

第一篇:进程
理论知识
操作系统的发展史
操作系统的介绍
操作系统就是一个协调、管理、控制计算机硬件资源与软件资源的控制程序,本质也是一个软件。
操作系统是由操作系统的内核(运行于内核态,管理硬件资源)以及系统调用(运行于用户态,为应用程序员写的应用程序提供系统调用的接口)两部分组成。单纯说操作系统是运行于内核态是不准确的。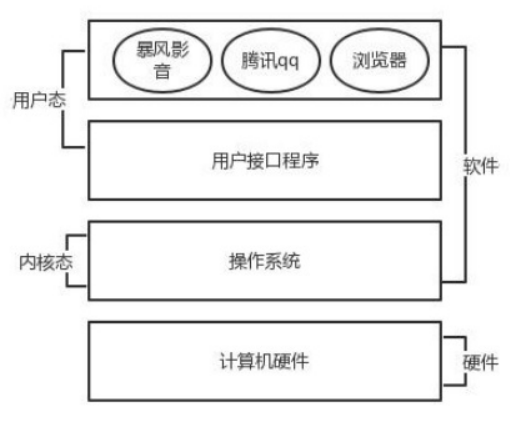
为什么要有操作系统
程序员无法把所有的硬件操作细节都了解到,管理这些硬件并且加以优化使用是非常繁琐的工作,这个繁琐的工作就是操作系统来干的,有了他,程序员就从这些繁琐的工作中解脱了出来,只需要考虑自己的应用软件的编写就可以了,应用软件直接使用操作系统提供的功能来间接使用硬件。
操作系统的发展过程


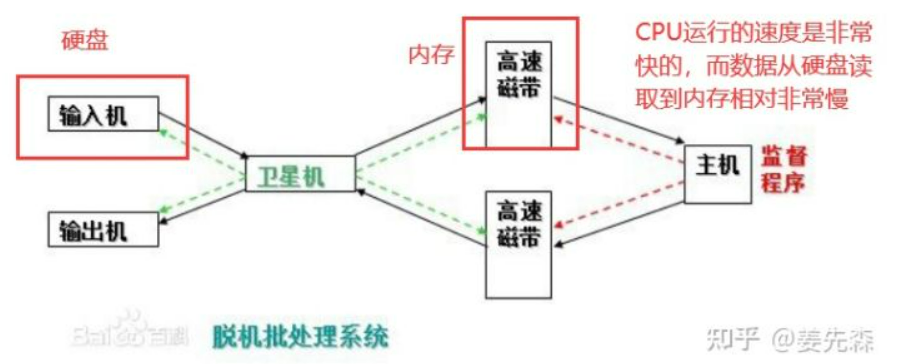
多道技术(单核实现并发的效果)
必备知识点:
并发:看起来像同时运行
并行:真正意义上的同时运行
ps:并行肯定算并发,单核的计算机肯定不能算并行,但可以实现并发
多道技术图解:
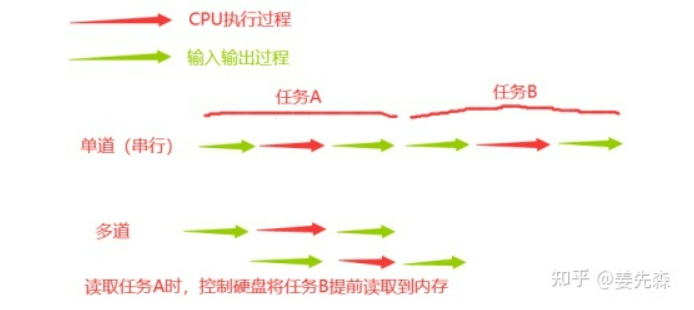
空间上的复用与时间上的复用:

# 空间上的复用 多个程序公用一套计算机硬件 # 时间上的复用 例子1:洗衣服30s 做饭50s 烧水30s 单道需要110s,多道只需要任务做得最长的即可(CPU切换节省了时间) 例子2:边吃饭边玩游戏(保存状态) 时间=切换+保存状态 # 切换(CPU)分为两种情况 1.当一个程序遇到IO操作时,操作系统会剥夺该程序的CPU执行权限 作用:提高CPU的利用率,并且也不影响其执行效率 2.当一个程序长时间占用CPU的时候,操作系统也会剥夺该程序的CPU的执行权限 弊端:降低了执行效率(原本时间+切换时间)
进程理论
进程理论
什么是进程进程:正在进行的一个过程或者说一个任务。而负责任务的则是CPU
进程与程序的区别
# 程序就是一堆躺在硬盘上的代码,是“死”的 # 进程则表示程序正在执行的过程,是“活”的
进程的调度
# 1、先来先服务调度算法 "对长作业有利,对短作业无益" # 2、短作业优先调度算法 "对短作业有利,对长作业无益" # 3、时间片轮转法+多级反馈队列
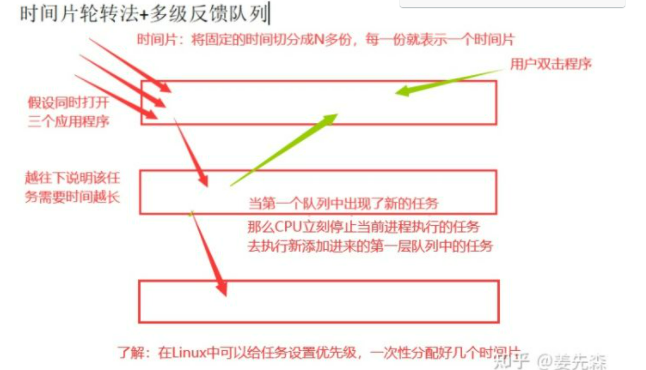
进程运行的三状态图
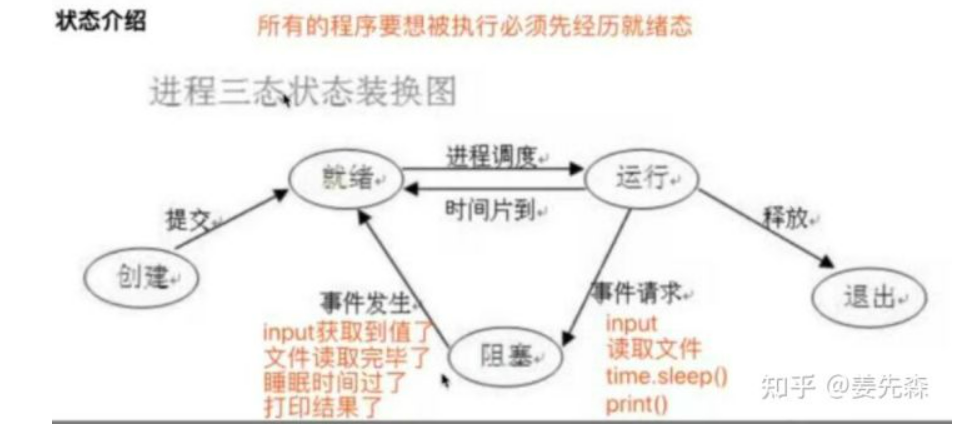
同步\异步and阻塞\非阻塞
# 同步异步
"""描述的是任务的提交方式""" 同步:任务提交后,原地等待任务的返回结果,等待的过程中不做任何事(干等) 程序层面上表现出来的感觉就是卡住了 异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情 提交的任务结果如何获取? 任务的返回结果会有一个异步回调机制自动处理 # 阻塞非阻塞** """描述的程序的运行状态""" 阻塞:阻塞态 非阻塞:就绪态、运行态 理想状态:我们应该让我们的写的代码永远处于就绪态和运行态之间切换 上述概念的组合:最高效的一种组合就是**异步非阻塞**
在python程序中的进程操作
multiprocessing模块与Process类
multiprocessing模块的介绍
-
-
multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。
-
Process类的介绍
创建进程的类
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍
# group 参数未使用,值始终为None # target 表示调用对象,即子进程要执行的任务 # args 表示调用对象的位置参数元组,args=(1,2,'jiang',) # kwargs 表示调用对象的字典,kwargs={'name':'jiang','age':18} # name 表示子进程的名字
方法介绍
# 1 p.start():启动进程,并调用该子进程中的p.run() # 2 p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法 # 3 p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁 # 4 p.is_alive():如果p仍然运行,返回True # 5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
属性介绍
# 1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 # 2 p.name:进程的名称 # 3 p.pid:进程的pid # 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) # 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
开启进程的两种方式
第一种:使用multiprocessing模块中Process类的构造器创建进程
from multiprocessing import Process import time def task(name): print("%s is running" % name) time.sleep(1) print("%s is over" % name) if __name__ == '__main__': # 1、创建一个对象 p = Process(target=task, args=('jiang',)) # 容器类型哪怕只有一个元素,建议用都好分隔开 # 2、开启进程 p.start() # 告诉操作系统创建一个进程 异步 # p.start 开启进程,并调用该子进程中的p.run() print('主进程') # 在Windows中Process()必须放入 if __name__ == '__main__':
第二种:通过类的继承来创建进程
from multiprocessing import Process import time class MyClass(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print("%s is running" % self.name) time.sleep(1) print("%s is over" % self.name) if __name__ == "__main__": p = MyClass('jiang') p.start() print('主线程')
创建进程的内部原理
创建进程就是在内存中申请一块内存空间将需要运行的代码丢进去
一个进程对应在内存中就是一块独立的内存空间
多个进程对应在内存中就是多块独立的内存空间
进程与进程之间数据默认情况下是无法直接交互,如果想交互可以借助于第三方工具、模块
join方法
from multiprocessing import Process import time def task(name): print('%s is running' % name) time.sleep(1) print('%s is over' % name) if __name__ == '__main__': p = Process(target=task, args=('jiang',)) p.start() p.join() print('主进程') from multiprocessing import Process import time class MyClass(Process): def __init__(self,name): super().__init__() self.name = name def run(self): print('%s is running' % self.name) time.sleep(1) print('%s is over' % self.name) if __name__ == '__main__': p = MyClass('jiang') p.start() p.join() print('主进程')
进程见数据的相互隔离
from multiprocessing import Process import time m = 100 def task(): global m m = 200 print('子进程m=%s' % m) if __name__ == '__main__': p = Process(target=task,) p.start() print('主进程m=%s' % m)
主进程100
子进程200
进程对象及其他方法
""" 一台计算机上面运行着很多进程,那么计算机是如何区分并管理这些进程服务端的呢? 计算机会给每一个运行的进程分配一个PID号 如何查看 windows电脑 进入cmd输入tasklist即可查看 tasklist |findstr PID查看具体的进程 mac电脑 进入终端之后输入ps aux ps aux|grep PID查看具体的进程 """ from multiprocessing import Process,current_process import time import os def task(): print('子进程号%s' % current_process().pid) # 查看当前进程的进程号 print('子进程号',os.getpid()) # 查看当前进程的进程号 time.sleep(1)
# 子进程的主进程进程号就是子进程父进程号 print('子进程的主进程进程号',os.getppid()) # 查看当前进程的父进程进程号 if __name__ == '__main__': p = Process(target=task) p.start() p.join() p.terminate() # 杀死当前进程 # 是告诉操作系统帮你去杀死当前进程 但是需要一定的时间 而代码的运行速度极快 time.sleep(0.1) print(p.is_alive()) # 判断当前进程是否存活 '''一般情况下我们默认会将存储布尔值的变量名、返回的结果是布尔值的方法名都起成以is_开头''' print('主进程',current_process().pid)
僵尸进程与孤儿进程(了解)
僵尸进程
死了但是没死透
当你开设了子进程之后,该进程死后不会立刻释放占有的进程号。因为我们要让父进程能够查看到它开设的子进程的一些基本信息(占有的pid号 运行时间等)
所有的进程都会步入僵死进程
父进程不会死并且在无限制的创建子进程并且子进程也不结束
回收子进程占用的pid号(父进程等待子进程运行结束 父进程调用join方法)
孤儿进程
子进程存活,父进程意外死亡
操作系统会开设一个“儿童福利院”专门管理孤儿进程回收相关资源
守护进程
'''主进程结束之后不会立即结束,会等待其它非守护进程结束后才结束''' from multiprocessing import Process import time def task1(name): print('%s is running' % name) time.sleep(1) print('%s is over' % name) def task2(name): print('%s is running' % name) time.sleep(1) print('%s is over' % name) if __name__ == '__main__': p1 = Process(target=task1,args=('jiang',)) p2 = Process(target=task2,args=('li',)) # 将进程p1设置为守护进程 p1.daemon = True # 这一句话一定要放在start方法上面个才有效,否者直接报错 p1.start() p2.start() print('主进程')
进程互斥锁
''' 多个进程操作同一份数据的时候,会出现数据错乱的问题 解决的方法就是加锁处理:将并发变成串行,牺牲效率但是保证了数据的安全 '''
data.txt
{"ticket_num": 1}
from multiprocessing import Process, Lock import json import time import random # 查票 def search(i): # 文件操作读取票数 with open('data','r',encoding='utf8') as f: dic = json.load(f) print('用户%s查询余票:%s'%(i, dic.get('ticket_num'))) # 字典取值不要用[]的形式 推荐使用get 你写的代码打死都不能报错!!! # 买票 1.先查 2.再买 def buy(i): # 先查票 with open('data','r',encoding='utf8') as f: dic = json.load(f) # 模拟网络延迟 time.sleep(random.randint(1,3)) # 判断当前是否有票 if dic.get('ticket_num') > 0: # 修改数据库 买票 dic['ticket_num'] -= 1 # 写入数据库 with open('data','w',encoding='utf8') as f: json.dump(dic,f) print('用户%s买票成功'%i) else: print('用户%s买票失败'%i) # 整合上面两个函数 def run(i, mutex): search(i) # 给买票环节加锁处理 # 抢锁 mutex.acquire() buy(i) # 释放锁 mutex.release() if __name__ == '__main__': # 在主进程中生成一把锁 让所有的子进程抢 谁先抢到谁先买票 mutex = Lock() for i in range(1,11): p = Process(target=run, args=(i, mutex)) p.start()
"""
扩展 行锁 表锁
注意:
1.锁不要轻易的使用,容易造成死锁现象(我们写代码一般不会用到,都是内部封装好的)
2.锁只在处理数据的部分加来保证数据安全(只在争抢数据的环节加锁处理即可)
"""
进程间通信——队列(multiprocessing.Queue)
队列Queue模块
""" 管道:subprocess (stdin stdout stderr) 队列:管道+锁 队列:先进先出 堆栈:先进后出 q.full() # 判断当前队列是否满了 q.empty() # 判断当前队列是否空了 q.get_nowait() # 没有数据直接报错 queue.Empty q.get(timeout=3) # 没有数据之后原地等待三秒后再报错 queue.Empty q.full() q.empty() q.get_nowait() 在多进程的情况下不精确 """ from multiprocessing import Queue # 创建一个队列 q = Queue(2) #括号内可以穿数字,表示生成的队列最大可以同时存入的数据量 # 往队列中存数据 q.put(111) q.put(222) # print(q.full(),q.empty()) # q.put(333) # 当队列数据存放满了后,如果还有数据要放程序会阻塞,直到有位置让出来 v1 = q.get() v2 = q.get() # v3 = q.get() # 队列中如果没有数据的话,get方法会原地阻塞
IPC机制
""" 研究思路 1、主进程跟子进程借助队列通信 2、子进程跟子进程借助队列通信 """ from multiprocessing import Process,Queue def producer(q): q.put('yaunxiaojiang') def consumer(q): print(q.get()) if __name__ == '__main__': q = Queue() p1 = Process(target=producer,args=(q,)) p2 = Process(target=consumer,args=(q,)) p1.start() p2.start() # print(q.get())
生产者消费者模型
""" 生产者:生产/制造东西的 消费者:消费/处理东西的 该模型除了上述两个外还需要一个媒介 厨师菜做完之后用盘子装着给消费者端过去 生产者和消费者之间不是直接交互的,而是借助于媒介做交互 生产者(厨师)+消息队列(盘子)+消费者(客户) """
from multiprocessing import Process, Queue, JoinableQueue import time import random def producer(name,food,q): for i in range(5): data = '%s生产了%s%s'%(name,food,i) print(data) # 模拟延迟 time.sleep(random.randint(1,2)) # 将数据放入队列中 q.put(data) def consumer(name,q): while True: food = q.get() # 没有数据就会卡住 # # 判断当前是否有结束的标识 # if food is None:break time.sleep(random.randint(1,2)) print('%s吃了%s'%(name,food)) q.task_done() # 告诉队列你已经从里面取出一个数据并处理完毕 if __name__ == '__main__': # q = Queue() q = JoinableQueue() p1 = Process(target=producer,args=('yuan','包子',q,)) p2 = Process(target=producer,args=('xiao','泔水',q,)) c1 = Process(target=consumer,args=('jiang',q,)) c2 = Process(target=consumer,args=('chen',q,)) p1.start() p2.start() # 将消费者设置成守护进程 c1.daemon = True c2.daemon = True c1.start() c2.start() # 等待生产者生产完毕之后,再往队列中添加特定的结束符号 # p1.join() # p2.join() # q.put(None) # 肯定在所有生产者生产的数据的末尾 # q.put(None) # 肯定在所有生产者生产的数据的末尾 q.join() # 等待队列中所有的数据被取完再执行往下执行代码 # 只要q.join执行完毕 说明消费者已经处理完数据了 消费者就没有存在的必要了 """ JoinableQueue 每当你往该队列中存入数据的时候 内部会有一个计数器+1 没当你调用task_done的时候 计数器-1 q.join() 当计数器为0的时候 才往后运行 """


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现