
第九篇:大模型压缩训练(模型量化 、参数剪枝、知识蒸馏)
模型压缩简介
- 模型压缩目标:
- 减少模型显存占用
- 加快推理速度
- 减少精度损失
- 模型压缩通常处于模型训练和生产部署之间的阶段,他在模型训练完成后,准备将模型部署到目标环境之前进行
- 模型压缩算法:
- 线性量化或非线性量化:1/2bits, int8 和 fp16等
- 结构化剪枝或非结构化剪枝:deep compression, channel pruning 和 network slimming等
- 知识蒸馏:squeeze-net, mobile-net, shuffle-net等
模型量化(quantization)
通过减少模型参数的表示精度来降低模型的存储空间和计算复杂度
混合精度(Mixed precision)在模型中使用 FP32 和 FP16 。 FP16 减少了一半的内存
大小,但有些参数或操作符必须采用 FP32 格式才能保持准确度
低精度(Low precision)可能是最通用的概念。常规精度一般使用 FP32(32位浮点,单
精度)存储模型权重;低精度则表示 FP16(半精度浮点),INT8(8位的定点整数)等等
数值格式。不过目前低精度往往指代 INT8。
根据存储一个权重元素所需的位数,还可以包括:
① 二值神经网络:在运行时权重和激活只取两种值(例如 +1,-1)的神经网络,以及
在训练时计算参数的梯度。
② 三元权重网络:权重约束为+1,0和-1的神经网络。
③ XNOR网络:过滤器和卷积层的输入是二进制的。 XNOR 网络主要使用二进制运算来近
似卷积
量化之后为什么反量化
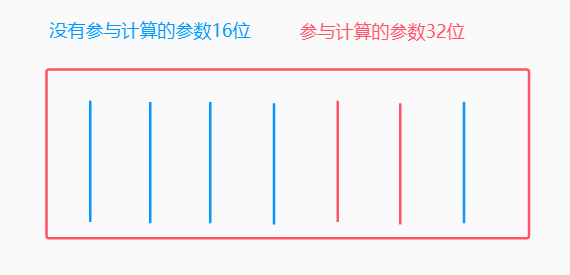
模型内部参数进行存储的时候,会将其分为两部分,正在参与计算的参数和没有参与计算的参数
没有参与计算的参数用16位表示,节约额显存,正在参与计算的参数用32位表示,以提高模型的精度
量化原理
量化:将一组数据限制到可度量的范围内
数据分为两种:有范围的、没有范围的
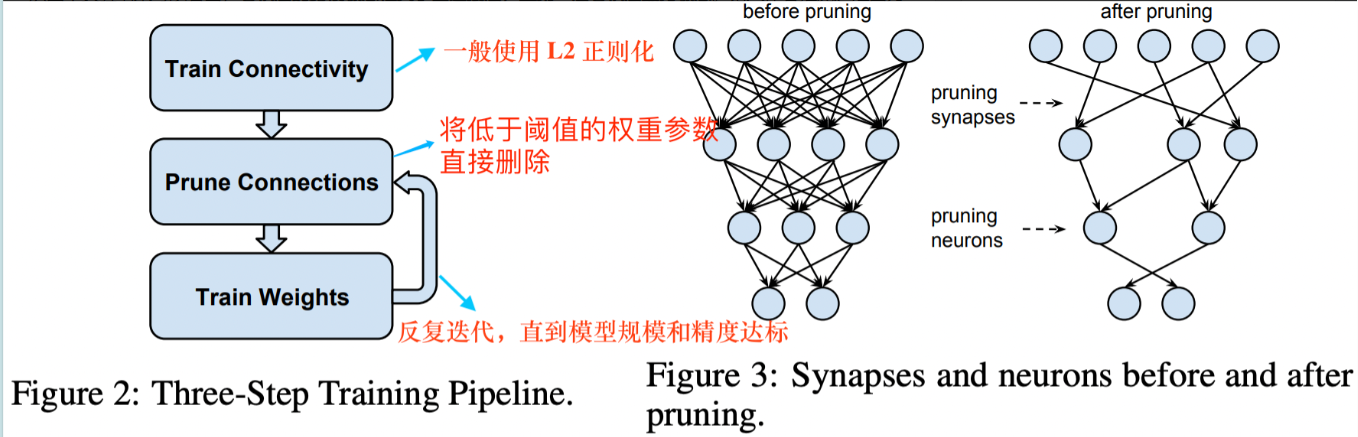
参数剪枝(pruning)
模型剪枝研究模型权重的冗余,并尝试删除/修剪冗余和非关键的权重
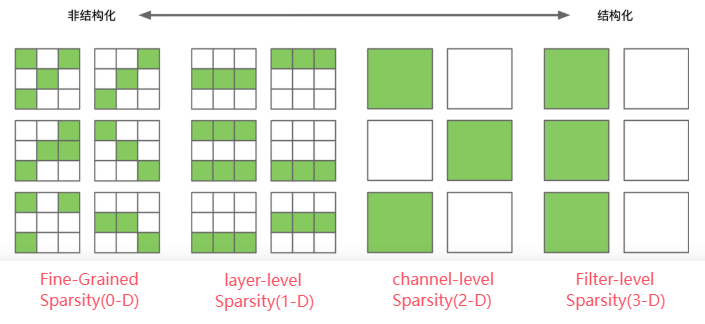
非结构化剪枝(unstructured pruning)
方法:随机对独立权重或者神经元链接进行剪枝
优:剪枝算法简单,模型压缩比高
缺:精度不可控,剪枝后权重矩阵稀疏,可能会破坏模型的整体结构,依赖于特定的算法库或硬件平台的支持
结构化剪枝(structured pruning)
方法:对filter / channel / layer 进行剪枝
优:大部分算法在 channel 或者 layer 上进行剪枝,不会破坏模型整体结构,不依赖于特定的算法库或硬件平台的支持
缺:剪枝算法相对复杂
知识蒸馏(knowledge dististillation)
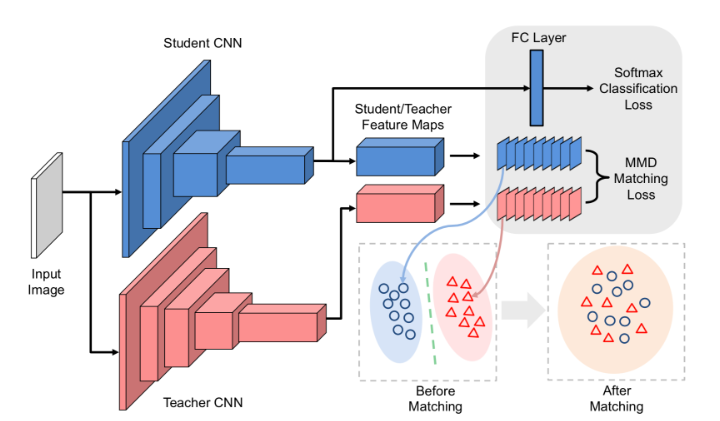
知识蒸馏在DeepSeek中的核心意义
DeepSeek作为中国人工智能领域的代表性大模型,其训练过程中深度应用了知识蒸馏技术
(Knowledge Dististillation),通过将大模型的知识迁移至小模型,实现了性能与效率
的平衡
1.降低算力与成本
DeepSeek通过蒸馏技术将模型训练成本压缩至OpenAI同类模型的1/20。例如,DeepSeek-V3
仅消耗278.8万GPU小时(成本约557.6万美元),而OpenAI类似模型的训练成本高达数亿美
元49。这种低成本特性使中小企业也能负担高性能AI模型的开发。
2.加速推理与边缘部署
蒸馏后的小模型(如32B/70B版本)推理速度提升3倍以上,延迟从850ms降至150ms,显存
占用从320GB减少至8GB。这使得模型可在手机、工业设备等边缘端实时运行,满足医疗诊
断、自动驾驶等场景的低延迟需求
推动行业应用落地
教育领域:DeepSeek蒸馏模型可快速生成个性化学习内容,根据学生反馈动态调整教学策
略,降低教育平台运营成本。
工业场景:本地化部署的蒸馏模型减少对云端的依赖,数据隐私与响应速度显著提升,助
力智能制造中的质检、供应链优化等任务。
内容创作:AI写作工具结合蒸馏模型,创作效率提升50%,同时API调用成本仅为OpenAI的
1/4,推动新媒体运营与创意产业发展。
4.技术自主可控
面对美国GPU芯片禁运,DeepSeek通过蒸馏技术降低对算力的依赖,结合FP8混合精度训练
和DualPipe流水线机制,在国产芯片(如华为昇腾)上实现高性能推理,增强中国AI产业
的自主可控能力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号