
MySQL
数据演变史
# 1、单独文本文件(文件操作)
没有固定的存放位置和格式
文件名:user.txt userinfo.txt
数据格式:kk|123 ll|123
"""
程序彼此之间没办法兼容
"""
# 2、软件开发目录规范
规定了文件名和储存位置
"""
文件查找变得简单了
并没有解决核心问题(兼容)
"""
# 3、数据库阶段
规定了文件的储存位置和数据格式
"""
目前正在使用的阶段,解决了核心问题
"""
数据储存发展史
# 1、单机游戏阶段
数据各自保存在各自的计算机,无法实现共享
# 2、多机游戏阶段
数据同一保存在某个固定的服务器上(计算机)实现数据共享
前提:必须有网
"""
为了数据的安全,还会采用集群的策略来分担风险
"""
数据库的本质
# 本质:c/s架构的软件
既然数据库的本质是cs架构的软件,也就意味着我们每个人都可以编写一个数据库软件
目前很多大牛都具有编写数据库软件的能力,而且市面上有很多数据库的软件
"""
数据库在狭义层面来说
值得是处理数据的代码(程序)(底层程序)
数据库在广义层面上来说
值得是操作这些底层程序的快捷应用软件
"""
需要基于网络交互
其实学习数据库很多时候学习的就是配套的数据库软件
数据库的分类
# 市面上面众多数据库大致分为两类
关系型数据库:
MySQL :免费开源,使用非常广泛
Oracle :安全性极高,收费
PostgreSQL :支持二次开发,提供给用户接口
MariaDB :与MySQL同一作者,可以看成MySQL替代产品(有自己的特性)
sqlite :小型数据库(Django自带该数据库)
sql server :
db2 :
关系型数据库:
Redis :目前使用频率最高的缓存数据库,具有很多数据结构,功能强大
MongoDB :文档型数据库,可以用在大数据层面,爬虫领域
memcache :几乎被Redis淘汰
# 1、两大类数据库有什么不同?
关系型数据库:拥有固定关系的表结构,并且表与表之间可以创建代码层面的关系
非关系型数据库:没有固定的表结构,数据的储存采用K:V键值对的形式
# 2、学习
两大类型的数据库操作逻辑基本一直,每一类学习一个,其他的就会学习很快
SQL与NoSQL
# 数据库核心:存取数据
# 数据库的服务端为了能够兼容不同的客户端实现数据交互,所以使用SQL语句。
SQL:关系型
各种语言通过SQL语句操作关系型数据库
NoSQL:非关系型
各种语言通过NoSQL语句操作非关系型数据库
MySQL
主要版本:
5.6:目前市面上使用的最高
5.7:目前过度版本
8.x:目前最新的版本,功能强大
"""
不同的版本只是底层逻辑有所区别,SQL语句几乎都是一模一样
"""
下载安装:
mac:https://www.cnblogs.com/Dominic-Ji/articles/15402755.html
windows:瞪大眼睛看
访问官网:https://www.mysql.com/
具体步骤:
DOWNLOADS
MySQL Community (GPL) Downloads
MySQL Community Server
Archives
选择版本下载压缩包(客服端 服务端)
目录介绍:
bin文件夹
mysqld.exe :服务端
mysql.exe :客户端
data文件夹
储存使用过程中需要保存的数据
my-default.ini
配置文件
readme
说明文件
基本使用:
# 一定要先启动服务端,在启动客户端
"前期操作的时候最好使用管理员操作cmd"
1、将bin文件夹添加到环境变量即可
2、管理员cmd中输入:mysqld 启动服务端
3、开设新的cmd窗口,连接服务端
mysql # 直接链接是游客模式登录
mysql -u用户名 -p密码 # 账号登录(本地使用)
默认管理员没有密码,直接回车即可
mysql -hIP地址 -P端口号 -u用户名 -p密码 # 完整登录方式
# 如果存在报错直接百度即可。
MySQL下载
MySQL下载:
windows:5.6版本压缩包
Linux:8.x版本压缩包
macOS:8.x版本压缩包
系统服务
# 将MySQL的服务端做成系统服务,开机自启动
1、关闭当前服务端
2、以管理员身份运行cmd
3、输入:mysql --install # 添加到系统服务
4、查看启动
方式1:
services.msc # 查看当前计算机系统服务
找到mysql,鼠标右键启动即可
方式2:
在cmd窗口输入:net start mysql
"""
停止服务
net stop mysql
移除系统服务
mysql --remove
"""
密码相关
# root用户首次登录没有密码
针对管理员用户设置密码:
方式1:直接在cmd窗口使用mysqladmin命令
mysqladmin -uroot -p原密码 password新密码
方式2:直接在登录状态下修改当前登录的用户密码
set password=PASSWORD('新密码')
# 忘记密码如何解决
1、关闭当前服务端
2、以跳过授权方式重新启动服务端
只需要提供用户名就可以登录
mysql --skip=grant-tables # 启动服务端
3、以管理员身份登录
mysql -uroot -p
4、修改管理员用户密码
update mysql.user set password=password(新密码) where user='root' and host='localhost'
5、关闭服务端在正常启动服务
ctrl c
net start mysql
6、使用修改之后的密码登录
重要概念介绍
关系型数据库概念:
库 文件夹
表 文件夹里面的文件
记录 文件夹里面文件里的一行行数据
基本SQL语句
"""
SQL语句的结束必须使用结束符 分号 ;
"""
1、查看数据库所有的名称:
show databases; # 查看出来的内容比文件夹多出一个,默认会有一个临时产生在内存的库in...sc
2、查看某一个库内所有表的名称:
use 库名 # 切换到某个数据库(类似双击文件夹进入)
show tables; # 查看当前库下所有的表(当前文件夹内所有的文件)
3、如何查看所有的记录(数据)
select * from 表名; # 查看这张表内所有的数据
select * from 表名\G; # 如果内容较多展示错乱,可以在语句后面添加 \G
针对库的基本SQL语句
1、增
create database 库名; # 添加数据库
2、查
show databases; # 查询所有的库
show create database 数据库名; # 定向查看某个库,可显示出某个库的字符编码
3、改
alter database 数据库名 charset'gbk' # 更改某个库的字符编码
4、删
drop database 数据库名; # 删除某个数据库
5、当前所在的库
select database();
针对表的SQL语句
"""
想要操作表,必须在库内
"""
1、增
"关系型数据库创建表,一定要有字段"
create table 表名(字段名 字段类型,字段2 类型2);
2、查
show tables; # 当前库下所有的表名
show create table 表名; # 查看指定的表信息
describe 表名; 查看表的具体信息(常用)
desc 表名;
3、改
alter table 原名字 rename 新名字; # 更改表名
alter table 表名 change 原字段名 新字段名 新类型; # 修改字段名和类型
alter table 表名 modify 字段名 新类型; # 修改字段类型
4、删
drop table 表名; # 删除
针对记录的SQL语句
"""
先确定库,然后表,最后记录
"""
1、增
insert into 表名 values(数据,数据,数据); # 表中添加记录,数据跟随字段而定,单条数据
insert into 表名 values(数据,数据),(数据,数据),() # 多条数据
2、删
select from 表名 where 筛选条件; # 没有条件就是删除所有
3、改
update 表名 set 字段名='新的数据' where 筛选条件; # 更改字段信息
4、查
select * from 表名; # 查询表中所有数据
字符编码问题
# 查看MySQL内部默认的编码情况
\s
"""MySQL默认的配置文件>>>:mydefault.ini"""
1、拷贝默认的配置文件并且重新命名为:my.ini
2、拷贝固定的信息
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
# 这是针对客户端
[client]
default-character-set=utf8
# 这是针对其他语言的客户端
[mysql]
default-character-set=utf8
# 这是针对自身客户端
user=root
password=123
# 设置之后可以直接在cmd窗口不输入密码就可以以root用户登录
3、重启MySQL服务端
存储引擎
# 储存引擎可以看成处理数据的不同方式
# 查看储存引擎的方式
show engines;
# 四个中存储引擎
MyISAM
MySQL 5.5之前默认的存储引擎
不支持事物,行级锁,外键(forrign keys)针对数据的操作较于innodb不够安全
但是数据的存取速度要快于innodb
InnoDB
MySQL 5.5之后默认的存储引擎
支持事务,行级锁,外键针对数据操作更加安全
BLACKHOKE
写入其中的数据都会立即消失,类似于垃圾处理站
MEMORY
基于内存存取数据
处理数据最快,但是断电数据立即消失
# 存储引擎创建表的不同点
关键字:myisam
create table t1(id int) engine=myisam;
create table t2(id int) engine=innodb;
create table t3(id int) engine=memory;
create table t4(id int) engine=blackhole;
"""
myisam会创建三个文件夹
.frm 表结构文件
.MYD 表数据文件
.MYI 表索引w文件(索引是加快数据查询的)
InnoDB会创建两个文件
.frm 表结构文件
.ibd 表数据和表索引文件
memory
.frm 表结构文件
blackhole
.frm 表结构文件
"""
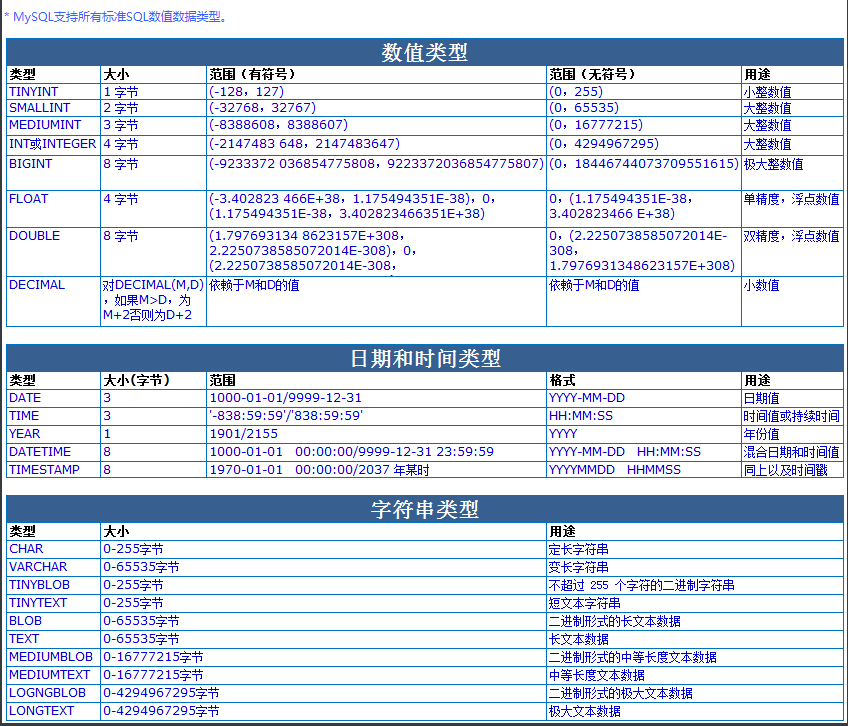
MySQL基本数据类型
整形,浮点型
# 整形
tinyint smallint int bigint
上述不同的int类型能够储存的水范围是不一样的
1、要注意是否存负数
2、手机号只能用bigint
"""
默认是需要正负号的
"""
create table t1(id tinyint);
insert into t1 values(-999),(999);
储存结果:-128,127
# 结论:所有int类型默认都是需要正负号的
create table t2(id tinyint unsigned) # unsigned默认移除负号 -
# 浮点型
float double decimal
float(255,30) # 总共255位,小数位置30位
double(255,30) # 总共255位,小数30
decimal(65,30) # 总共65为,小数30
"""三者有何不同"""
create table t1(id float(255,30));
create table t2(id double(255,30));
create table t3(id decimal(65,30));
insert into t1 values(1.11111111111111);
insert into t2 values(2.22222222222222);
insert into t3 values(3.33333333333333);
结果 :1.111111164093017600000000000000
:1.111111111111111200000000000000
:1.111111111111111111111111100000
总结:精确度不同>>>float < double < decimal
"""
根据实际应用情况选择不同的类型即可
"""
字符类型
# 字符类型
char(n)
定长类型:最多只能存n个字符,不够空格填充到n个,超出直接报错
varchar(n)
变长类型:最多可以储存n个,不够存几个就是几个,超出报错
"""上述特征超出测试"""
create table t5(name char(4));
create table t6(naem varchar(4));
insert into t5 values('ppppp');
insert into t6 values('lllll');
"""
结果:
| name |
+------+
| pppp |
+------+
| naem |
+------+
| llll |
+------+
# 针对5.6版本超出范围不会报错,但会自动截取,然后保存(这种行为非常不合理)
"""
上述结果非常不合理,所以需要更改配置:
方式1:直接修改配置文件(永久生效)
方式2:命令修改(临时生效)
show variables like 'mode' # 查看当前类型
sql_mode | NO_ENGINE_SUBSTITUTION
set session # 当前窗口生效
set global # 当前服务端有效
set global sql_mode = 'strict_trans_tables'; # 更改之后重启当前窗口
重新输入:
mysql> insert into t6 values('ooooo');
ERROR 1406 (22001): Data too long for column 'naem' at row 1
mysql> insert into t6 values('oooo');
Query OK, 1 row affected (0.00 sec)
# 修改完成之后超出范围就会报错
"""定长与变长"""
insert into t5 values('q');
insert into t6 values('a');
# 统计某个字段的长度>>>:char_length()
select char_length(name) from t6;
需要重新设置sql_mode配置:
set global sql_mode = 'strtic_trans_tables,pad_char_to_full_length' # 记得退出重新登录
mysql> select char_length(name) from t8 where id=1;
+-------------------+
| char_length(name) |
+-------------------+
| 4 |
+-------------------+
1 row in set (0.00 sec)
mysql> select * from t8;
+------+------+
| id | name |
+------+------+
| 1 | a |
+------+------+
1 row in set (0.00 sec)
char与varchar对比
char
优势:整存整取,速度快
劣势:浪费储存空间
varchar
优势:节约储存空间
劣势:存取速度较char慢
varchar:存数据时会创建一个bytes的报头,取数据时查看报头进行判断取多少
补充:字段注释关键字:comment
create table t1(
id int comment '序号',
name char(32) comment '姓名'
)
整形中括号内 数字的作用
create table t1(id int(3));
insert into t1 values(11111111);
"""
在整形中括号内的数字并不是用来限制储存长度的,而是用来控制展示的长度的,不够用0填充
"""
# 总结:整形比较特殊,是唯一一个括号内不是用来限制储存长度的类型
枚举与集合类型
枚举
多选一
enum()
create table user(
id int,
name varchar(32),
gender enum('male','female')
);
insert into user values(1,'pp','ll'); # 会报错
insert into user values(1,'pp','male') # 正常
集合
多选多
set()
cerate table userinfo(
id int,
name varchar(32),
hobby set('basketball','football')
);
insert into userinfo(1,'pp','ll'); # 报错
insert into userinfo(1,'pp','basketball'); # 正常
insert into userinfo(1,'pp','basketball','football'); # 正常
日期类型
data 年月日
time 时分秒
datatime 年月日十分秒
year 年
create table tt(
id int,
name varchar(32),
reg_time data,
birth datatime,
study_time time,
join_time year
);
创建表的完整语法
create table 表名(
字段 字段类型 约束条件,
字段 字段类型 约束条件,
字段 字段类型 约束条件
);
"""
1.字段名和字段类型是必须的
2.数字和约束条件是可选的 并且 约束条件可以有多个空格隔开即可
3.最后一个语句的结尾不要加逗号
"""
约束条件
# 新增表数据的方式:
方式1:按照字段位置一一传值
insert into 表名 values(数据,数据);
方式2:自定义传值顺序,甚至不传
insert into 表名(字段2,字段1) values('字段2数据','字段1数据');
insert into 表名(字段2) values('字段2数据'); # 字段1就没有传值
在MySQL中不穿数据 会使用关键NULL填充,意思就是空
# 约束条件相当于在字段类型基础上添加额外的约束
unsigned 让数字没有正负号
zerofill 多余的使用数字0填充
not null 非空
"""
当创建表字段的时候 添加了约束条件 not null之后,该字段就不能出入空,会报错
"""
create into 表名(
id int not null,
name varchar(32) not null
);
default 默认值
"""
所有字段都可以添加默认值
当字段不传值得时候就会使用默认值,否则就使用传入得数据
"""
create table 表名(
id int default 111,
name varchar(32) default 'pp'
);
# 不传值得时候就会使用 id 111, name pp
unique 唯一值
"""
单列唯一
create table 表(
id int unique,
name varchar(32) unique
);
# id name两个字段都是不可以重复的
联合唯一
create table 表(
id int,
host varchar(32),
port int,
unique(host,port)
);
# host,port 两个字段数据单个可以重复,多个重复就不可以。
"""
primary key 主键
"""
单从约束从面上来说,相当于是 not null + unique(非空且唯一)
在此基础上还可以加快数据查询
InnoDB存储引擎规定了一张表必须有且只有一个主键
因为InnoDB是通过之间的方式来构造表的
如果没有主键
情况1:没有主键和其他约束条件
InnoDB会采用隐藏的字段作为主键 不能加快数据的查询
情况2:没有主键但是有非空且唯一的字段
自动将该字段升级为主键
create table 表(
id int not null unique,
age int,
);
# 此时id 字段就会自动升级为主键
在创建表的时候一定要设置主键(一般表的主键为id字段)
create table 表(
id int primary key,
name varchar(32)
);
"""
auto_increment 自增
"""
由于主键类似数据的唯一标识 并且主键一般都是数字类型
在添加数据的时候不可能记住接下来的序号是多少,所有可以使用自增,并且添加到主键,主键自增。
"""
create table 表(
id int primary key auto_increment,
name varchar(32)
);
# 此时id字段就是主键自增
自增的特性
自增不会应为删除操作而退回
delete from 无法影响自增
如果想要重置需要使用truncate关键字
truncate 表名 # 清空表数据并且重置主键值
外键(约束条件)
什么是外键?
标识表与表之间的数据关系
为什么使用外键?
当一张表出现的信息包含各种重复的内容,数据冗余,不利于查询等。
表与表之间有什么关系?
一对多
多对多
一对多
没有关系!!!
判断表与表关系:换位思考
外键约束
1、创建表的时候 需要先创建被关联表(没有外键字段的表)
2、在插入新数据的时候 应该确保被关联表中有数据
3、在插入新数据的时候 外键字段只能填写被关联表中已经存在的数据
4、在修改和删除被关联表中数据的时候 无法直接操作
如果想要数据之间自动修改和删除需要添加额外的配置级联更新,级联删除
关键字:
on update cascade
on delete cascade
创建:
create table dep(
id int primary key auto_increment, # 设置主键和自增
dep_name varchar(32),
dep+desc varchar(255)
); # 先创建被关联表
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep(id)
on update cascade # 级联更新
on delete cascade # 级联删除
); # 注:for之后属于同一行
"""
由于外键有实质性的诸多约束 当表特别多的时候外键的增多反而会增加耦合程度
在开发项目中有时候并不会使用外键创建表关系
而是通过SQL语句层面 建立逻辑意义上的表关系
eg:操作员工表的SQL执行完毕之后,立刻跟着执行部门表的SQL
"""
如何创建关系?
一对多创建
表关系关键字:foreign key(字段) references 表名(字段名)
以员工和部门表为例
站在员工表的基础上
问:一个员工信息能否对应多个部门
答:不能
站在部门表的基础上
问:一个部门能否对应多个员工
答:可以
总结:一个可以,一个不可以,表关系就是'一对多'
:员工表是多,部门表是一
"针对一对多的表关系,外键字段建在多的一方"
# 注:表关系没有多对一的说法,都是一对多
"""
使用SQL语句建立真正意义上的表关系,需要先创建没有外键字段的基本表之后再创建需要添加字段的表
如:创建员工表与部门表,员工表内应该有外键字段,创建表的时候就需要先创建部门表。之后创建员工表
create table dep(
id int primary key auto_increment,
dep_name varcher(32),
dep_desc varcher(255)
);
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int, # 需要关联的外键字段
foreign key(dep_id) references dep(id) # 将需要关联的字段添加之后再添加另一张表关联的字段
);
"""
多对多创建
以书籍表和作者表关系为例
站在书籍表的基础上
问:一本书可否有多个作者?
答:可以
站在作者表的基础上
问:一个作者可否有多本书?
答:可以
总结:两个都可以,可以确定为多对多的表关系
"""
多对多表关系创建:需要创建第三张表储存外键字段(第三张表可以不绑定)
# 创建书籍表
create table book(
id int primary key auto_increment,
title varchar(32),
price float(6,2)
);
# 创建作者表
create table author(
id int primary key auto_increment,
name varchar(32),
age int
);
# 创建关联表
cerate table book_to_author(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(book_id) references book(id)
on update cascade
on delete cascade
foreign key(author_id) references author(id)
on update cascade
on delete cascade
);
"""
一对一创建
作者表与作者详情表
站在作者表的基础上
问:一个作者能否有多个作者详情
答:不能
站在详情表的基础上
问:一个作者详情能否有多个作者
答:不能
总结:两个都不可以
:那么关系可能是'没有关系' or '一对一'
# 外键字段在任何一方都可以,建议在查询频率高的表中
"""
create table author(
id int primary key auto_increment,
name varchar(32),
author_id int unique, # 使用唯一值关键字即可
foreign key(author_id) references author_detail(id)
on update cascade
on delete cascade
);
create table author_dateil(
id int primary key auto_increment,
phone varchar(32),
address varchar(32)
);
"""
操作表的SQL语句补充
show tables;
create table 表名(字段 类型 约束条件);
alter table 表名 关键字 字段;
drop from 表名;
语法:
1、修改表名:
alter table 表名 rename 新表名;
2、增加字段:
alter table 表名 add 字段名 类型 约束条件;
alter table 表名 add 字段名 类型 约束条件 first; # 该字段创建在最前面
alter table 表名 add 字段名1 类型 约束条件 after 字段名2; # 字段2创建在什么字段1之后
3、删除字段
alter table 表名 drop 字段名;
4、修改字段
alter table 表名 modify 字段名 数据类型 约束条件;
alter table 表名 change 旧字段名 新字段名 新数据类型 约束条件;
查询关键字
模糊查询
模糊查询:没有明确的筛选条件
关键字:like
关键符号:
%:任意字符任意个数
_:任意一个字符
如:
show variables like '%mode%';
查询数据准备
准备数据
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int,
depart_id int
);
#插入记录
#三个部门:业务,销售,运营
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','XXX',7300.33,401,1), #以下是业务部
('tom','male',78,'20150302','business',1000000.31,401,1),
('kevin','male',81,'20130305','business',8300,401,1),
('tony','male',73,'20140701','business',3500,401,1),
('owen','male',28,'20121101','business',2100,401,1),
('jack','female',18,'20110211','business',9000,401,1),
('jenny','male',18,'19000301','business',30000,401,1),
('sank','male',48,'20101111','business',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);
from and select
from :查询哪张表
select :查询表里面的哪些数据
select * from 表;
select 字段 from 表;
where
where :筛选功能
select * from 表 where 条件
# 1、查询id大于等于3小于等于6的数据
select * from emp where id >=3 and id <=6;
or
select * from emp weere id between 3 and 6;
# 2、查询薪资是20000或者18000或者17000的数据
select * from emp where salary=20000 or salary=18000 or salary=17000;
or
select * from emp where salary in (20000,18000,17000);
# 3、查询员工姓名中包含字母o的员工姓名和薪资
select name,salary from emp where name like '%o%';
# 4、查询员工姓名是由四个字符组成的员工姓名与其薪资
select name,salaty from emp where name like '____';
or
select name,salaty from rmp where char_length(name) = 4;
# 5、查询id小于3或者大于6的数据
select * from emp where id not between 3 and 6;
or
select * from emp where id <=3 or id >=6;
# 6、查询薪资不是20000,18000,17000的数据
select * from emp where salary not in(20000,18000,17000);
# 7、查询岗位描述为空的员工姓名与岗位名,针对null不能用 = ,只能用is
select name,post from emp where post_comment = null; # 查询结果为空
select name,post from emp where post_comment is null;
select name, post from emp where post_comment is not null; # 查询不是空
分组 聚合函数
聚合函数主要是配合分组一起使用
关键字:
max :最大值
min :最小值
sum :总和
count :计数
avg :平均值
group by 分组
按照某个指定的条件将单个的个体分成一个个整体
eg :性别分组
:年龄分组等等
# 分组之后默认只能够直接获取分组的依据 其他数据不能直接获取
针对5.6需要自己设置sql_mode
set global sql_mode='only_full_group_by';
# 注:设置global参数是更新,如之前有设置同样需要添加
"""
设置sql_mode为only_full_group_by 意味着以后但凡分组,只能取到分组的依据
不应该去取组里面的单个元素的值,那样的话分组就没有意义了,因为不分组就是对单个元素信息的随意获取
"""
# 设置
set global sql_mode='only_full_group_by';
# 注:需重新连接客户端
select * from emp group by post; # 以post分组,查询之后报错
select id,name from emp group by post; # 保证错
select post from emp group by post; # 获取部门信息
# 强调:只要分组了,就不能再‘直接’查到某个数据了,只能获取到组名
# 1、按照部门分组
select * from emp group by post; # 分组之后取出来的数据是每组的第一条数据
# 2、获取每个部门的最高薪资
"""
分析:以组为单位统计组内数据>>>聚合函数>>>找出最大值
"""
select post,max(salary) from emp group by post; # 获取分组之后每个组的最高的数据
# 补充:在显示的时候可以设置别名,即更改显示的字段名
select post as '部门',max(salary) as '最高薪资' from emp group by post;
# as可以省略不写,但语义不明确
# 3、每个部门的最低薪资
select post,min(salary) from emp group by post;
# 4、每个部门的平均薪资
select post,avg(salary) from emp group by post;
# 5、每个部门的薪资总和
select post,sum(salary) from emp group by post;
# 6、每个部门的人数
select post,count(id) from emp group by post; # 注意,在计数的时候统计非空且唯一的字段效果最佳
group_concat and concat
分组之前使用:concat
分组之后使用:group_concat
总结:此参数类似字符拼接,可以让多个参数在显示的concat字段中
# 如果真的要使用分组之后的数据字段,可以使用group_concat
# 每个部门的员工姓名
select post,group_concat(name) from emp group by post;
# 每个部门的员工姓名和id
select post,group_concat(name,id) from emp group by post;
# 每个部门的员工姓名和id中间用 + 显示
select post,group_concat(name,'+',id) from emp group by post;
# concat 不分组
select concat(name,id) from emp;
select conocat(naem,'+',id) from emp;
having 过滤
"""
where和having都是筛选功能,但是有区别
where是分组之前对数据筛选
having是分组之后对数据筛选
"""
# 注:每一条SQL语句的结果可以看成一张全新的表
# 解析:select post,avg(salary) from emp where age>30 gruop by post having avg(salary)>10000;
1、查询出emp表中的post字段数据,和salary字段的平均值
2、找出年龄大于三十岁的数据
3、以post进行分组
4、查询出分组之后平均薪资大于10000的数据
5、最后展示为:每组年龄大于三十岁且平均薪资大于一万的数据
distinct 去重
# 对有重复的战术数据进行去重操作,一定要是重复的数据
select distinct id,age from emp;
select distinct post from emp;
order by 排序
order by 字段 asc; # 默认升序 asc可以简写
order by 字段 desc; # 降序
select * from emp order by salary asc; # 默认升序 asc 可以简写
select * from emp order by selary desc;
# 先按照age降排序,在年纪相同的情况下在按照薪资升排序
select * from emp order by age desc,salaty asc;
# 统计各部门年龄在10岁以上员工平均薪资,并且保留平均薪资大于1000的部门,然后对平均工资进行排序
select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000 order by avg(salary) desc;
limit 分页
# 限制展示条数
select * from limit 3;
# 查询工资最高的人的详细信息
select * from emp order by salary desc limit 1;
# 分页显示
select * from emp limit 0,5; # 第一个参数标识起始位置,第二个参数为展示的条数,
select * from emp limit 5,5; # 第一条参数不包含自身
regexp正则
select * from emp where name regexp '正则';
多表查询思路
平时查询数据的时候使用的单表操作。
select * from 表 where 筛选条件;
当多表操作的时候需要明确到底要操作几张表。
再根据条件一层一层查询即可
子查询
定义:将SQL语句的查询结果括号括起来当做另一条SQL语句的条件。
select * from 表1 where (select * from 表2 where 筛选条件)
连表操作
两张表的字段需要有外键关联
inner join内连接
只拼接两张表中共有(有对应关系)的部分
select * from 表1 inner join 表2 on 表一.字段=表2.字段
left join左连接
以左表为基准,展示左表所有的内容,没有的null填充
select * from 表1 left join 表2 on 表1.字段=表2.字段;
right右链接
以右表为基准,展示右表所有的内容,没有的null填充
select * from 表1 rigth join 表2 on 表1.字段=表2.字段;
union全连接
两张表所有的属性都链接,没有的mull填充
select * from 表1 left join 表2 join 表1.字段=表2.字段 union select * from 表1 rigth join 表2 join 表1.字段=表2.字段;
上述操作一次性只可以链接两张表,怎么做到多表查询?
将两张表的拼接结果当成一张新的表去跟另外一张表做拼接即可,一直往复,即可拼接多张表
select course.cname,teacher.tname from course inner JOIN teacher on course.teacher_id=teacher.tid;
python操作MySQL
需要下砸第三方模块:pymysql
下载:
pip3 install pymysql
使用:
import pymysql
# 链接MySQL服务端
conn = pymysql.connect(
host='127.0.0.1' # 链接的ip地址
port=3306, # 端口号
user='root' # 登录用户名
password='' # 登录密码
database='db' # 指定的库
charset='utf8' # 字符编码
autocommit=True # 针对增删改,自动二次确认
)
# 此返回对象可以看做游标对象(光标)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 括号内的参数表示返回结果cursor构造成字典
# 编写SQL语句
sql = 'select * from 表'
res = coursor.exrcute(sql) # 返回结果为这条语句影响的行数
cursor.fetchall() # 获取SQL语句的所有结果
cursor.fetchall() # 再次获取则不会得到任何的数据,类似于文件光标,读取一次光标就会向后移,没办法取之前的数据
cursor.fetchone() # 获取一个数据
cursor.fetchmany(n) #自定义获取个数
cursor.scroll(1,'relative') # 控制光标移动。第一个数字代表的距离,第二个参数表示以当前位置位基准
cursor.scroll(1,'absolute') # 控制光标移动。第一个参数代表移动的距离,第二个参数从最开始位置位基准
SQL注入问题
"""
SQL注入:
由特殊的符号组合产生了特殊的效果
实际生活中,在注册用户名的时候会非常明显的感觉到有很多符号不可以使用。
"""
import pymysql
# 连接MySQL服务端
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='db8_3',
charset='utf8',
autocommit=True # 针对增 改 删自动二次确认
)
# 产生一个游标对象
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 编写SQL语句
username = input('username>>>:').strip()
password = input('password>>>:').strip()
sql = "select * from userinfo where name=%s and pwd=%s"
cursor.execute(sql,(username,password))
data = cursor.fetchall()
if data:
print(data)
print('登录成功')
else:
print('用户名或密码错误')
# 1.只需要用户名也可以登录
xxx ' --sdfsdfsdf # 双 - 在SQL语句中的含义是注释,在通过后端可以查看到此输入会导致密码部分被注释掉,所以可以直接登录
# 2.不需要用户名和密码也可以登录
xxx ' or 1=1 --ddfsdf # 不需要账号密码,判断用户xxx不存在则 or 后面内的结果为True,也会登录成功
事物
ACID
A:原子性
C:一致性
I:隔离性
D:持久性
原子性(atomicity)
一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency)
事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation)
一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability)
持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响
事物相关操作:
start transcation; # 开启事物
SQL语句
rollback # 回滚到SQL语句执行前的状态
commit # 确认事物操作,SQL语句不可回滚
# 代码操作
create table user(
id int primary key auto_increment,
name char(32),
balance int
);
insert into user(name,balance)
values
('xxx',1000),
('aaa',1000),
('ppp',1000);
# 修改数据之前先开启事务操作
start transaction;
# 修改操作
update user set balance=900 where name='aaa'; #买支付100元
update user set balance=1010 where name='ppp'; #中介拿走10元
update user set balance=1090 where name='xxx'; #卖家拿到90元
# 回滚到上一个状态
rollback;
# 开启事务之后,只要没有执行commit操作,数据其实都没有真正刷新到硬盘
commit;
"""开启事务检测操作是否完整,不完整主动回滚到上一个状态,如果完整就应该执行commit操作"""
# 站在python代码的角度,应该实现的伪代码逻辑,
try:
update user set balance=900 where name='aaa'; #买支付100元
update user set balance=1010 where name='ppp'; #中介拿走10元
update user set balance=1090 where name='xxx'; #卖家拿到90元
except 异常: # 出现异常之后走这里
rollback; # 回滚到SQL语句执行之前的状态
else: # 上述代码执行完毕就会走这里
commit; # 直接保存
