go netpoll源码解析
前言
网络一直是一个老生常谈的内容,谈及网络编程,始终离不开网络编程的五种模型:阻塞IO(Blocking IO),非阻塞IO(Nonblocking IO),多路复用IO(Multiplexing IO),事件驱动IO(Signal driven IO)和异步IO(Asyncronous IO)。而构建一个高性能的网络库,基本都是基于多路复用(epoll, kqueue)或异步IO来实现,在IO之后,通过线程池来实现IO数据处理。go 语言内置的网络库netpoll,整体框架上也是采用这样一种模式。在IO收发上,底层封装了epoll, kqueue, IOCP等操作系统级别的多路复用和异步IO。在IO数据处理上,得益于goroutine的轻量级和高效的并发调度模式,不是采用线程池的思路,而是其特有的one goroutine per connection(每一个连接启用一个goroutine进行处理)。本文主要从源码角度(以epoll为例)分析go netpoll的设计和封装,解释其one goroutine per connection工作原理及其优劣性,然后针对go netpoll的缺点总结现在更为适合的主从reactor模式。期间会涉及网络编程相关知识(主要是多路复用IO),go语言使用与runtime调度的基本原理,需要读者有一定的背景知识。
1. 基本编程模式与数据结构
首先直观对比一下go net的网络编程和epoll的异同。关于epoll基础和IO处理模式,可以参考文献[1][2]。使用go net网络编程,流程如下:
package main import ( "log" "net" ) func main() { Listener, err := net.Listen("tcp", "localhost:9000") if err != nil { log.Println("Listen err: ", err) return } for { conn, err := Listener.Accept() if err != nil { log.Println("Accept err: ", err) continue } go HandleConn(conn) } } func HandleConn(conn net.Conn) { // 处理函数, 调用Read()->处理业务逻辑->调用Write写回 }
可见,go的网络编程是极其简单的,在短短的几行内,底层封装了epoll需要的所有操作,主要包括:
- 调用socket()创建服务端socket,并进行bind();
- 调用epoll_create创建epfd,将服务端socket绑定到epfd,并进行监听;
- 每当新的连接到来,调用accept绑定客户端socket,注册到epfd。
所有的操作,都离不开两个重要的组成:socket描述符和epoll描述符epfd。go netpoll对这些内容进行了封装,主要形成了以下结构体:
// netFD, 可以认为是go net的网络描述符 type netFD struct { pfd poll.FD // 底层封装了socket描述符 // immutable until Close family int sotype int isConnected bool // handshake completed or use of association with peer net string laddr Addr raddr Addr } type FD struct { // Lock sysfd and serialize access to Read and Write methods. fdmu fdMutex // System file descriptor. Immutable until Close. Sysfd int // 保存linux的fd // I/O poller. pd pollDesc // pollDesc变量,用该变量的指针,将所有的socket封装成链表,每个socket对应的goroutine,也封装在pollDesc中,可以说是go net的灵魂部分 // Writev cache. iovecs *[]syscall.Iovec // Semaphore signaled when file is closed. csema uint32 // Non-zero if this file has been set to blocking mode. isBlocking uint32 // Whether this is a streaming descriptor, as opposed to a // packet-based descriptor like a UDP socket. Immutable. IsStream bool // Whether a zero byte read indicates EOF. This is false for a // message based socket connection. ZeroReadIsEOF bool // Whether this is a file rather than a network socket. isFile bool } //pollDesc type pollDesc struct { link *pollDesc // in pollcache, protected by pollcache.lock. pollDesc是一个链表,每当1有新的socket连接时,就会有一个新的pollDesc // The lock protects pollOpen, pollSetDeadline, pollUnblock and deadlineimpl operations. // This fully covers seq, rt and wt variables. fd is constant throughout the PollDesc lifetime. // pollReset, pollWait, pollWaitCanceled and runtime·netpollready (IO readiness notification) // proceed w/o taking the lock. So closing, everr, rg, rd, wg and wd are manipulated // in a lock-free way by all operations. // TODO(golang.org/issue/49008): audit these lock-free fields for continued correctness. // NOTE(dvyukov): the following code uses uintptr to store *g (rg/wg), // that will blow up when GC starts moving objects. lock mutex // protects the following fields,用于对pd进行加锁保护 fd uintptr // 保存网络文件描述符 closing bool everr bool // marks event scanning error happened user uint32 // user settable cookie rseq uintptr // protects from stale read timers rg uintptr // pdReady, pdWait, G waiting for read or nil. Accessed atomically. 用于表示监听的fd是否就绪,只有pdReady, pdWait,等待读取的G,nil取值 rt timer // read deadline timer (set if rt.f != nil) rd int64 // read deadline wseq uintptr // protects from stale write timers wg uintptr // pdReady, pdWait, G waiting for write or nil. Accessed atomically. 作用同rg wt timer // write deadline timer wd int64 // write deadline self *pollDesc // storage for indirect interface. See (*pollDesc).makeArg. }
其中netFD可以认为是go net 的网络描述符,包含了对应的socket;而pollDesc则是更底层的结构体,通过pollDesc组成的链表,将所有socket链接到一起,并且将每个socket绑定的goroutine,封装到pollDesc.wg和pollDesc.rg中(当某个goroutine处于等待IO就绪状态时,pollDesc.rg和wg就用于保存该socket对应的goroutine的结构体g)。然后net.Listen反回的Listener,net.Accept返回的net.Conn,都包含了netFD结构体:
// TCPListener is a TCP network listener. Clients should typically // use variables of type Listener instead of assuming TCP. type TCPListener struct { fd *netFD lc ListenConfig } // TCPConn is an implementation of the Conn interface for TCP network // connections. type TCPConn struct { conn } type conn struct { fd *netFD }
接下来重点介绍,go net是如何通过net.Listen和net.Accept实现以上所有操作的。
2. 等待端(阻塞端)
等待端就是当epoll监听的读写事件到来前,阻塞当前的goroutine;当读写事件到来时,调用对应的处理函数(Accept, Read, Write)。这个过程涵盖了epoll编程中的:
- 服务端socket创建,绑定;epoll的初始化;将服务端socket添加到epoll的监听队列中。都通过net.Listen完成。
- 通过调用accept函数,将服务端goroutine阻塞,直到客户端连接到来。然后将新的客户端连接添加到epoll的监听队列(这个过程跟服务端socket添加到epoll的监听队列一致,底层也是复用同一个函数pollDesc.init)。
- 调用Read,Write函数,将客户端goroutine阻塞,直到客户端读写事件到来,执行业务逻辑(这个过程跟服务端socket的accept逻辑一致,底层也是复用同一个函数pollDesc.WaitRead和pollDesc.waitWrite)。
下面分别分析对应的go net实现。
2.1 net.Listen
2.1.1 创建servsocket
// linux中 servsock=socket(PF_INET,SOCK_STREAM,0) // 创建socket /* go netpoll中 * 调用链:Listen() -> ListenConfig.Listen() -> listenTCP() -> internetSocket() -> socket() * socket()函数如下 */ func socket(ctx context.Context, net string, family, sotype, proto int, ipv6only bool, laddr, raddr sockaddr, ctrlFn func(string, string, syscall.RawConn) error) (fd *netFD, err error) { s, err := sysSocket(family, sotype, proto) //创建servsock if err != nil { return nil, err } if err = setDefaultSockopts(s, family, sotype, ipv6only); err != nil { poll.CloseFunc(s) return nil, err } // 初始化netFD if fd, err = newFD(s, family, sotype, net); err != nil { poll.CloseFunc(s) return nil, err } ... // 调用listenStream() if laddr != nil && raddr == nil { switch sotype { case syscall.SOCK_STREAM, syscall.SOCK_SEQPACKET: if err := fd.listenStream(laddr, listenerBacklog(), ctrlFn); err != nil { fd.Close() return nil, err } return fd, nil case syscall.SOCK_DGRAM: if err := fd.listenDatagram(laddr, ctrlFn); err != nil { fd.Close() return nil, err } return fd, nil } } ... }
2.1.2 绑定servsocket
// Linux中 bind(servsock,(struct sockaddr*)&servaddr,sizeof(servaddr) // 将servsock与一个sockaddr的结构体绑定 /* go netpoll中 */ func (fd *netFD) listenStream(laddr sockaddr, backlog int, ctrlFn func(string, string, syscall.RawConn) error) error { var err error if err = setDefaultListenerSockopts(fd.pfd.Sysfd); err != nil { return err } var lsa syscall.Sockaddr if lsa, err = laddr.sockaddr(fd.family); err != nil { return err } if ctrlFn != nil { c, err := newRawConn(fd) if err != nil { return err } if err := ctrlFn(fd.ctrlNetwork(), laddr.String(), c); err != nil { return err } } if err = syscall.Bind(fd.pfd.Sysfd, lsa); err != nil { return os.NewSyscallError("bind", err) } if err = listenFunc(fd.pfd.Sysfd, backlog); err != nil { return os.NewSyscallError("listen", err) } // 在fd.init中实现创建epfd,监听servsock if err = fd.init(); err != nil { return err } lsa, _ = syscall.Getsockname(fd.pfd.Sysfd) fd.setAddr(fd.addrFunc()(lsa), nil) return nil }
2.1.3 创建epoll实例epfd
// linux中 epoll_event event event.events=EPOLLIN //输入监听 event.data.fd=servsock epfd=epoll_create(20) //创建epoll实例 /* go netpoll中 * 调用链:netFD.init()->pollDesc.init()-> runtime_pollServerInit()->netpollinit() */ // pollDesc.init() func (pd *pollDesc) init(fd *FD) error { // serverInit定义为 var serverInit sync.Once,保证在init函数中runtime_pollServerInit只执行一次;后续的net.Accpet也会调用pollDesc.init,主要目的是调用runtime_pollOpen将客户端连接添加到epfd中 serverInit.Do(runtime_pollServerInit) // 创建epfd,底层根据操作系统,调用netpollinit() ctx, errno := runtime_pollOpen(uintptr(fd.Sysfd)) // 在epfd中监听servsock if errno != 0 { if ctx != 0 { runtime_pollUnblock(ctx) runtime_pollClose(ctx) } return errnoErr(syscall.Errno(errno)) } pd.runtimeCtx = ctx return nil } // 创建epfd并创建一个管道跟epfd通信, 等效于Linux的epoll_create func netpollinit() { epfd = epollcreate1(_EPOLL_CLOEXEC) // 创建epfd实例 if epfd < 0 { epfd = epollcreate(1024) if epfd < 0 { println("runtime: epollcreate failed with", -epfd) throw("runtime: netpollinit failed") } closeonexec(epfd) } r, w, errno := nonblockingPipe() // 创建管道,用于打断epoll_wait的监听等待 if errno != 0 { println("runtime: pipe failed with", -errno) throw("runtime: pipe failed") } ev := epollevent{ events: _EPOLLIN, } *(**uintptr)(unsafe.Pointer(&ev.data)) = &netpollBreakRd errno = epollctl(epfd, _EPOLL_CTL_ADD, r, &ev) // 管道用于监听读事件 if errno != 0 { println("runtime: epollctl failed with", -errno) throw("runtime: epollctl failed") } netpollBreakRd = uintptr(r) netpollBreakWr = uintptr(w) }
go netpoll底层通过识别不同的操作系统,对netpollinit函数有不同的实现,比如在Linux中,调用的是epoll_create(), Mac OS为kqueue(), Windows为IOCP,其他函数在底层调用时,也会根据操作系统自动绑定到具体的实现上。
2.1.4 将servsock添加到epfd的监听对象中
// linux中 epoll_ctl(epfd,EPOLL_CTL_ADD,servsock,&event); //向epfd添加fd的输入监听事件 /* go netpoll中 * 调用链:pollDesc.init() -> runtime_pollOpen() -> poll_runtime_pollOpen() -> netpollopen() */ func poll_runtime_pollOpen(fd uintptr) (*pollDesc, int) { pd := pollcache.alloc() // 申请一个pollDesc, pollDesc是一个链表结构,预先申请好的内存 lock(&pd.lock) wg := atomic.Loaduintptr(&pd.wg) if wg != 0 && wg != pdReady { throw("runtime: blocked write on free polldesc") } rg := atomic.Loaduintptr(&pd.rg) if rg != 0 && rg != pdReady { throw("runtime: blocked read on free polldesc") } pd.fd = fd // 将servsock绑定到pollDesc pd.closing = false pd.everr = false pd.rseq++ atomic.Storeuintptr(&pd.rg, 0) pd.rd = 0 pd.wseq++ atomic.Storeuintptr(&pd.wg, 0) pd.wd = 0 pd.self = pd unlock(&pd.lock) // 初始化 pd.rg和pd.wg,这两个变量用于指示pd.fd是否已经存在可读和可写事件,用于唤阻塞在这个fd上的goroutine errno := netpollopen(fd, pd) // 将servsock添加到epfd的监视队列中 if errno != 0 { pollcache.free(pd) return nil, int(errno) } return pd, 0 } // netpollopen的具体实现 func netpollopen(fd uintptr, pd *pollDesc) int32 { var ev epollevent ev.events = _EPOLLIN | _EPOLLOUT | _EPOLLRDHUP | _EPOLLET *(**pollDesc)(unsafe.Pointer(&ev.data)) = pd // 将pollDesc结构体绑定到epoll_event.data上 return -epollctl(epfd, _EPOLL_CTL_ADD, int32(fd), &ev) // 调用epollctl }
总结
2.2 net.Accept
- 创建客户端连接的socket,用于初始化客户端netFD。
- 调用netFD.init()函数,由net.Listen的分析可知,这一步主要用于将客户端连接的socket添加到epfd中。
// Listener.Accept调用的是netFD.cccept。 func (fd *netFD) accept() (netfd *netFD, err error) { d, rsa, errcall, err := fd.pfd.Accept() // 底层为linux accept,获取到客户端socket if err != nil { if errcall != "" { err = wrapSyscallError(errcall, err) } return nil, err }
// 初始化netFD if netfd, err = newFD(d, fd.family, fd.sotype, fd.net); err != nil { poll.CloseFunc(d) return nil, err } // 跟net.Listen()中的net.init()是一个函数,主要用于将客户端socket添加到epfd中 if err = netfd.init(); err != nil { netfd.Close() return nil, err } lsa, _ := syscall.Getsockname(netfd.pfd.Sysfd) netfd.setAddr(netfd.addrFunc()(lsa), netfd.addrFunc()(rsa)) return netfd, nil }
// Accept wraps the accept network call. func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) { if err := fd.readLock(); err != nil { return -1, nil, "", err } defer fd.readUnlock() // 添加读写锁 // prepareRead主要检查是否读写超时 if err := fd.pd.prepareRead(fd.isFile); err != nil { return -1, nil, "", err } for { // 由于服务端socket设置成了非阻塞模式,所以会立即返回,因此需要for循环 s, rsa, errcall, err := accept(fd.Sysfd) if err == nil { return s, rsa, "", err } switch err { case syscall.EINTR: continue case syscall.EAGAIN: if fd.pd.pollable() { // waitRead将当前goroutine挂起,直到有读取事件到来时,再度恢复运行 if err = fd.pd.waitRead(fd.isFile); err == nil { continue } } case syscall.ECONNABORTED: // This means that a socket on the listen // queue was closed before we Accept()ed it; // it's a silly error, so try again. continue } return -1, nil, errcall, err } }
1. 为什么每个socket加读写锁
2.3 Read和Write
func (fd *FD) Read(p []byte) (int, error) { // 添加读写锁 if err := fd.readLock(); err != nil { return 0, err } defer fd.readUnlock() if len(p) == 0 { // If the caller wanted a zero byte read, return immediately // without trying (but after acquiring the readLock). // Otherwise syscall.Read returns 0, nil which looks like // io.EOF. // TODO(bradfitz): make it wait for readability? (Issue 15735) return 0, nil } // 通过pollDesc.prepareRead()检查fd并初始化对应的fd状态 if err := fd.pd.prepareRead(fd.isFile); err != nil { return 0, err } if fd.IsStream && len(p) > maxRW { p = p[:maxRW] } for { // 调用系统的读写函数 n, err := ignoringEINTRIO(syscall.Read, fd.Sysfd, p) if err != nil { n = 0 if err == syscall.EAGAIN && fd.pd.pollable() { // 没有发生读写事件,通过waitRead()挂起当前goroutine if err = fd.pd.waitRead(fd.isFile); err == nil { continue } } } err = fd.eofError(n, err) return n, err } }
{ pollDesc.prepareRead() ... for { read()/write()/accpet() if no_read/no_write/no_accpet { pollDesc.waitRead()/waitWrite() } } }
而pollDesc.waitRead(pollDesc.waitWrite)就是等待端的主角,它将一个socket和其对应的goroutine联系到了一起。
2.4 pollDesc.waitRead和pollDesc.waitWrite
func poll_runtime_pollWait(pd *pollDesc, mode int) int { errcode := netpollcheckerr(pd, int32(mode)) if errcode != pollNoError { return errcode } // As for now only Solaris, illumos, and AIX use level-triggered IO. if GOOS == "solaris" || GOOS == "illumos" || GOOS == "aix" { netpollarm(pd, mode) } for !netpollblock(pd, int32(mode), false) { errcode = netpollcheckerr(pd, int32(mode)) if errcode != pollNoError { return errcode } // Can happen if timeout has fired and unblocked us, // but before we had a chance to run, timeout has been reset. // Pretend it has not happened and retry. } return pollNoError } // returns true if IO is ready, or false if timedout or closed // waitio - wait only for completed IO, ignore errors // Concurrent calls to netpollblock in the same mode are forbidden, as pollDesc // can hold only a single waiting goroutine for each mode. func netpollblock(pd *pollDesc, mode int32, waitio bool) bool { // gpp指向pd对应的rg或wg,在介绍pollDesc时描述过,rg和wg只有pdReady, pdWait, 等待读写的G或nil四种状态,用于表示该io是否可用,从而选择挂起或唤醒对应的goroutine gpp := &pd.rg if mode == 'w' { gpp = &pd.wg } // set the gpp semaphore to pdWait for { // 已经就绪了,直接返回true // Consume notification if already ready. if atomic.Casuintptr(gpp, pdReady, 0) { return true } // 否则,将gpp设置为pdWait if atomic.Casuintptr(gpp, 0, pdWait) { break } // Double check that this isn't corrupt; otherwise we'd loop // forever. if v := atomic.Loaduintptr(gpp); v != pdReady && v != 0 { throw("runtime: double wait") } } // need to recheck error states after setting gpp to pdWait // this is necessary because runtime_pollUnblock/runtime_pollSetDeadline/deadlineimpl // do the opposite: store to closing/rd/wd, membarrier, load of rg/wg if waitio || netpollcheckerr(pd, mode) == pollNoError { // 通过gopark()挂起当前的goroutine,直到新的读写事件来临 gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5) } // 新的读写事件到来,获取gpp的值,判断其是否为pdReady,并将pollDesc.rd重置 // be careful to not lose concurrent pdReady notification old := atomic.Xchguintptr(gpp, 0) if old > pdWait { throw("runtime: corrupted polldesc") } return old == pdReady }
可以看到,底层是通过gopark来阻塞对应的goroutine的,gopark内部直接调用runtime调度相关的函数,用于挂起或执行对应的goroutine。
2.4.1 gopark如何挂起或执行goroutine
gopark的源代码如下:func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) { if reason != waitReasonSleep { checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy } mp := acquirem() gp := mp.curg status := readgstatus(gp) if status != _Grunning && status != _Gscanrunning { throw("gopark: bad g status") } mp.waitlock = lock mp.waitunlockf = unlockf gp.waitreason = reason mp.waittraceev = traceEv mp.waittraceskip = traceskip releasem(mp) // can't do anything that might move the G between Ms here. mcall(park_m) }
gopark调用了park_m,而park_m的源码如下:
// park continuation on g0. func park_m(gp *g) { _g_ := getg() if trace.enabled { traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip) } casgstatus(gp, _Grunning, _Gwaiting) dropg() // 调用gopark传递进来的netpollblockcommit函数 if fn := _g_.m.waitunlockf; fn != nil { ok := fn(gp, _g_.m.waitlock) _g_.m.waitunlockf = nil _g_.m.waitlock = nil if !ok { if trace.enabled { traceGoUnpark(gp, 2) } casgstatus(gp, _Gwaiting, _Grunnable)
// 就绪,执行对应的goroutine execute(gp, true) // Schedule it back, never returns. } }
//未就绪,调用schedule重新调度
schedule()
}
理解gopark和park_m的关联有一个关键点。首先,gopark将当前的goroutine.m.waitunlockf设置为了netpollblockcommit函数(通过gopark函数调用时,传入的unlockf参数为netpollblockcommit),而park_m首先获取了当前的g,然后调用了g.m.waitunlockf(即gopark传进去的netpollblockcommit)。可见,gopark和park_m通过当前的goroutine这一个关系联系到了一起(执行gopark和park_m的为同一个goroutine), 最终执行了netpollblockcommit。而netpollblockcommit函数做的事情,就是把每个socket对应goroutine绑定到对应的pollDesc.rg(wg)中。源码如下:
// netpollblockcommit检查当前的状态是否是pdWait:是,则将当前的gorouttine的*g放入pollDesc.rg或wg中,返回true;否,则说明当前的goroutine等待的事件已经ready,返回false func netpollblockcommit(gp *g, gpp unsafe.Pointer) bool { r := atomic.Casuintptr((*uintptr)(gpp), pdWait, uintptr(unsafe.Pointer(gp))) // gpp即netpollblock中,将pollDesc.rg(wg)赋值给了它,此处将当前goroutine的结构体g赋值给了gpp if r { // Bump the count of goroutines waiting for the poller. // The scheduler uses this to decide whether to block // waiting for the poller if there is nothing else to do. atomic.Xadd(&netpollWaiters, 1) } return r }
至此,等待端的所有事情都已经完成。通过在netpollopen中,将epoll的监听事件epoll_event.data绑定到对应的pollDesc结构体上;而在waitRead,waitWrite中,将goroutine绑定到pollDesc.wg和rg中,并挂起对应的goroutine(当socket无就绪事件时),完成等待端的所有操作。当一个socket就绪时,就能直接从epoll_event.data.wg(rg)获取到就绪的goroutine,加入runtime调度。而这就是就绪执行端做的事情。
3. 就绪执行端
前面已经分析了等待端的行为,而就绪执行端(epoll_wait)只需要在epoll_wait响应返回之后,取出对应的ev.data.rg(wg),重新加入runtime调度队列即可。这个过程就是通过netpoll实现的。netpoll对应的源码如下:// netpoll checks for ready network connections. // Returns list of goroutines that become runnable. // delay < 0: blocks indefinitely // delay == 0: does not block, just polls // delay > 0: block for up to that many nanoseconds // gList表示所有的就绪goroutine func netpoll(delay int64) gList { if epfd == -1 { return gList{} } // 计算epoll_wait的等待时间 var waitms int32 if delay < 0 { waitms = -1 } else if delay == 0 { waitms = 0 } else if delay < 1e6 { waitms = 1 } else if delay < 1e15 { waitms = int32(delay / 1e6) } else { // An arbitrary cap on how long to wait for a timer. // 1e9 ms == ~11.5 days. waitms = 1e9 } var events [128]epollevent retry: // 调用epoll_wait n := epollwait(epfd, &events[0], int32(len(events)), waitms) if n < 0 { if n != -_EINTR { println("runtime: epollwait on fd", epfd, "failed with", -n) throw("runtime: netpoll failed") } // If a timed sleep was interrupted, just return to // recalculate how long we should sleep now. if waitms > 0 { return gList{} } goto retry } var toRun gList for i := int32(0); i < n; i++ { ev := &events[i] if ev.events == 0 { continue } // 判断epoll_wait是否是被打断 if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd { if ev.events != _EPOLLIN { println("runtime: netpoll: break fd ready for", ev.events) throw("runtime: netpoll: break fd ready for something unexpected") } if delay != 0 { // netpollBreak could be picked up by a // nonblocking poll. Only read the byte // if blocking. var tmp [16]byte read(int32(netpollBreakRd), noescape(unsafe.Pointer(&tmp[0])), int32(len(tmp))) atomic.Store(&netpollWakeSig, 0) } continue } var mode int32 if ev.events&(_EPOLLIN|_EPOLLRDHUP|_EPOLLHUP|_EPOLLERR) != 0 { mode += 'r' } if ev.events&(_EPOLLOUT|_EPOLLHUP|_EPOLLERR) != 0 { mode += 'w' } if mode != 0 { // 因为pollDesc保存在epoll_event.data中,而goroutine保存在pollDesc.rg和pollDeesc.wg中,通过epoll_event.data就能拿到阻塞的goroutine pd := *(**pollDesc)(unsafe.Pointer(&ev.data)) pd.everr = false if ev.events == _EPOLLERR { pd.everr = true } // 将就绪的goroutines放到就绪队列 netpollready(&toRun, pd, mode) } } return toRun } // netpollready()唤醒就绪的goroutine func netpollready(toRun *gList, pd *pollDesc, mode int32) { var rg, wg *g if mode == 'r' || mode == 'r'+'w' { // netpollunblock()负责从pollDesc中取出goroutine(g) rg = netpollunblock(pd, 'r', true) } if mode == 'w' || mode == 'r'+'w' { wg = netpollunblock(pd, 'w', true) } if rg != nil { toRun.push(rg) } if wg != nil { toRun.push(wg) } } // netpollunblock()负责从pollDesc中取出goroutine(g) func netpollunblock(pd *pollDesc, mode int32, ioready bool) *g { gpp := &pd.rg if mode == 'w' { gpp = &pd.wg } for { old := atomic.Loaduintptr(gpp) // 已经是就绪事件,没有新的就绪事件发生,就没有需要唤醒的g if old == pdReady { return nil } if old == 0 && !ioready { // Only set pdReady for ioready. runtime_pollWait // will check for timeout/cancel before waiting. return nil } var new uintptr if ioready { new = pdReady } // 将pollDesc.rg置为pdReady并返回g if atomic.Casuintptr(gpp, old, new) { if old == pdWait { old = 0 } return (*g)(unsafe.Pointer(old)) } } }
相对于等待端,就绪执行端的函数直接很多。就是epoll_wait检查就绪的socket,取出就绪的ev.data.rg,然后返回所有就绪的gList。
3.1 何时调用netpoll
netpoll只是返回了就绪的gList,但是还需要有函数来调用它,将就绪的gList重新放回runtime调度。换言之,唤醒goroutine是一个runtime重新调度的过程。
// schedule()函数调度时会调用findrunnable()找到就绪goroutine放入p中 func findrunnable() (gp *g, inheritTime bool) { ... // 优先检查是否已经有网络io就绪。此函数在本地P上没有可执行的G时,在steal from others 之前执行,如果有网络io就绪,立即唤醒并调度该goroutine。因此nepoll(0)(非阻塞调用) // Poll network. // This netpoll is only an optimization before we resort to stealing. // We can safely skip it if there are no waiters or a thread is blocked // in netpoll already. If there is any kind of logical race with that // blocked thread (e.g. it has already returned from netpoll, but does // not set lastpoll yet), this thread will do blocking netpoll below // anyway. if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 { // 拿到就绪的goroutine,通过injectglist()将就绪的goroutine放入p中进行调度 if list := netpoll(0); !list.empty() { // non-blocking gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false } } ... // 再次调用netpoll,此次是阻塞调用 if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 { atomic.Store64(&sched.pollUntil, uint64(pollUntil)) if _g_.m.p != 0 { throw("findrunnable: netpoll with p") } if _g_.m.spinning { throw("findrunnable: netpoll with spinning") } delay := int64(-1) if pollUntil != 0 { if now == 0 { now = nanotime() } delay = pollUntil - now if delay < 0 { delay = 0 } } if faketime != 0 { // When using fake time, just poll. delay = 0 } list := netpoll(delay) // block until new work is available atomic.Store64(&sched.pollUntil, 0) atomic.Store64(&sched.lastpoll, uint64(nanotime())) if faketime != 0 && list.empty() { // Using fake time and nothing is ready; stop M. // When all M's stop, checkdead will call timejump. stopm() goto top } lock(&sched.lock) _p_ = pidleget() unlock(&sched.lock) if _p_ == nil { injectglist(&list) } else { acquirep(_p_) if !list.empty() { gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false } if wasSpinning { _g_.m.spinning = true atomic.Xadd(&sched.nmspinning, 1) } goto top } } }
2. 在sysmon监控中调用。sysmon是golang设置的监控线程(是一个系统级的daemon),独立于G-M-P的所有模型之外,不与逻辑P绑定而直接在M上运行。他跟其他G-M-P的关系如下:
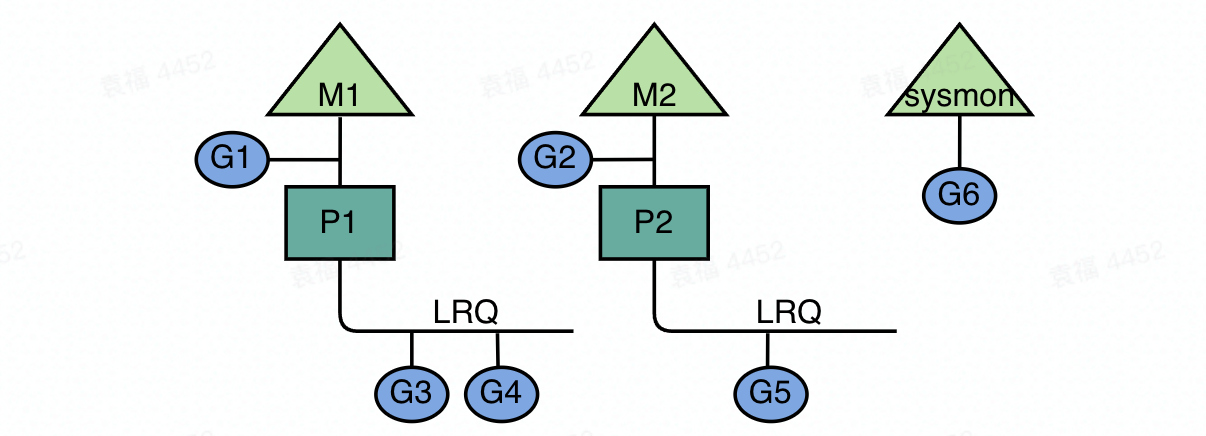
func sysmon() { ... lastpoll := int64(atomic.Load64(&sched.lastpoll)) if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now { atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now)) list := netpoll(0) // non-blocking - returns list of goroutines if !list.empty() { // Need to decrement number of idle locked M's // (pretending that one more is running) before injectglist. // Otherwise it can lead to the following situation: // injectglist grabs all P's but before it starts M's to run the P's, // another M returns from syscall, finishes running its G, // observes that there is no work to do and no other running M's // and reports deadlock. incidlelocked(-1) injectglist(&list) incidlelocked(1) } } ... }
注:等待端和就绪端中间是通过golang的runtime调度(G-M-P调度模型)联系到一起的,等待端挂起goroutine,就绪端重新将goroutine放入调度队列,此部分需要对GPM调度模型有个基本的了解,才能理解整个过程。GMP的调度可以参看文献[3]。
4. 总结
4.1 go netpoll执行流
-
goroutine是golang特有的轻量级线程,在用户空间进行调度,结合golang的runtime调度模型,其调度所需资源远小于线程。因此使得之前不适用的多线程IO处理重新大放异彩。
-
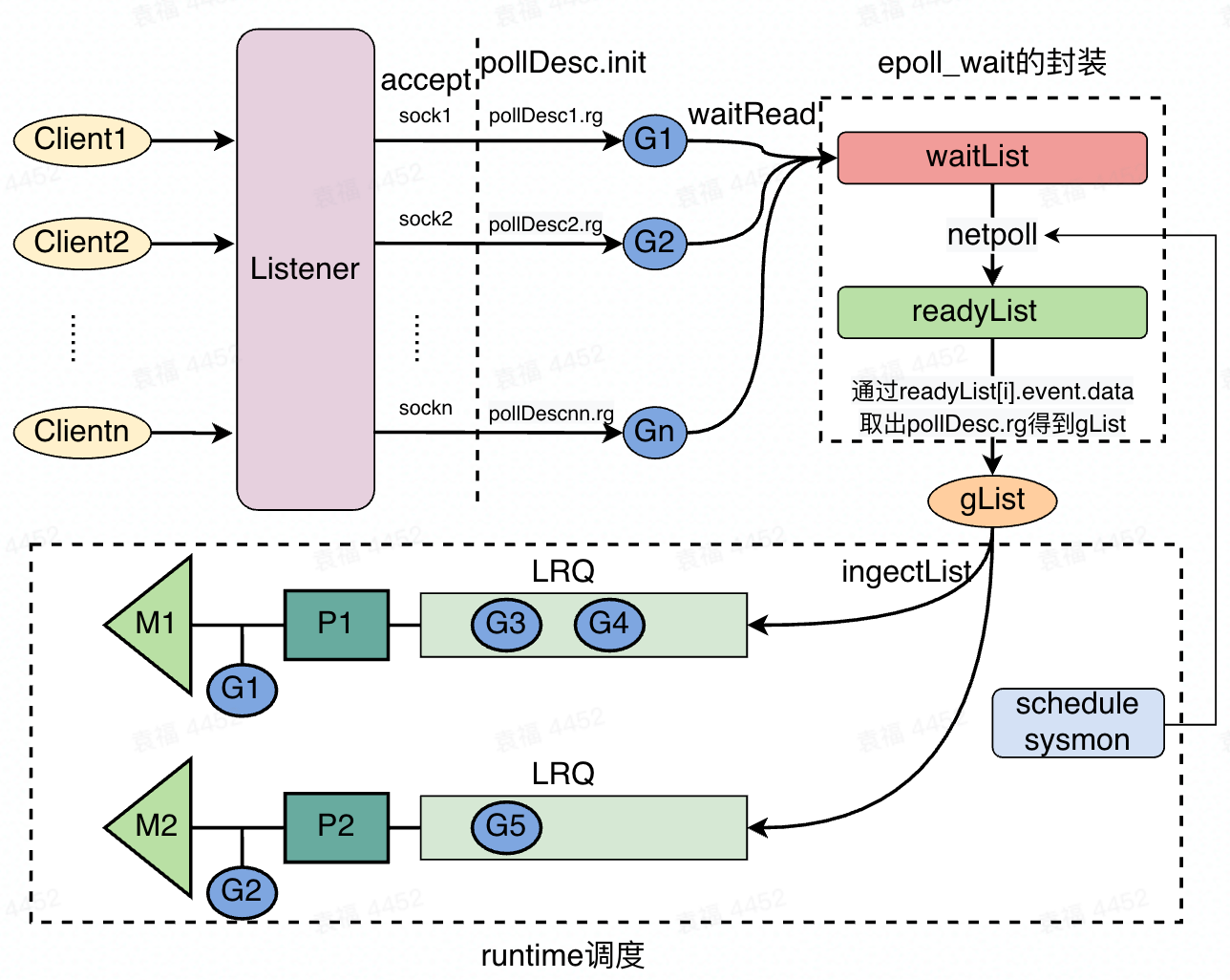
通过封装,golang利用其runtime调度,将IO等待与IO读写执行分离开来。通过pollDeesc.waitRead()和pollDesc.waitWrite(),将goroutine加入到epoll的等待队列,完成等待端的处理;通过netpoll(),将goroutine从等待端唤醒,重新放入就绪可调度的状态;而连接等待和执行的,就是golang强大的G-M-P调度模型。整个调度过程如下图:
4.2 关于go netpoll带来的启示
void ListenAndServe() { // 1. 创建并绑定服务端socket servsock // 2. 绑定servsock到epoll epoll_event event; event.events=EPOLLIN; //输入监听 event.data.fd=servsock; int epfd=epoll_create(20); //创建epoll例程 epoll_ctl(epfd,EPOLL_CTL_ADD,servsock,&event); //向epfd添加fd的输入监听事件 struct epoll_event* events; events=(epoll_event*)malloc(sizeof(struct epoll_event)*EPOLL_SIZE); //申请存放发生事件的数组 // 3. 循环监听 while(1) { int event_cnt=epoll_wait(epfd,events,EPOLL_SIZE,-1); //设置无限等待 if(event_cnt==-1) printf("epoll_wait() error"); for(int i=0;i<event_cnt;i++) { // 4. 服务端连接请求 if(events[i].data.fd==servsock) //说明是新的客户端请求 { // 调用accept进行连接并注册新的epoll监听 clntsock=accept(...); event.events=EPOLLIN; event.data.fd=clntsock; //通过event.data.fd存放clntsock,用于标记返回的event属于哪个socket epoll_ctl(epfd,EPOLL_CTL_ADD,clntsock,&event); //将新申请的连接加入epfd } else { // 5. 客户端读写事件,进行相应的处理 } } } ... } }
4.3 优缺点分析
4.4 主从Reactor模型
go netpoll对于编写小规模网络应用,应该是绰绰有余的。但是,对于大型互联网公司的大量http和rpc请求,无限制的开启goroutine且没有服务降级是致命的,当大量的请求同时到达时,会直接导致golang的runtime调度瘫痪,因此大型公司往往都会基于操作系统的多路复用,封装自己的网络库。其中比较经典的模型是主从Reactor模型。主从Reactor模型通常由一个主reactor线程,一个从actor线程(或者多个),一个worker线程池组成。主reactor负责服务端socket的监听事件,并将连接的客户端socket封装成connection交给从reactor;从reactor专门负责接收read/write事件,将收到的数据发送给worker进行业务处理;worker即一个线程池(协程池),负责处理读写之后的业务逻辑。如下图所示: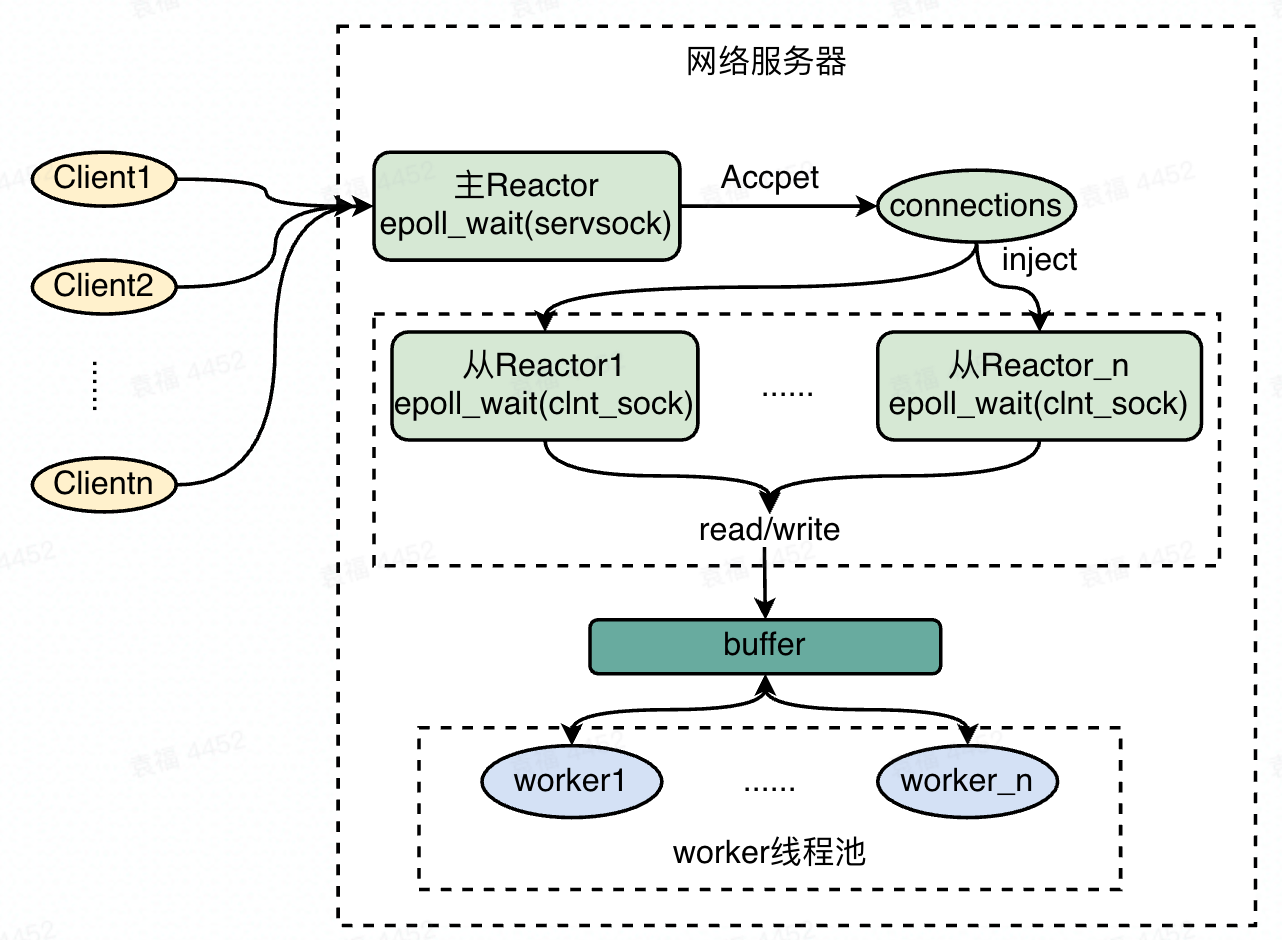
参考文献
[2] 如果这篇文章说不清epoll的本质,那就过来掐死我吧!
[3] Scheduling In Go : Part II - Go Scheduler
[5] go语言设计与实现 6.6小节

