

redis基础和单线程的原因
1.
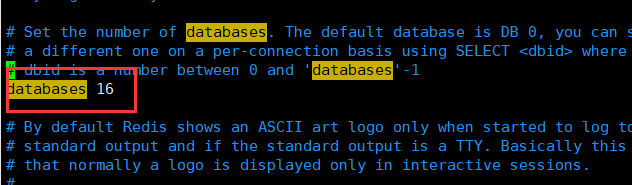
默认16个数据库(db0~db15) 默认使用的是第0个
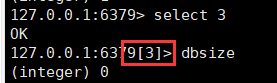
可使用select切换数据库,select 3表示切换到 db3
2.
前提:
keyName表示键名称 | seconds为秒 | db为数据库下标
查看key的类型:type keyName
查看当前数据库所有的key:keys *
清除当前数据库所有的key:flushdb
清空所有数据库的所有key:flushall
查看当前数据库的大小:dbsize
查看某个key是否存在:exists keyName
为key设置过期时间:expire keyName seconds
查看key剩余时间:ttl keyName
将某key移动到其他数据库:move keyName db
3.
redis是单线程的
redis是基于内存操作,CPU并不是redis性能瓶颈,而是机器的内存和网络带宽
为什么Redis这么快?
1.数据结构简单,对数据操作也简单。
2.Redis将数据储存在内存里面,读写数据的时候都不会受到硬盘 I/O 速度的限制,所以速度极快。
3.采用单线程,避免了多线程CPU的上下文切换和竞争条件的耗时。也不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4.使用多路I/O复用模型,非阻塞IO
Redis使用单线程的原因是什么?
redis 核心是 数据全都在内存里,单线程的去操作 就是效率最高的。因为多线程的本质就是 CPU 模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。redis 用 单个CPU 绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处理这个事。在内存的情况下,这就是最佳方案。

