会将“数字”当成参数传入到后端的视图函数中,需要关键字形参接收
def index(request, name):
print(name)
return HttpResponse('index')
13.2、反向解析
"""
反向解析:
通过一个路由名别得到该别名所在的url完整的地址
路由是可以起别名的
"""
# 书写格式
url(r'^index/', views.index, name='xxx')
# 1、反向解析
# url
url(r'^index/', views.index, name='xxx')
# 后端反向解析
# 需要导入模块
from django.shortcuts import render,HttpResponse, reverse
def index(request):
print(reverse('xxx'))
return render(request,'index.html')
# 前端反向解析
<a href="{% url 'xxx' %}">解析</a>
# 无名分组反向解析
# url
url(r'^index/(\d+)', views.index, name='xxx')
# 后端
def index(request,xx): # xx接收浏览器路径后面携带的参数数据
print(reverse('xxx', args=(1,))) # xxxurl别名,1:相对应的url
print(xx)
return render(request,'index.html')
# 前端
<a href="{% url 'xxx' 123 %}">解析</a> # 数字可以理解为前端向后端发送的数据
# 有名分组反向解析
url(r'^index/(?P<a>\d+)', views.index, name='xxx')
# 后端
def index(request,a):
# 写法1:
print(reverse('xxx', kwargs={'a':4}))
# 写法2:
print(reverse('xxx', args=(4,)))
print(a)
return render(request,'index.html')
# 前端
# 写法1:
<a href="{% url 'xxx' a=123 %}">解析</a>
# 写法2:
<a href="{% url 'xxx' 123 %}">解析</a>
"""
有名无名反向解析无法混合使用
"""
13.3、路由分发
"""
当Django项目越来越大,需要的路由就会越来越多,非常难维护
这时候就会用到路由分发
Django中每个应用都可以有自己相对应的文件
urls.py
templates
static
"""
# 总路由
# 导入模块:include
from django.conf.urls import url, include
from django.contrib import admin
"""
# 使用方式推导1:导入文件名字相同,容易导致代码错乱可以起别名
from app01 import urls
from app02 import urls
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^appp01', include(urls)),
url(r'^appp02', include(urls)),
]
"""
# 使用方式推导2:这样就可以解决相对应的问题
from app01 import urls as app01_urls
from app02 import urls as app02_urls
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^appp01', include(app01_urls)),
url(r'^appp02', include(app02_urls)),
]
# 另外一种使用方式:
# 不需要导入模块:
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^appp01', include('app01.urls')),
url(r'^appp02', include('app02.urls'))
] # 注意:总路由里面的url不能加$符结尾
--------------------------------------------------------------
# 子路由
# app01
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^reg/', views.reg)
]
# app02
from django.conf.urls import url
from app02 import views
urlpatterns = [
url(r'^reg/', views.reg)
]
13.4、名称空间
# 当多个应用出现相同的别名的时候反向解析就没有办法识别
# 解决
# 总路由
url(r'^app01/', include(app01.urls,namespace='app01'))
url(r'^app01/', include(app01.urls,namespace='app02'))
# 子路由
urlpatterns = [
url(r'^reg/', views.reg, name='reg')
]
urlpatterns = [
url(r'^reg/', views.reg, name='reg')
]
# 后端解析
reverse('app01:reg')
reverse('app02:reg')
# 前端
{% url 'app01:reg' %}
{% url 'app02:reg' %}
"""
只要名字不冲突就没有必要使用名称空间
一般情况下,起别名的时候将别名添加上应用前缀即可
urlpatterns = [
url(r'^reg/', views.reg, name='app01_reg')
]
urlpatterns = [
url(r'^reg/', views.reg, name='app02_reg')
]
"""
14、JsonResponse类的使用(JSON格式的数据)
"""
视图函数中的返回值都是继承HttpResponse对象
render redirect HttpResponse
"""
项目开发分类
1、混合项目开发
前端页面与后端代码在一起
2、前后端项目分离
前端是一个应用,后端是一个应用,后端只需要提供一个接口即可
前端与后端数据传输
JSON格式数据:跨语言数据传输
"""
补充:
import json
支持的数据类型:
str list dict set tuple 等基本数据类型
序列化出来的数据:可以看字符串
dumps
loads
dump
load
import pickle
支持的数据类型:
python中所有的数据类型
序列化出来的数据:
都是二进制数据,只能在python中使用
dumps
loads
dump
load
# JS中如何序列化
JSON.stringify() :序列化
JSON.parse() :反序列化
josn模块
json.dumps(ensure_asciii=False) :取消编码
"""
# JsonResponse使用
from django.http import JsonResponse
def index(request):
user_dict = {'user':'xx沙', 'pswd':123}
return JsonResponse(user_dic,json_dumps_params={'ensure_ascii':False}) # json_dumps_params查看源码根据源码填入字典,可以更改显示编码问题
** 在形参与实参中的作用
形参:接收多余的关键字形参
实参:将字典打散以关键字实参的方式传入
form表单上传文件
"""
上传文件注意事项:
前端:
1、必须是post请求
2、form表单参数enctype="multipart/form-data"
后端:
request.FILES :接收文件数据
其他的根据提交方式提取即可
-----------------------------------------------
form表单可以传输的数据格式
1、urkencoded
2、form-data
# 不能提交json格式数据
数据格式
1、urkencoded
2、form-data
3、json
提交json格式数据
方式1:ajax,三种数据格式都可以提交
方式2:第三方工具
postman
apizza
"""
# 获取前端提交的数据格式
# 后端
def index(request):
if request.method == 'POST':
file_obj = request.FILES.get('myfile')
with open(file_obj.name, 'wb') as f:
for i in file_obj:
f.write(i)
return render(request, 'upload_file.html')
# 前端
<form method='post' enctype="multipart/form-data">
<p>文件上传:<input type='file' naem="myfile"></p>
<input type='submit' value='点击'>
</form>
16、CBV和FBV
FBV:function based view
CBV:class bases view
# CBV 必须西继承一个类
from django.views import View
class MyLogin(View):
def get(self, request):
return render(request,'from.html')
def post(self,request):
return HttpResponse('post函数')
--------------------------------------------------------
"""
FBV和CBV各有千秋
CBV特点
能够直接根据请求方式的不同直接匹配到对应的方法执行
"""
---------------------------------------------------------
# CBV源码
# 突破口urls.py中
url(r'^login/',views.MyLogin.as_view())
# url(r'^login/',views.view) # FBV一模一样
# CBV与FBV在路由匹配上的本质是一样的,都是路由 对应 函数内存地址
"""
函数名/方法名 加括号执行优先级最高
猜测
as_view()
要么是被@staticmethod修饰的静态方法
要么是被@classmethod修饰的类方法 被修饰的类方法
@classonlymethod
def as_view(cls, **initkwargs):
pass
"""
@classonlymethod
def as_view(cls, **initkwargs):
"""
Main entry point for a request-response process.
"""
def view(request, *args, **kwargs):
self = cls(**initkwargs) # cls是我们自己写的类
return self.dispatch(request, *args, **kwargs)
"""
再看python源码的时候 一定要时刻提醒自己面向对象属性方法查找顺序
先从对象自己找
再去产生对象的类里面找
之后再去父类找
总结:看源码只要看到了self点一个东西,一定要想清楚当前这个self到底是谁
"""
return view
# CBV精髓
def dispatch(self, request, *args, **kwargs):
# 获取当前请求的小写格式,然后对比当前请求方式是否合法
#
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
"""
getatter:反射:通过字符串来操作对象的属性或者方法
handler = getattr(自己写的类产生的对象,'get\post',当找不到'get\post'属性或者方法的时候就会用第三个参数)
handler = 自己写的MyLogin里面的get\post方法
"""
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
17、模板层
17.1、模板语法之传值
{{ 变量名 }} :变量相关双括号
{% 逻辑 %} :逻辑相关花括号百分号
# 前端
<p>{{ n }}</p>
<p>{{ f }}</p>
<p>{{ se }}</p>
<p>{{ d }}</p>
<p>{{ l }}</p>
<p>{{ t }}</p>
<p>{{ s }}</p>
<p>{{ b }}</p>
<p>{{ func }}</p> <!--模板语法会自动加括号执行函数,但是模板语法不支持给函数传额外的参数-->
<p>{{ MyClass }}</p> <!--传类的时候也会加括号调用即实例化,有参数就不会调用-->
<p>内部能够判断出当前的变量名是否可以加括号调用,如果可以就会加括号调用执行,针对的是函数名和类名,</p>
<p>{{ obj }}</p>
<p>{{ obj.get_class }}</p>
<p>{{ obj.get_func }}</p>
<p>{{ obj.get_self }}</p>
# 后端
def index(request):
# 模板语法已传递的后端数据类型
n = 123
f = 123.123
s = '钱'
l = ['赚', '钱']
d = {'赚钱':' 难啊', '学': '习'}
b = True
se = {'加', '油'}
t = (11, 22, 33)
# return render(request, 'index.html', {}) # 字典一个一个传值
def func():
print('被执行了')
return '可以执行'
class MyClass(object):
def get_self(self):
return 'self'
@staticmethod
def get_func():
return 'func'
@classmethod
def get_class(cls):
return 'cls'
# 对象被展示到html页面上,就类似执行力打印操作,也会触发__str__方法
def __str__(self):
return '打印'
obj = MyClass()
return render(request, 'index.html', locals())
# Django模板语法的取值 是固定的格式,只能采用“句点符”
<p>{{ d.赚钱 }}</p>
<p>{{ l.1 }}</p>
<p>{{ d.字段.2.ff}}</p>
# 既可以点键也可以点索引 还可以两者混用
17.2、模板语法之过滤
# 相当于python中的内置方法
语法:
{{ 变量 | 过滤器:参数 }} # 变量相当于第一个参数,参数相当于第二个
过滤器:# 过滤器中管道符后面最多可以传递参数
1、length
计算长度: {{ str | length }}
2、defalut
默认值:{{ bool | default:'默认值' }}
bool为True,就用bool自己的,如果为False就用'默认值'
3、date
日期:{{ time | date:'Y-m-d H:i:d' }}
4、filesizeformat
文件大小:{{ file | filesizeformat }}
5、safe
h1 = '<h1></h1>'
前端标签:{{ h1 | safe }} # 使标签显示到前端页面
# 后端标签直接显示到前端页面
from django.utils.safestring import mark_safe
hh = mark_safe('<h1>这是标签</h1>')
{{ hh }}
xss攻击:
# 转义:可以书写html代码并执行
# 前端
| safe
# 后端
from django.utils.safestring import mark_safe
res = mark_safe('<h1>大垃圾</h1>')
"""
以后在写全栈项目的时候前端代码不一定非要在前端页面书写
也可以现在后端写好,然后传递给前端页面
"""
17.2、模板语法之标签
在模板中可以使用 if else for
# 需要后端返回前端一个内存地址
# 使用方法
# 后端
def index(request):
lis = [1,2,3,4]
dic = {'字典':'dict','字典1':'dict1'}
return render(request, 'index.html', locals())
# 前端
{% for li in lis %} # 循环列表
<p>{{ li }}</p>
{% if forloop.first %} # 第一次循环first结果True
<p>第一次</p>
{% elif forloop.last %} # 最后一次循环结果为False
<p>最后一次</p>
{% else %}
<p>中间</p>
{% endif %}
{% endfor %}
{% for foo in dic.values %} # 循环字典获取values
<p>{{ foo }}</p>
{% endfor %}
{% for foo in dic.keys %} # 循环字典获取keys
<p>{{ foo }}</p>
{% endfor %}
{% for foo in dic.items %} # 循环items获取键值对
<p>{{ foo }}</p>
{% endfor %}
17.3、模板语法之继承
# 一个页面通过一些方法可以被其他页面继承即使用
# 主页面
{% block '起个名字:h1' %}
其他页面可以继承之后可以更改的代码区
{% endblock %}
# 子页面
{% extends '继承页面的名称' %}
{% block '主页面的可以被更改位置的名字:h1' %}
重新书写代码
{% endblock %}
17.4、模板语法之导入
# 创建一个html页面,内部只写标签代码即可
# 其他页面需要该功能导入该页面即可
导入
{% include '导入模板的名称' %} # 该位置使用的就是之前创建好的模板页面
18、测试环境的搭建
tests.py # 测试脚本文件
# 配置环境
import os
if __name__ == "__main__":
os.environ.setdefault("") # manage.py中的前几行代码
import django
django.setup()
# 书写测试代码,包括各种模块导入
19、ORM查询方式
.all()
查询所有数据,列表的形式展示出来
.first()
查询出第一条数据
.last()
查询出最后一条数据
get()
相当于filter,内部书写条件,但没有就会报错
exclude()
排除括号内书写的条件,相当于取反
order by('条件')
排序,默认升序
降序需要在'-条件'添加符号
reverse()
翻转,经过排序之后翻转才有意义
count()
计数,通过一个条件或者计算所有
exists()
判断某个条件存不存在,返回布尔值
values()
获取指定的字段数据,列表套字典的形式展示出来
values_list()
获取指定的字段,列表套元祖的形式
distinct()
去重,一定不能加主键,可以与values组合使用,给某个字段去重
19.1、基于双下滑线查询
__gt=n
大于n
__lt=n
小于n
__gte=n
大于等于
__lte=n
小于等于
__in=[条件,条件]
SQL语句是 or ,查询某个字段的值是条件1与条件2数据
__range=[条件。条件]
在什么什么之间,between
__contains='条件'
模糊查询,什么字段包含某个条件,默认区分大小写
__icontains='条件'
同上,忽略大小写
__startswith='条件'
模糊查询,什么字段内包含以什么条件开头的数据
__endswith='条件'
模糊查询,什么字段内包含以什么条件结尾的数据
register__time__month='1'
按照月份取出数据,month月
register__time__year='2020'
年取出数据
register__time__day='1'
日
19.2、一对多外键字段的增删改
# 增
方式1:直接书写实际字段 id
models.Book.object.create(title='',price='',publish_id=1) # 直接书写外键外键字段添加对应的值即可
方式2:虚拟字段,直接传入数据对象,内部会自动找到当前对象所对应的主键值,然后写入数据
publish_obj = models.Publish..object.filter(pk=).first()
models.Book.object.create(publish=publish_obj)
# 删
models.Publish.object.filter(pk=2).delete() # 级联删除
# 清空
book_obj = models.Publish.object.all()
book_obj.publish.clear()
# 改
方式1:
models.Book.object.filter(pk=1).update(字段='新数据')
方式2:
publish_obj = models.Publish.object.filter(pk=1).fiser
models.Book.object.filter(pk=1).updata(publish=pubish_obj)
19.3、多对多的增删改
多对多的增删改查就是操作第三张关系表
# 增
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors # 就类似于已经跨到了第三张表
book_obj.authors.add(1) # 给书籍主键为1的书籍绑定一个主键为1的作者
book_obj.authors.add(1,2) # 给书籍主键为1的书籍绑定一个主键为1,2的作者
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
author_obj2 = models.Author.objects.filter(pk=3).first()
book_obj.authors.add(author_obj, author_obj1, author_obj2)
"""
add:给第三张关系表添加数据
括号内既可以传数字,也可以传对象,都支持多个
"""
# 删
# 方法1:
book_obj = models.Book.objects.filter(pk=2).first() # 获取书籍对象
book_obj.authors.remove(2) # 删除这个书籍对象的多对多的关系表中对应的关系id
# 方法2
book_obj = models.Book.objects.filter(pk=2).first()
author_obj2 = models.Author.objects.filter(pk=3).first() # 获取书籍对象
book_obj.authors.remove(author_obj2) # 操作书籍对象删除对应的书籍对象参数,支持多个参数删除
# 方法3
# 清空,不需要传参数
book_obj.authors.clear()
# 改
# 方式1
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.set([1, 2])
# 方式2
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.set([author_obj, author_obj1])
"""
set:括号内必须是可迭代对象,该对象可以是数字,也可以是对象,支持多个
顺序:先删除所有,在添加
注意:在修改数据的时候需要将修改的和不修改的全部写入,不然数据就会只剩下修改的了
"""
# 清空
# 在第三张清空某个书籍与作者的绑定关系
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.clear()
"""
clear():括号内不需要添加数据
"""
set():括号内必须是可迭代对象,支持多个
add():括号内可以是数字即对应的id,和对象,支持多个
remove():可以是id数字,也可以是对象
clear():清空,括号内不需要数据
19.4、多表查询-基于对象的跨表查询(子查询)
"""
基于正向查询
当结果可能有多个的时候需要加.all()
如果数据是多个的时候就不需要点.all()
"""
"""
基于对象反向查询
当查询结果可以有多个的时候需要加_set.all()
当结果只有一个的时候不需要加_set.all()
即反向查询一对一表关系就不用加set
"""
# 正向
book_obj = models.Book.oobject.filter(pk=1).fiser() # 获取书籍对象
res = book_obj.publish # 跨到另一张表中,res 就是publish对象
res.name # 对象 点数属性查询结果
book_obj = models.Book.object.filter(pk=1).first()
res = booK_obj.authors.all().first() # 跨到另外一张表中,取出所有对象中的第一个对象
res.name # 对象 点属性
# 反向
author_obj = models.Author.objects.filter(pk=1).first()
author_obj.booK_set.all() # 所有的对象
19.5、基于双下划线跨表查询(连表查询)
正向
res = models.Author.objects.filter(pk=1).values('自己的字段__对应表的字段') # 通过values字段 双下划线找出对应表的字段即可
反向
models.Publish.objects.filter(book__id=1).values('name') # 通过filter过滤对应的表 双下划线 对应的数据,在通过values找出对应的字段
19.6、F与Q
# F查询就是可以拿到数据库原有的数据
# 1、导入模块
from django.db.models import F
"""F查询默认是针对数字类型数据"""
models.Book.object.filter(price=F('price')+100) # F内获取当前字段的值,进行运算,然后更改
"""设置针对字符类型"""
from django.db.models.functions import Concat
from django.db.models import Value
models.Book.objects.udate(title=Concat(F('title'),value('拼接的字符')))
# Q查询简单使用就是 将过滤条件变成 或 or 的关系
from django.db.models import Q
models.Book.objects.filter(Q(字段=条件), Q(字段=条件)) # 逗号分割还是 and 关系
models.Book.objects.filter(Q(字段=条件) | Q(字段=条件)) # 更改为管道符 | 才会变成 或 or 的关系
models.Book.objects.filter(~Q(字段=条件), Q(字段=条件)) # Q前面加上 波浪 ~ 代表当前 Q 的条件是取反,多个就额外添加,或者将取反的过滤条件括起来前面加 ~
models.Book.objects.filter(~(Q(字段=条件), Q(字段=条件)) # 内部全部取反
# Q 的高阶用法 能够将查询条件左边也变成字符串的形式
q = Q()
q.connector = 'or' # 更改Q里面的链接条件为 or
q.children.append(('maichu__gt',100)) # 支持内服放字符串类型数据
q.children.append(('price__lt',700))
res = models.Book.objects.filter(q) # filter内部支持放Q对象,默认还是and关系
print(res)
19.7、聚合查询
MySQL聚合查询
max min count avg sum
#聚合查询
from django.db.medels import Max, Min, Sum, Count, Avg
# ORM中使用聚合查询关键字:aggergate()
res = models.Book.objects.aggregate(max_prcie=Max('price'))
# max_price起别名,配合value使用
res = models.Book.objects.aggregate(max_prcie=Max('price'),min_price=min('price'))
# 可以继续添加聚合函数。
19.8、分组查询
MySQL支持多个字段分组
先以最左侧进行分组,之后向右进行二次分组
MySQL5.6版本之前需要自定义sql_mode严格模式
sql_mode = 'only_full_group_by'
1、group_coucat:分组之后
2、concat:分组之前
3、concat_ws:
"""
select concat(title,":",age) from t
select concat_ws(':', title,atg) from t
"""
# ORM中使用分组关键字:annotate()
res = models.Bool.objects.annotate()
# 按照书籍分株
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('title', 'author_num')
# 按照别名查询
res = models.Book.objects.annotate(author_num=Count('authors')).values('title', 'author_num')
# pk或者id可以不写,但不见名知意
20、事物
"""
四大特性:ACID
事物的隔离级别:
"""
MySQL
1、开启事务
start transactions
2、提交事物
commoit
3、回滚事物
rellback
# 尽量在事物中书写SQL语句,少些业务逻辑
# Django开启事务
from django.db import transactions
try:
"""执行的SQL语句"""
with transactions.Atomic # 开启事物
# sql1
# SQL2
# 这里写的都是同一个事物
except Exception as e:
print(e) # 实际是日志,查看日志找到错误原因
transactions.rollback() # 失败之后回滚
21、ORM中常见的参数
null=True 某个字段可以为空
unique=True 唯一索引
db_index 普通索引
default 默认值
auto_now_add 创建记录自动添加当前时间
ForeignKey 建立外键
to 与哪个表存在外键关系
to_field 与哪个字段建立外键(不写默认id字段)
related_name 反向操作时自定义字段名
related_query_name 反向查询替换表名
on_delete 级联更新 Django 2.x之上需要手动设置
on_delete=models.CASCADE
through_fields
db_table 更改数据库表名可以取消应用名前缀
22、choices参数
eg:
姓别
姓名
# 针对可以列举完全的可能性,可以使用choices参数
class User(models.Model):
name = models.CharField(max_length=32)
gender_choices = (
(1,'男'),
(2,'女'),
(3,'其他')
)
gender = models.IntegerField(choices=gender_choices)
# 存入数据
models.User.objects.create(name='xx', gender=1)
models.User.objects.create(name='xx', gender=2)
models.User.objects.create(name='xx', gender=3)
models.User.objects.create(name='xx', gender=4)
# 查询
res = models.User.objects.filter(pk=1).first()
res.gender # 存的是什么取出来的就是什么 1
res.get_gender_display() # 获取相对应的数据,如果数据不存就在取出原始数据
.get_字段名_display()
23、批量增加数据
book_list = []
for i in range(10000):
book_obj = models.Book(title='title')
book_list.append(book_obj)
models.Book.objects.bulk_create(book_list)
# 通过bulk_create()
24、多对多三种关系创建
# 全自动
利用ORM创建第三张虚拟表
"""
优点:
代码不需要自己写,方便,支持ORM提供的第三张表关系方法
add remove 等
缺点:
没有扩展性
"""
# 纯手动
# 自己创建第三张关系表,与另外两张表进行关系绑定
"""
优点:
第三张表字段取决于自己
缺点:
代码书写多,没办法使用ORM提供的方法
"""
# 半自动
class Book(models.Model):
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',
through='Book2author', # 告诉ORM这个表是多对多的关系的第三张表
through_fields=('book', 'author') # 告诉ORM第三张表中哪两个字段是关联的,参数位置:当前这个表是谁,就把这个表的字段放在前面
)
"""
through_fields=('book', 'author'):字段判断本质
通过第三张表查询对应的表需要用到哪个字段就把哪个字段放在前面
"""
class Author(models.Model):
name = models.CharField(max_lengeh=32)
class Book2Author(models.model): # 自己创建第三张表
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
"""
优点:可以使用ORM正反向查询,但是没办法使用,add,set,remove,clear四个方法
"""
25、cookie与session
1. 很久以前,网站都是静态的,eg: 新闻类,博客类
# 静态网站不需要登录
2. 随着发展,后续诞生了支付宝,购物网站...
# 动态网站需要登录
3. HTTP协议的特点:
3.1 无状态
诞生了保存用户数据的cookie,session,token
4. cookie介绍
'''
cookie把数据保存在浏览器上,以登录功能为例,cookie的工作原理
当用户第一次登录成功之后,django后端把用户数据保存在浏览器上,浏览器会自动把用户数据提交到django后端,django接收传过来的用户信息,再次做验证,如果正确,则正常登录
'''
# 用户名和密码存在浏览器上,不安全
5. 为了解决浏览器数据不安全问题,诞生了session
'''
session解决的是安全问题,把数据保存在后端,在django中,session把数据保存在数据库中(默认保存的),session会把数据保存在django生成的django_session表中、
工作原理:
当用户第一次登录成功之后,django会自动生成一个随机字符串,与用户的真实信息做一个对应:
随机字符串1:用户信息1
随机字符串2:用户信息2
随机字符串3:用户信息3
django会把随机字符串返回给浏览器,说白了,把随机字符串保存在cookie里了,当用户再次进入网站的时候,浏览器会自动把随机字符串提交过来,django会拿着随机字符串去django_session表中查找对应的信息,如果有,则说明已经登录了,如果没有,说明没有登录、
'''
6. session是基于cookie工作的?正确
7. 如果用户主动进制了cookie,那么,session就一定不能用了?不是
7.1 把随机字符串以参数的形式提交到django
7.2 把数据放到请求头中
总结:
1. cookie的数据保存在浏览器
2. session的数据保存在数据库,session的保存位置是可以更改的:
2.1 文件
2.2 数据库
2.3 redis
2.4 memcache
2.5 消息队列
3. 专业的消息队列工具:
3.1 kafka
3.2 rabbitmq
3.3 HTTPsqs
4. session是基于cookie工作的
25.1、Django操作cookie与session
cookie
1. obj = HttpResponse()
2. obj = redirect
3. obj = render
# django要想操作cookie,就必须借助于HttpResponse
eg:
登录功能
'''设置cookie'''
obj = HttpResponse('登录成功')
# 保存数据到cookie
obj.set_cookie('username', userinfo.username, max_age=120)
obj.set_cookie('id', userinfo.id)
'''获取cookie'''
request.COOKIES.get('username'):
session
# 设置session
request.session['key'] = values
# 获取session
request.session.get('key')
# 注销session
request.session.delete()
or
request.session.flush()
def set_session(request):
request.session('username') = 'kk'
return HttpResponse('设置成功')
def get_session('request'):
res = request.session.get('username')
return HttpResponos('获取成功')
26、分页器
#
总数据100
每页展示10条
100 10
101 11
99 10
class Pagination(object):
def __init__(self, current_page, all_count, per_page_num=2, pager_count=5):
"""
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page < 1:
current_page = 1
self.current_page = current_page
self.all_count = all_count
self.per_page_num = per_page_num
# 总页码
all_pager, tmp = divmod(all_count, per_page_num)
if tmp:
all_pager += 1
self.all_pager = all_pager
self.pager_count = pager_count
self.pager_count_half = int((pager_count - 1) / 2)
@property
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
def page_html(self):
# 如果总页码 < 11个:
if self.all_pager <= self.pager_count:
pager_start = 1
pager_end = self.all_pager + 1
# 总页码 > 11
else:
# 当前页如果<=页面上最多显示11/2个页码
if self.current_page <= self.pager_count_half:
pager_start = 1
pager_end = self.pager_count + 1
# 当前页大于5
else:
# 页码翻到最后
if (self.current_page + self.pager_count_half) > self.all_pager:
pager_end = self.all_pager + 1
pager_start = self.all_pager - self.pager_count + 1
else:
pager_start = self.current_page - self.pager_count_half
pager_end = self.current_page + self.pager_count_half + 1
page_html_list = []
# 添加前面的nav和ul标签
page_html_list.append('''
<nav aria-label='Page navigation>'
<ul class='pagination'>
''')
first_page = '<li><a href="?page=%s">首页</a></li>' % (1)
page_html_list.append(first_page)
if self.current_page <= 1:
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)
page_html_list.append(prev_page)
for i in range(pager_start, pager_end):
if i == self.current_page:
temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)
else:
temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)
page_html_list.append(temp)
if self.current_page >= self.all_pager:
next_page = '<li class="disabled"><a href="#">下一页</a></li>'
else:
next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)
page_html_list.append(next_page)
last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)
page_html_list.append(last_page)
# 尾部添加标签
page_html_list.append('''
</nav>
</ul>
''')
return ''.join(page_html_list)
27、CBV添加装饰器
from django.views import View # 使用CBV需要导入的模块
from django.utils.decorators import method_decorator # CBV添加装饰器需要导入的模块
@method_decorator(login_auth,'get') # 使用哪个装饰器,给哪个方法添加
class MyLogin(View):
@method_decorator(login_auth) # 使用哪个装饰器,给所有方法添加
def dispatch(self, request, *args, **kwargs):
return super.dispatch(request, *args, **kwargs) # 自身的dispatch执行结束之后调用父类的dispatch方法
def get(self, request):
return HttpResponst('get')
28、中间件
中间件是用来做什么的
1、校验限制
2、限制访问评率
3、检查认证
# 自定义中间件
1、在任意一个应用下创建一个py文件
2、在py文件中写一个类并继承MiddlewareMixin
3、中间件写完之后在配置文件中注册中间件
from django.utils.deprecation import MiddlewareMixin # 导入固定模块
class MyMiddleware(MiddlewareMixin):
# 请求来的时候,多个中间件都会先执行request
def process_rquest(self, request):
pass
# 请求走的时候,多个中间件都会等待视图函数执行完毕之后执行response
def process_response(self, request):
return response # process_response必须返回一个response对象
29、csrf跨站请求
钓鱼网站:伪造网址向正规网址发送请求。
form表单提交post请求时内部添加:{% csrf_token %}
Ajax发送post请求时内部添加:1、{'csrfmiddlewaretoken':'$([name="csrfmiddlewaretoken"])'} # 通过选择器获取对应的csrf值
2、{'csrfmilewaretoken':'{{ csrf_token }}'}
30、csrf相关装饰器
"""
如果使用了中间件那么所用post请求全部都会是受限制的,那么怎么才可以固定哪些视图函数可以受限制或者没有csrf中间件时收到限制呢
"""
两个装饰器:
1、csrf_protect:需要验证
2、csrf_exempt:不需要验证
需要导入模块
from django.views.decrators.csrf import csrf_protect, csrf_exempt
FBV:
@csrf_protect # 需要验证
def index(request):
return HttpResponse('需要验证')
@csrf_exempt
def home(request):
return HttpResponse('不需要验证')
CBV:
from django.views import View # CBV模块
from django.utils.decorators import method_decorator # CBV使用模块装饰器
@method_decorator(csrf_protect,'post') # 方式1:可以使用protect
@method_decorator(csrf_exempt,'dispatch') # 方法1:需要指定dispatch才可以使用
class Mycsrf(View):
@method_decorator(csrf_protect) # 方法2:可以使用protect
@method_decorator(csrf_exempt) # 方法2:可以使用exempt
def dispatch(self, request, *args, **kwargs):
return super().dispatch(request, *args, **kwargs) # 重新使用父类的该方法
@method_decorator(csrf_protect) # 方法2:可以使用protect
@method_decorator(csrf_exempt) # 方法2:没办法使用exempt
def post(request):
return HttpRespose('xx')
31、auth
结合了注册,登录,登录状态保存,退出功能
1、注册
User.objects.create() # 创建普通明文密码用户
User.objects.create_user() # 创建普通密文密码用户
User.objects.create_superuser() # 创建超级用户
2、登录验证
user_obj = auth.authentucate(request,username=username, password=password) # 校验账号秘法是否正确,有返回值,正确返回用户对象,不正确返回匿名用户
3、保存登录状态
auth.login(request, user_obj) # 添加request和用户对象
4、验证是否登录
request.user.is_authenticate() # 返回布尔值
5、获取当前登录用户对象
request.user
6、校验用户是否登录装饰器
from django.contrib.anth.decorators import ingin_requires
全局配置:settings --> LONGIN_URL='/路径/' # 没有登录跳转指定路径
局部配置:@login_required(login='/指定路径/') # 在需要的视图函数上面添加然后指定路径即可
@login_required # 这样添加装饰器没有登录则直接报错
当全部都设定的时候按照视图函数上面的指定为标准
7、密码校验
is_reght = request.user.check_password(密码) # 自动校验密码,返回布尔值
8、修改密码
request.user.set_password(密码) # 写入新密码,但只是修改对象数据,
request.user.save() # 真正的保存到数据库
9、注销登录
auth.logout(request) # 注销到当前用户的cookie
Django操作数据库的SQL语句查看
# 此条配置添加扫settings.py的配置文件中
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
分类:
Django


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署