
2019北航面向对象课程第三单元作业(JML规格)个人总结
第三单元的3次作业,其主题都是在阅读jml规格的基础上完成程序,实现相应的功能(虽然我觉得这是数据结构+++,感受十分不好,tle杀我)。3次作业的内容,分别是:实现Path路径类和PathContainer路径容器类、实现Path路径类和在PathContainer路径容器类基础上扩展生成的Graph图类、实现Path路径类和在Graph图类基础上扩展生成的RailwaySystem地铁信息查询类。
在这次博客作业中,我将尽力完成以下内容:
(1)梳理JML语言的理论基础、应用工具链情况
(2)部署SMT Solver,并选择至少3个主要方法进行验证,报告结果
(3)部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例,结合规格对生成的测试用例和数据进行简要分析
(4)按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
(5)按照作业分析代码实现的bug和修复情况
(6)阐述对规格撰写和理解上的心得体会
一、梳理JML语言的理论基础、应用工具链情况
1、理论基础
在面向对象编程思想中,有一个十分重要的思考原则,即:推迟过程性思考——先思考要干什么,而不是怎么干(即,具体下一步如何进行)。因此,我们引入Java建模语言JML(Java Modeling Language)来表达对“要干什么”的思考与思考结果。一般认为,JML是一种行为接口的规范语言,可以用来指定Java模块的行为,其最基本的用途是作为Java的合同设计(DBC)语言。
一般而言,JML有两种主要的用法:
① 开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
② 针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
2、基础内容
(1)注释结构
行注释://@annotation
块注释:/*@ annotation @*/
两种注释方法均适用@开头,并将JML注释放在被注释成分的近邻上部。
(2)常见表达式
①原子表达式
\result表达式:表示一个非 void 类型的方法执行所获得的结果,即方法执行后的返回值。这里此表达式的类型根据被注释的函数的返回值而定。
\old(expr)表达式:用来表示一个表达式expr在相应方法执行前的取值。当expr有被修改时,使用此表达式,表示expr被修改之前的值。这里有一点需要注意,对于一个引用对象,只能判断引用本身是否发生变化,即只能描述引用对象的地址是否发生变化,而不能描述对象的成员变量等是否发生变化。
\not_assigned(x,y,…)表达式:用来表示括号中的变量是否在方法执行过程中被赋值。
\not_modified(x,y,…)表达式:限制括号中的变量在方法执行期间的取值未发生变化。
\nonnullelements(container)表达式:表示container对象中存储的对象不会有null。
②量化表达式
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。使用的结构如下:
(\forall 类型 变量; 变量满足的限制; 在限制条件下的结果)
以下几种表达式均有类似的使用结构。
\exists表达式:与forall表达式使用结构类似,为存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\min表达式:返回给定范围内的表达式的最小值。
\num_of表达式:返回指定变量中满足相应条件的取值个数。
③ 操作符
子类型关系操作符E1<:E2,如果类型E1是类型E2的子类型(sub type),则该表达式的结果为真,否则为假。如果E1和E2是相同的类型,该表达式的结果也为真。
等价关系操作符b_expr1<==>b_expr2或者 b_expr1<=!=>b_expr2,其中b_expr1和b_expr2都是布尔表达式,这两个表达式的意思是 b_expr1==b_expr2 或者b_expr1!=b_expr2 。
推理操作符b_expr1==>b_expr2 或者 b_expr2<==b_expr1,即数理逻辑中的蕴含运算。
变量引用操作符
\nothing 表示空集;
\everything 表示全集。
(3)方法规格
①前置条件(pre-condition):对调用者的限制,即要求调用者确保条件为真。
②后置条件(post-condition):对方法实现者的要求,即方法实现者确保方法执行返回结果一定满足谓词的要求,即确保后置条件为真。
③副作用范围限定(side-effects):
assignable 表示可赋值
modifiable 表示可修改
多数情况下二者可以交换使用
④ signals子句
signals子句的结构为signals (Exception e) b_expr,当b_expr为true时,方法会抛出括号中给出的相应异常e。signals_only子句是对signals子句的简化版本,不强调对象状态条件,强调满足前置条件时抛出相应的异常。
(4)类型规格
①不变式invariant
不变式是要求在所有可见状态下都必须满足的特性。可见状态主要包含以下几种:
对象的有状态构造方法(用来初始化对象成员变量初值)的执行结束时刻
在调用一个对象回收方法(finalize方法)来释放相关资源开始的时刻
在调用对象o的非静态、有状态方法(non-helper)的开始和结束时刻
在调用对象o对应的类或父类的静态、有状态方法的开始和结束时刻
在未处于对象o的构造方法、回收方法、非静态方法被调用过程中的任意时刻
在未处于对象o对应类或者父类的静态方法被调用过程中的任意时刻
②状态变化约束constraint
可以认为状态变化约束比上面的不变式放宽了一定的限制,它并不要求一定不发生变化,而是在变化过程中形成要满足一定的约束条件。
3、应用工具链
(1)openJML
首先,通过开源的JML编译器(在此处我们选择openJML),编译含有JML标记的代码。可以根据JML对实现进行静态的检查,其中用于进行JML分析的部分在solvers中,包括常见的如cvc4以及z3。
在openJML中,“-check”选项可以对生成的类文件进行JML规范检查。openJML中还包含z3等SMT Solver,可以对代码等价性进行验证。通过openJML“-esc”选项对代码的静态验证是不依赖JML的,SMT Solver会自动整理JML。
(2)JMLUnitNG
JML UnitNG可以生成一个Java类文件测试的框架,基于JML并结合Openjml“-rac”选项运行时检查选项,可以根据JML自动生成对应的测试样例,用于进行单元化、自动化测试(实践证明,这种测试主要是边界测试)。
JMLdoc工具与Javadoc工具类似,可在生成的HTML格式文档中包含JML规范。
二、部署SMT Solver,并选择至少3个主要方法进行验证,报告结果
1、SMT Solver简介
SMT(Staisfiability modulo theories) Solver,是一个定理证明器其工作机理是:openJML将JML规范转换为SMT-LIB格式,并将Java+JML程序所隐含的证明问题传递给后端SMT求解器。
openJML支持主要的SMT解决方案,如Z3、CVC4和YIES;其证明的成功将取决于SMT解算器的能力、代码+规范的特定逻辑编码以及代码和规范编写的复杂性和样式。
2、工作原理
OpenJML将JML规范转换为SMT-LIB格式,并将Java+JML程序所隐含的证明问题传递给后端SMT求解器。
OpenJML支持主要的SMT解决方案,如Z3、CVC4和YIES。
证明的成功将取决于SMT解算器的能力(例如,它支持哪些逻辑)、代码+规范的特定逻辑编码以及代码和规范编写的复杂性和样式。
3、尝试进行检查

运用指令“openjml -check .\Exp\Main.java”进行格式检查,无误。
删除第二行注释末尾的一个分号,再次进行格式检查,发现会报错:

恢复第二行的分号。运用指令“openjml -esc -prove .\Exp\Main.java”进行静态审查。返回了许多报错,其中部分如下:
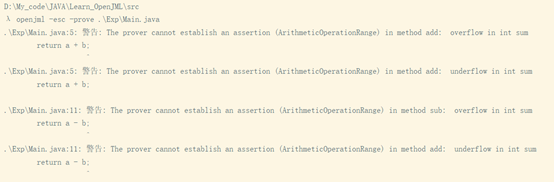
三、部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例,结合规格对生成的测试用例和数据进行简要分析
依然是对这个程序进行测试。

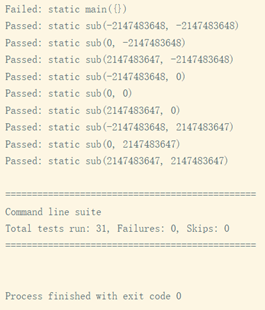
使用指令“java -jar ..\..\openjml\jmlunitng.jar .\Exp\Main.java”自动生成众多测试文件。对这些文件进行编译,进行运行测试,得到如下结果:

四、按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
1、第9次作业
(1)结构分析
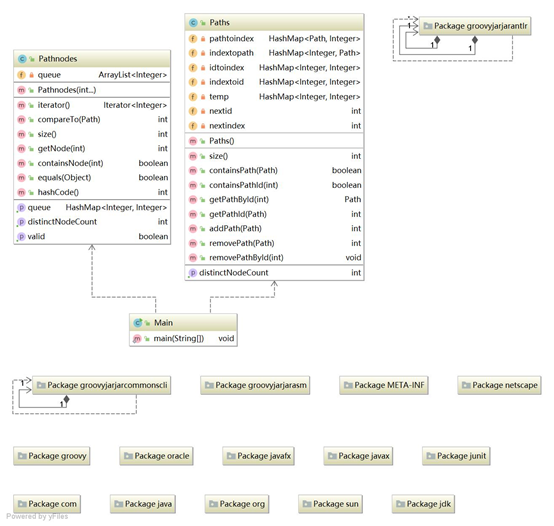
第9次作业整体上比较简单,需要完成Path路径类和PathContainer路径容器类。MyPath主要通过Arraylist顺序保存某路径(即某Path型变量)中的点,并通过Hashmap保存改路径中所有不同的点(这样设计,在需要判断该path中有多少个不同的点时,只需要返回对应hashmap的大小即可)。同时,为方便判断该path中是否含有某个具体的点,用点的序号作为hashmap的key值,用该点在该路径中出现的次数作为hashmap的value,即可通过containskey()判断该点是否存在。同时,通过阅读指导书可以知道,还需要完成迭代器函数、字典序比较函数、equals()函数和hashcode()函数。
MyPathContainer涉及到对多条Path的Pathid分配,储存,判断是否存在,增加和删除操作。在这里,我使用了4个HashMap,分别表示path到index,index到path,pathid到index和index到pathid的对应关系。使用nextid和nextpathindex用于获取下一条增加的路径对应的pathid和index。同时,再用1个HashMap存储所有路径中的不同节点(用点的序号作为hashmap的key值,用该点在所有路径中出现的次数作为hashmap的value)。此处主要需要注意的是,在addpath,removepath时需要同时维护共计5个的hashmap,特别是存储不同节点的hashmap。
(2)复杂度与依赖度分析
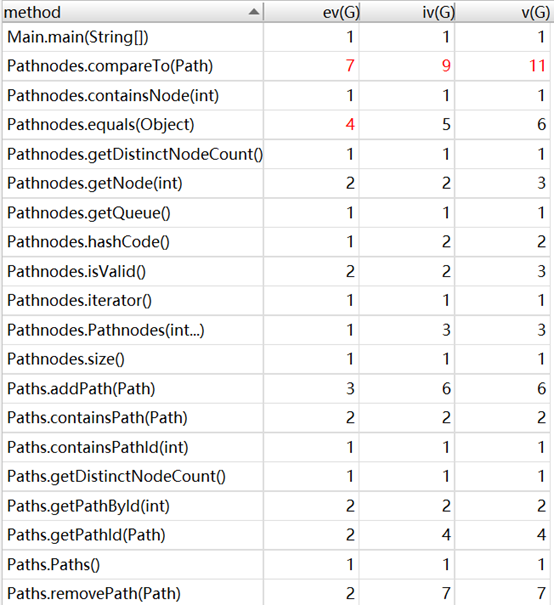
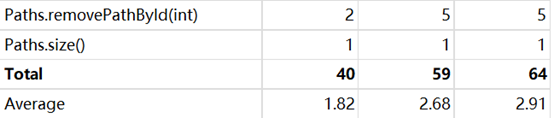
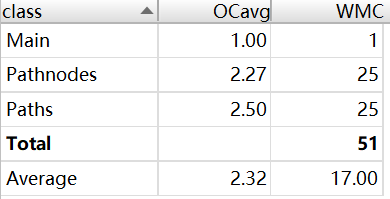
从整体上看,第9次作业的复杂度、相互之间的依赖度处于比较合理的范围内。其中,MyPath类compareTo方法的复杂度最高,但我认为实现这一方法的功能,循环遍历无法避免,且需要遍历的内容不会过大,因此在可接受的范围内。
2、第10次作业
(1)结构分析

我的第10次作业主要是在第9次作业的基础上完成的。我的4个类中:
Main类负责按照要求调用AppRunner函数
Pathnodes类全面继承第9次作业的Pathnodes类(在debug的过程中,我一度以为我的一个bug的错误是因为hashcode的原因,因此可能稍微改变了Pathnodes类中的hashcode函数)。
Pathgraph类一部分继承自第9次作业的PathContainer类,主要负责存储不同的Path路径,并完成Graph类要求的功能函数。
Edges类的构造,主要是为了与hashmap结合,表示“一条边中fromnode+tonode+通一条边的出现次数”这样的关系。
就整个程序的运行而言:
每当需要增加一个path类型的量(增加一条路径),调用Pathgraph类的addPath函数。首先判断这个path的合法性,不合法,返回0。合法,判断是否已经含有一条一模一样的路径(这一步判断的正确实现,依赖于Pathnodes类的equals函数,需要两个path型变量对应节点位置和对应节点序号完全相同,节点数完全相同,才能判断是同一path;也就是说,“1 2 3”和“1 2 3 4”不是同一路径,“1 2”和“2 1”也不是同一路径)。
如果不包含一模一样的path,那么,需要为这个path分配pathid,为这组path+pathid的组合分配index,并将它们存进从第9次作业继承来的pathtoindex、indextopath、pathidtoindex、indextooathid中去,并且更新用于存储所有path不同点和点出现次数的temp。
每当需要删除一个path类型的量(删除一条路径),调用Pathgraph类的removePath函数或者removePathById函数。首先判断这个path的合法性,以及当前已有路径中是否包含这个path,如果不合法或者不包含,则抛出异常。
在此基础上,需要把这个path从pathtoindex、indextopath、pathidtoindex、indextooathid中删掉,并且更新用于存储所有path不同点和点出现次数的temp。
在判断是否相连,或者求最短距离时,需要在判断是否有一条路径包含起点、终点,搜索往次广度遍历保存结果的情况下,返回对应正确结果,或者在进行一次确定起点的广度遍历,再返回对应结果。
我的“判断是否相连”,或者“求最短距离”两个功能,调用的是同一个广度遍历函数,准确地说,是“判断是否相连”调用广度遍历函数,“求最短距离”调用“判断是否相连”。而在“判断是否相连”调用广度遍历函数时,需要设置好传入广度遍历函数的参数。
我按照近似于“树”的方式理解对于无向图的广度优先遍历,即从树顶由上至下一层层遍历:list表示即将被遍历的一层中的所有点(到起始点距离——深度相同的所有点,永远是处于同一层的所有点),check表示已经被遍历过的所有点(从起始点所在树顶到当前层的所有点)。然后开始一层层进行广度遍历。
每到达新的一层,都要保存起始点到当前层所有点的距离(能被遍历到的点,一定从起始点可达)。如果当前层包含终止点,那么,广度遍历就停止在当前层,否则,要为下一层准备新的list和check,并且调用自身。如果待查找的队列空,且未找到终止点,那么说明起始点到终止点不可达,存 -1 。
(2)复杂度与依赖度分析

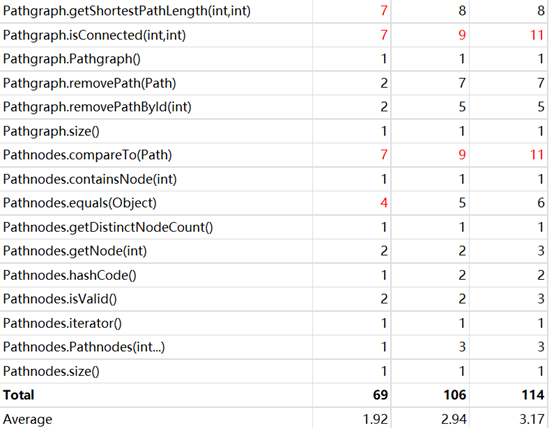
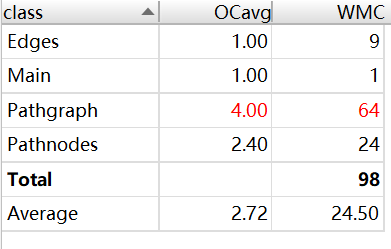
这次作业复杂度较高的地方,主要在于广度遍历的部分。我认为,这一部分的复杂度是无法大幅度降低的,无论选择怎样的方式(Floyd、dijkstra、bfs、dfs),总避免不了某种程度上的遍历。通过测试,实践证明,现行方法(bfs)是完全可以满足测试的要求的。
3、第11次分析
(1)结构分析

我的第11次作业主要是在第10次作业的基础上完成的。在我的10个类中:
Main类负责按照要求调用AppRunner函数
ThePath类全面继承第10次作业的Pathnodes类(在debug的过程中,我一度以为我的一个bug的错误是因为hashcode的原因,因此可能稍微改变了ThePath类中的hashcode函数)。
TheRailwaySystem类一部分继承自第10次作业的Pathgraph类,主要负责存储不同的Path路径,并完成MyRailwaySystem类要求的功能函数。同时,由于涉及到对连通块个数的判断,我构造了新的Chart类,来储存一个连通块。TheRailwaySystem类的“是否相连”“最短距离”“最低票价”等功能,都需要先判断具体与哪个连通块有关,再在对应的Chart中调用对应的函数。
EdgeLength、EdgePathId、EdgePrice、EdgeTrans、EdgeUnpleasent等类的构造,沿用了第10次作业中Edges类的构造思想,主要是为了与hashmap结合,表示“一条边中fromnode+tonode+对应信息(出现次数、最短距离、最低票价……)”这样的关系。
在第11次作业中,我区别于第10次作业的地方,主要在于将彼此不连通的连通块们分别存储成不同的Chart,并在此基础上修改了原本的“判断是否相连”“计算最短距离”功能,进一步完成了“计算连通块数量”“计算最少换乘”“计算最低票价”“计算最小不满意度”功能。
每当需要新增一个path,就调用TheRailwaySystem类中的addPath函数。在判断新增的path的合法性、是否重复之后,需要将这个新增的path加入到differnode、differpath、differpathid中去。其中,在使用renewDiffers时,signal==1表示增加path,signal==-1表示减少path。
之后,我需要判断,新增的path,是需要单独构成一个连通图,还是加入到一个已经存在的连通图之中?如果是单独构成一个连通图,那么说明,path不与任何已经存在的连通图相连;如果是加入到一个已经存在的连通图,说明path与至少一个任何已经存在的连通图相连。因此,在“加入到一个已经存在的连通图”的情况下,需要讨论,path的加入,是否会造成本不连通的几个连通图彼此连通了。如果是,需要合并这些图,具体方法是:将连通图B读出,将B从连通图的队列中删除,再将B中所有路径与路径对应路径编号放入A中,实现连通图A与连通图B的合并。
而在将path加入具体的一个连通图chart时,需要:
“清空保存在finalLength、finalTrans、finalPrice、finalUnpleasent中的以往dijkstra计算结果”
“更新indextopath、pathtoindex、indextoid、idtoindex、differnode、nodequeue”
“为graphLength、graphTrans、graphPrice、graphUnpleasent增加对应格式的新‘边’”
“为graphTrans、graphPrice、graphUnpleasent增加该path中所有点与他们‘同点不同路径’的点的‘距离’权值关系”
“为graphLength、graphTrans、graphPrice、graphUnpleasent增加该path中所有相邻点的对应关系”
“更新nodetopathid的对应关系(同一node,可以存在于哪些path中,存储对应的pathid)”
每次删除一个path,在判断path合法性与是否存在的基础上,需要找到path所在chart,读出保存,将这个chart从连通图的队列中删除,再将chart中除了path的其他路径一条条加回去,除了对应pathid是保存在chart中的pathid,加回去是需要考虑的部分与addPath大体相同。
Chart类中不用实现removePath的功能,因为removePath时会直接删除对应chart。
在TheRailwaySystem中“计算连通块数量”,直接返回连通块队列的大小。
在TheRailwaySystem中“判断是否相连”“计算最短距离”“计算最少换乘”“计算最低票价”“计算最小不满意度”时,都要先对起始点、终止点进行讨论,在两点都存在,且存在于同一个连通块中的情况下,转到Chart类中调用同名的函数进行计算(“判断是否相连”时,不用进入Chart,可以直接返回true,因为处于同一连通块的两点必定相连)。在Chart类中,为“计算最短距离”“计算最少换乘”“计算最低票价”“计算最小不满意度”,分别构造了4组“储存结构*2 + 函数*2”。
储存结构*2,为保存对应连通图的“graphxxxxx”和保存dijkstra结果的“finalxxxxx”。
函数*2,是进行dijkstra运算的函数“dijkstraxxxxx”和为查找结果、dijkstra运算做准备、调用“dijkstraxxxxx”并返回最终结果的“getxxxxxxxxxx”。
(2)复杂度与依赖度分析
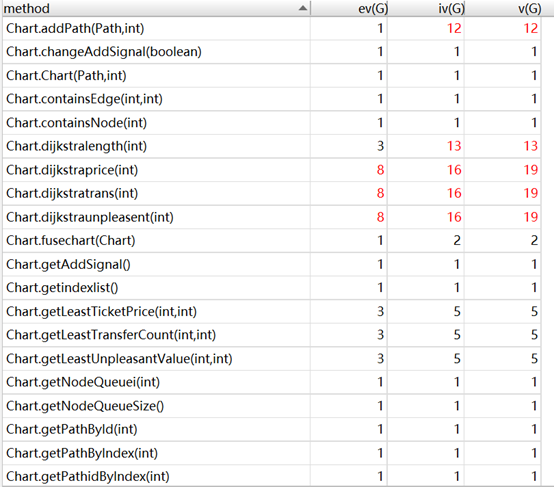
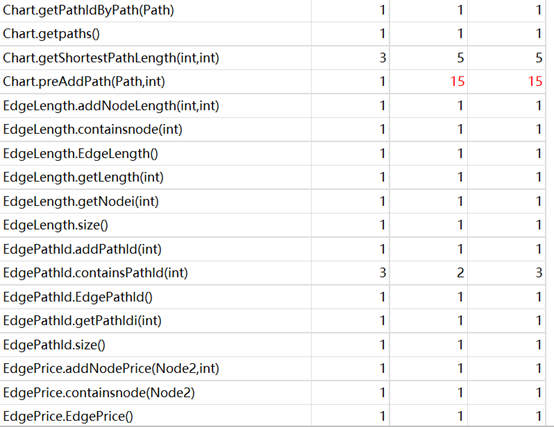
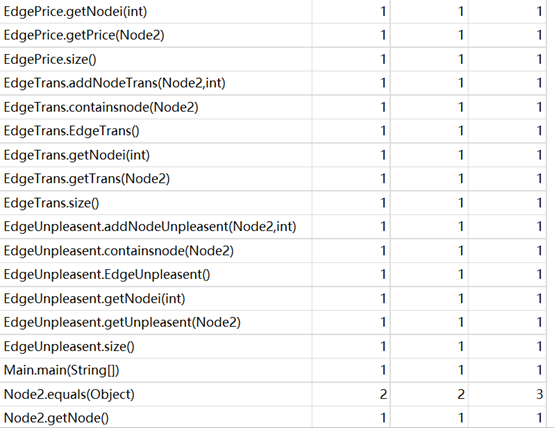

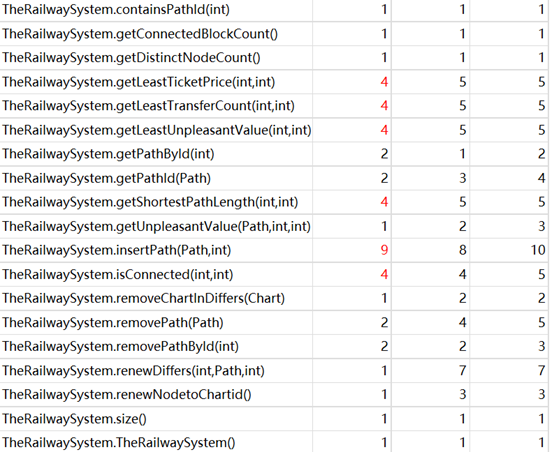

这一次作业,时间复杂度较高的方法主要在于4个“dijkstraxxxxx”。准确的是,是因为我使用了拆点法,但又没有辅助以菊花点这样的方法,导致复杂度爆炸。实践证明,其实,单纯的二维数组+Floyd,反而能满足强测的时间要求。
五、按照作业分析代码实现的bug和修复情况
1、第9次作业
我错了,我真的错了,我从一开始就不应该打开这个软件。我原以为这次作业很是简单,很快就写出了第一版。然后,在截止前2天的一个深夜,我看到年级群里助教老师的点评“无脑arraylist小心爆炸”,胆战心惊、苦思冥想、恍然大悟(自以为,其实并不——NO!!!)、痛定思痛之后,我,在一个深夜,在幽幽的月光下,把我可爱的arraylist们,全部改成了hashmap。我本以为这样写的我一定能让我的程序跑的飞快,然而,并不是,我的CPU被卡爆了,tle使我疯狂使我爆炸嘤嘤嘤。
在将保存Path的结构改成arraylist为主,hashmap为辅的形式后,我成功修复了一大堆的tle error。
2、第10次作业
老天保佑,这次作业没出什么bug。
3、第11次作业
在完成这次作业时,我一开始就确定了“连通块分开储存”+“深度优先遍历”的解题思路。然而,在写代码的过程中,我发现“深度优先遍历”的方法复杂度实在过高,不宜使用。在对年纪讨论群进行了长达48小时的窥屏后,我选择了“拆点法”(住手啊你的第11次作业还是个孩子,他不想爆炸啊)。然鹅,二把刀的我没有很好地get大佬们的“拆点 + 菊花点”的设计思想,单纯使用“拆点法”的我,很“顺利”地炸掉了一大半的强测点(一口老血喷出来,这样说不定还不如我一开始的深不优先遍历呢)。
在同学的建议与指点下,我换成了“二维数组”+“Floyd”的方法,成功修复了所有tle error的错误点。(对不起我先去墙角哭一会(╥﹏╥))
六、阐述对规格撰写和理解上的心得体会
经过这一段时间对JML规格的阅读以及上次上机时自己真正尝试写JML规格,我深深感受到了JML语言的重要性。只有使用JML语言,在进行程序编写,特别是不同人组队完成一个大型程序的编写时,才可以在最大程度上保证不同人完成在代码可以融合在一起,而不会产生各种各样奇妙的bug。
在完成这3次作业时,我绝大部分时间都用在搭建储存结构框架、选择算法、写代码、debug的过程中了,主要是“在tle error的边缘疯狂试探”。希望我能进一步地学习JML规格语言。
