Kafka(1)- producer
前言
本系列是kafka相关的第一篇,主要对kafka的producer和consumer进行介绍。此系列不会对kafka的原理进行介绍,因此需要读者有一定的kafka背景知识和使用经验。1. producer整体架构
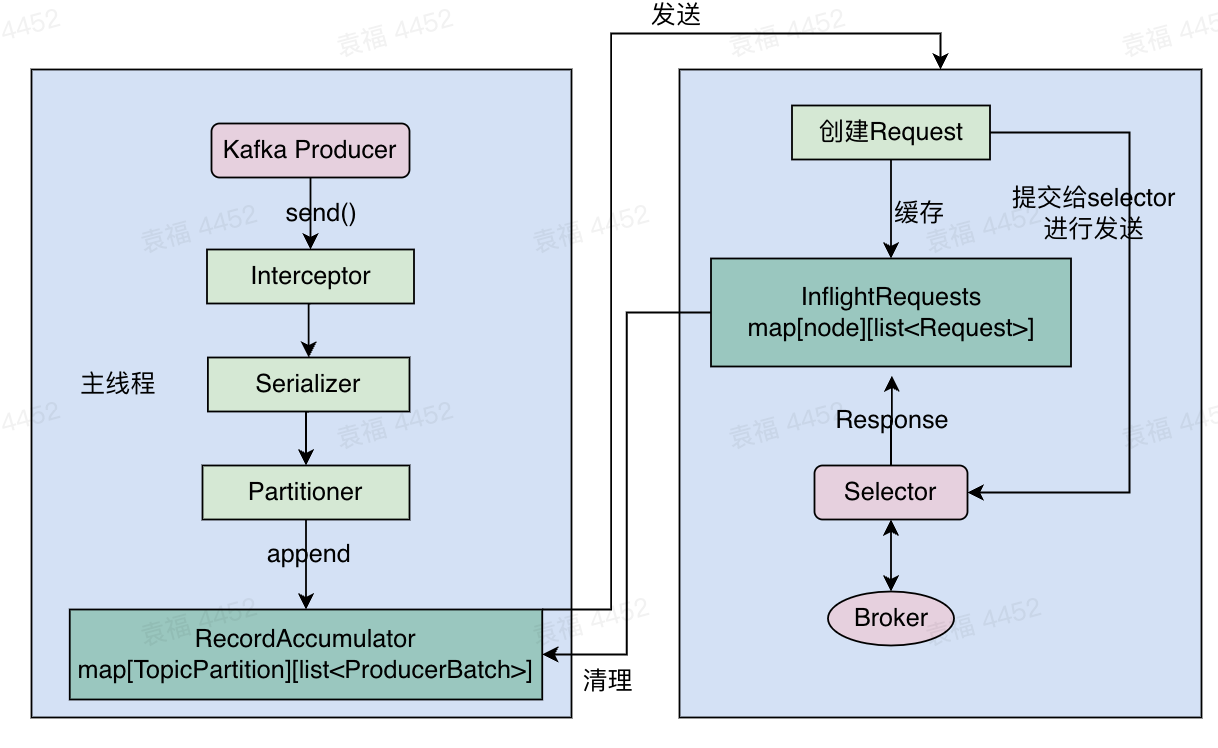
图1 kafka producer整体架构
2. 主线程

Properties props = new Properties(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getNme()); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getNme()); // 其他prop配置 KafkaProducer<K, V> producer = new KafkaProducer<>(props); // 之后就可以调用kafka send方法
其中bootstrap.servers即broker相关的id,ip, port 信息,实际不用指定所有broker信息,kafka会自行发现其他的broker;key_serializer和value_serializer负责消息key和value的序列化。
2.1 Interceptor(拦截器)
send方法发送时,首先会调用Interceptor拦截器(如果有的话)对应的onSend()方法。Interceptor是由用户传入的,可以对一条Record的key,value进行改写。主要包括两个方法:
public class ProducerInterceptors<K, V> implements Closeable { public ProducerInterceptors(List<ProducerInterceptor<K, V>> interceptors) { this.interceptors = interceptors; } // onSend()方法在创建Record的时候会调用,多个interceptor的调用是链式的 public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) { ProducerRecord<K, V> interceptRecord = record; for (ProducerInterceptor<K, V> interceptor : this.interceptors) { try { interceptRecord = interceptor.onSend(interceptRecord); } catch (Exception e) { // do not propagate interceptor exception, log and continue calling other interceptors // be careful not to throw exception from here if (record != null) log.warn("Error executing interceptor onSend callback for topic: {}, partition: {}", record.topic(), record.partition(), e); else log.warn("Error executing interceptor onSend callback", e); } } return interceptRecord; } // onAcknowledgement()会在收到响应或者发送失败时调用 public void onAcknowledgement(RecordMetadata metadata, Exception exception) { for (ProducerInterceptor<K, V> interceptor : this.interceptors) { try { interceptor.onAcknowledgement(metadata, exception); } catch (Exception e) { // do not propagate interceptor exceptions, just log log.warn("Error executing interceptor onAcknowledgement callback", e); } } } }
2.2 Serializer(序列化器)
Serializer负责把数据转化为字节数组,进行网络传输,序列化器需要实现orq.apache.kafka.common.serialization.Serilizer接口,该接口有三个方法:
public void configure(Map<String, ?> configs, boolean isKey); public byte[] serialize(String topic, T data); public void close();
2.3 Partitioner(分区器)
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) { if (record.partition() != null) return record.partition(); // 如果指定了分区,直接返回 // 如果存在自定义分区器,使用用户的自定义分区器计算分区 if (partitioner != null) { int customPartition = partitioner.partition( record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); if (customPartition < 0) { throw new IllegalArgumentException(String.format( "The partitioner generated an invalid partition number: %d. Partition number should always be non-negative.", customPartition)); } return customPartition; } // 对key进行哈希,然后对topic的partion数量取模 if (serializedKey != null && !partitionerIgnoreKeys) { // hash the keyBytes to choose a partition return Utils.toPositive(Utils.murmur2(serializedKey)) % cluster.partitionsForTopic(record.topic()).size(); } else { return RecordMetadata.UNKNOWN_PARTITION; } }
Kafka首先判断该条记录是否指定了分区,指定了则直接返回分区;然后判断是不是有用户自定义实现的分区器,有则使用用户自定义分区器;最后将序列化之后的key hash之后对分区数量取模,得到最终的分区。分区内的数据是有序的,因为如果想保证同一条消息的多个时间版本的顺序性,需要保证key相同。
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
3. RecordAccumulator
RecordAccumulator就是用来缓存record,方便sender批量发送请求的。一条消息在RecordAccumulator中保存的格式是以TopicPartion作为key,list<ProducerBatch>作为value保存的。保存的形式如下:
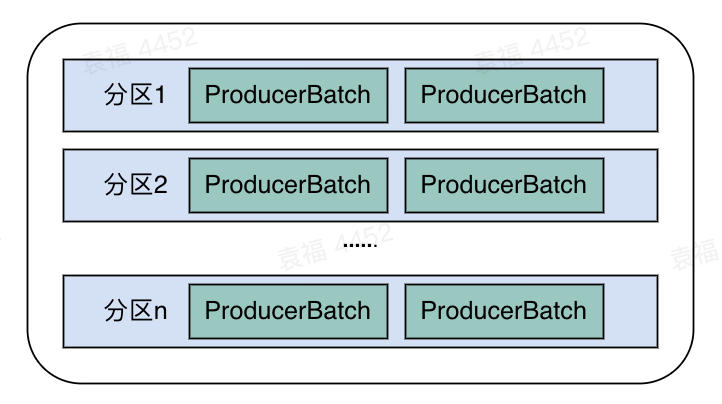
图2 RecordAccumulator的数据保存形式
将一条Record添加到RecordAccumulator的流程如下:
(1)计算分区,获取该Record的partiiton,如果在此时partition 仍然未知,会根据topicInfo内置的partitioner计算分区;
(2)获取该分区对应的Deque<ProducerBatch> dq,如果没有则创建一个Deque<ProducerBatch>;
(3)对dq加锁保护,尝试将record添加到dq中,如果成功则返回;如果dq中没有ProducerBatch或末尾的ProducerBatch的空间装不下record,释放锁继续后面的步骤;
(4)因为空间不够,申请一个ProducerBatch的缓冲区buffer;
(5)再次对dq加锁,尝试append,因为在第四步期间有可能有其他线程已经申请上了新的空间;
(6)如果第五步失败,说明没有新的空间,基于buffer创建一个ProducerBatch,尝试将record添加到ProducerBatch中;
(7)将ProducerBatch添加到dq的末尾,返回添加成功的记录。
整个过程的伪代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | public RecordAppendResult append(...) { // 一直尝试添加,直到成功 while ( true ) { // 1. 获取partition if (partition == RecordMetadata.UNKNOWN_PARTITION) { // 重新计算partition } //2. 获取partiton对应的Dequeue Deque dq = topicInfo.batches.computeIfAbsent(...); // 如果没有则新建 synchronized (dq) { // 3. 第一次尝试添加 RecordAppendResult result = tryAppend(...) // 成功 if result != null { return result } } // 4. 申请空间 ByteBuffer buffer = allocate() // 如果record Size超过batch.size,,则申请新的内存,否则从bufferpool申请一个batch.size大小的内存 synchronized (dq) { // 5. 再次尝试append() RecordAppendResult result = tryAppend() if (result != null ) { return result; } } // 6. 创建ProducerBatch,并添加record ProducerBatch batch = new ProducerBatch(...); batch.tryAppend() // 7. 将batch添加到dq末尾 dq.addLast(batch); return new RecordAppendResult(...); }} |
4. Sender线程
sender线程的职责就是从ReccordAccumulator中获取消息,发送给服务端并收取服务端的响应。sender实现了Runnable接口,在初始化KafkaProducer的时候,sender就会初始化,并和KafkaProducer共享一个RecordAccumulator。sender的核心成员变量如下:
- ReccordAccumulator:跟producer共享一个;
- KafkaClient:KafkaClient本身是一个接口,由NetworkClient实现(NetworkClient中的selector底层基于NIO实现),负责跟其他节点进行网络通信;
sender线程发送数据的流程如下:
(1)遍历RecordAccumulator的map<TopicPartition, Deque<ProducerBatch>>,找到对应TopicPartition的leader存入ReadyNodes中(如果存在找不到leader的TopicPartiton,则会进行一次元数据更新);
(2)检查ReadyNodes中的node,是否能正常进行网络连接(调用NetworkClient.ready()方法);
(3)根据ReadyNodes,对RecordAccumulator中的数据重新组织,组装成Map<Integer, List<ProducerBatch>>(key为nodeId)形式的结果集readyBatches(对应的函数为RecordAccumulator.drain(),过程为遍历ReadyNodes,获取每一个node的partitions,再遍历对应的partitinos,从map<TopicPartition, deque<ProducerBatch>>中获取每一个partition的first,加入到结果集中);
(4)将readyBatches加入inFlightBatches中,并检查inFlightBatches和accumulator中过期的batches,并清理掉。
(5)设置pollTimeout(即sender阻塞的时间)。如果ReadyNodes不为空,说明有数据待发送,pollTimeout=0;否则pollTimeout = min(result.nextReadyCheckDelayMs, notReadyTimeout, this.accumulator.nextExpiryTimeMs() - now);
(6)构造sendRequest,交给selector实现最终的发送;
(7)调用client.poll()执行发送。
4.1 sendProducerData
整个过程的核心代码如下:
// sender线程的主循环主要执行的函数就是sendProducerData,包含了一次发送的所有逻辑 private long sendProducerData(long now) { // 1. 寻找就绪的record,result中包含:readyNodes, unknownLeaderTopics, nextReadyCheckDelayMs RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now); if (!result.unknownLeaderTopics.isEmpty()) { this.metadata.requestUpdate(); //请求元数据更新,其实也是通过sender发送一条metadataRequest } //2. 检查哪些node准备好可以发送数据(探测跟broker node的网络连接是否正常) Iterator<Node> iter = result.readyNodes.iterator(); while (iter.hasNext()) { Node node = iter.next(); // 检查网络连接 if (!this.client.ready(node, now)) { iter.remove(); // 移除该node notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now)); } // 更新node的延时状态,比如统计延时时长,用于判断该node是否可用 } //3. 重新组织数据,由map<partition, deque<ProducerBatch>>变成map<node, list<ProducerBatch>> // key为node ID Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now); // 4. 添加到inFlightBatch并清理掉过期的batch addToInflightBatches(batches); ... // 清理过期的batch // 5. 计算pollTimeout,pollTimeout即发送网络请求的超时时间 pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now); pollTimeout = Math.max(pollTimeout, 0); if (!result.readyNodes.isEmpty()) { // 说明有数据发送,可以即时发送,不用阻塞 } // 6. 构造sendRequest交给selector sendProduceRequests(batches, now); return pollTimeout; }
public ReadyCheckResult ready(Cluster cluster, long nowMs) { // 遍历所有的topic, for (Map.Entry<String, TopicInfo> topicInfoEntry : this.topicInfoMap.entrySet()) { final String topic = topicInfoEntry.getKey(); // 获取RecordAccumulator中map<partition, deque<ProducerBatch>> ConcurrentMap<Integer, Deque<ProducerBatch>> batches = topicInfoEntry.batches; // 遍历partiton for (Map.Entry<Integer, Deque<ProducerBatch>> entry : batches.entrySet()) { TopicPartition part = new TopicPartition(topic, entry.getKey()); // 当前的TopicPartition Node leader = cluster.leaderFor(part); //寻找该partition的leader所在的node, Deque<ProducerBatch> deque = entry.getValue(); // 获取partiton对应的deque // 对dequqe实行并发保护 synchronized (deque) { // 获取第一个batch ProducerBatch batch = deque.peekFirst(); if (batch == null) { continue; } if (leader == null) { unknownLeaderTopics.add(part.topic()); // leader为空,添加到unknownLeaderTopics中 } else { // readyNodes中不包含leader,且当前的partition非muted(muted即静默的,在需要保证发送顺序的场合使用) if (!readyNodes.contains(leader) && !isMuted(part)) { if batch.isReady() { // leader非空,并且batch is ready to send readyNodes.add(leader); } } } } } } // nextReadyCheckDelayMs为下一次调用ready的时间间隔 return return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics); }
- 该batch不是backingOff(if batch.attempts() > 0 and waitedTimeMs < retryBackoffMs, backingOff=true)(即batch是失败重发且该batch等待的时长小于重试时间,backingOff=true)
-
至少满足以下条件之一:
- batch有full record;
- batch的等待时长超过了lingerMs(由prodcuer config配置,标记batch的等待时长)
- RecordAccumulator内存不足(默认32M)
- RecordAccumulator被关闭(已经暂存的数据要被发送)
public Map<Integer, List<ProducerBatch>> drain(Cluster cluster, Set<Node> nodes, int maxSize, long now) { Map<Integer, List<ProducerBatch>> batches = new HashMap<>(); // 声明返回的结构 // 遍历所有node for (Node node : nodes) { List<PartitionInfo> parts = cluster.partitionsForNode(node.id()); // 获取该node的partitions // 遍历partiton(注:源码中不是从0开始遍历,有一个startIdx标记从parts的哪一个下标开始遍历),目的是防止某些partiton的记录长时间得不到发送(avoid starvation) List<ProducerBatch> ready = new ArrayList<>(); for (part: parts) { TopicPartition tp = new TopicPartition(part.topic(), part.partition()); if (isMuted(tp)) continue; // 获取partition对应的deque Deque<ProducerBatch> deque = getDeque(tp); synchronized (deque) { // 获取deque的第一个batch ProducerBatch first = deque.peekFirst(); if first == null || backoff { continue } // 本次的batch已经达到了一次发送的最大数据量 if (size + first.estimatedSizeInBytes() > maxSize && !ready.isEmpty()) { break } batch = deque.pollFirst(); // 满足了条件,正式取出 // 事务相关操作,在此不做说明 ... batch.close(); ready.add(batch); } } batches.put(node.id(), ready) } }
4.2 poll
sendProducerData构造好的数据,先缓存到buffer中,需要通过网络发送出去。这一部分是通过KafkaClient实现的。KafkaClient定义了一个kafka client所需的接口,由NetworkClient实现。KafkaClient.poll()负责发送数据。核心代码如下:
public List<ClientResponse> poll(long timeout, long now) { try { // 执行发送,在sendProducerData中,已经将数据包装成request,存放到了selector的channel中 this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs)); } List<ClientResponse> responses = new ArrayList<>(); // 处理本次IO的完成情况 handleCompletedSends(responses, updatedNow); handleCompletedReceives(responses, updatedNow); ... }
Sending requests, receiving responses, processing connection completions, and disconnections on the existing connections are all done using the <code>poll()</code> call.
5. kafka producer总结
kafka producer的发送实现是异步的,由主线程将发送数据缓存到RecordAccumulator中,然后sender线程负责从RecordAccumulator中取数据进行发送。整体架构较为简单,难点在于数据在不同流程和组件中的传递时,其组织格式不一致,数据来回转换,显得较为复杂。虽然kafka的发送机制是异步的,但是我们也可以实现同步发送,或者对发送时出现的异常进行处理(比如重发)。producer的send方法有两个重载函数,如下:
public Future<RecordMetadata> send(ProducerRecord<K, V> record) public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback)
其中第一个send方法返回一个Future对象,利用其可以实现同步发送,对应的同步发送的代码如下:
try { producer.send(record).get(); } catch Exception { // 错误处理 }
以上方法send函数本身是异步的,只是在发送完成之后,通过Future.get阻塞了发送线程而已。
同时,通过注入回调函数,可以在消息发送完成之后,执行该回调函数,实现发送成功的记录,发送失败的重试。
此处对sender线程内部的一些执行细节,没有过多赘述。比如InFlightRequests的大小是可设置的,kafka client会根据InFlightRequests的剩余容量大小,判断某个node的负载大小;可以通过设置ack参数,来设置需要有多少个broker响应一条消息才算发送成功。这些细节在源码和producer的相关配置参数中都有介绍。
6. producer的常见问题
6.1 request.timeout.ms、 linger.ms、batch.size
- request.timeout.ms:producer每次发送数据后等待响应的最长等待时间,默认30000ms;
- linger.ms:Producer攒batch的等待时长。producer每次调用send,只是将数据发送到了RecordAccumulator中,不会立即发送到broker。只有某一个ProducerBatch满了,或者距离上一次发送到达了linger.ms设定的时间,才会再次将ProducerBatch发送到broker,默认为0;
- batch.size:每一个PtoduerBatch的默认大小,默认16384(16KB);
KafkaTimeoutError: Batch for TopicPartition(topic='XXX', partition=XXX) containing 1 record(s) expired: 30 seconds have passed since batch creation plus linger time.
6.2 kafka消费积压问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】