并发编程(五)final关键字
final可以修饰变量,方法和类,也就是final使用范围基本涵盖了java每个地方,我们先依次学习final的基础用法,然后再研究final关键字在多线程中的语义。
一、变量
变量,可以分为成员变量以及方法局部变量,我们再依次进行学习。
1.1 成员变量
成员变量可以分为类变量(static修饰的变量)以及实例变量,这两种类型的变量赋初值的时机是不同的,类变量可以在声明变量的时候直接赋初值或者在静态代码块中给类变量赋初值,实例变量可以在声明变量的时候给实例变量赋初值,在非静态初始化块中以及构造器中赋初值。
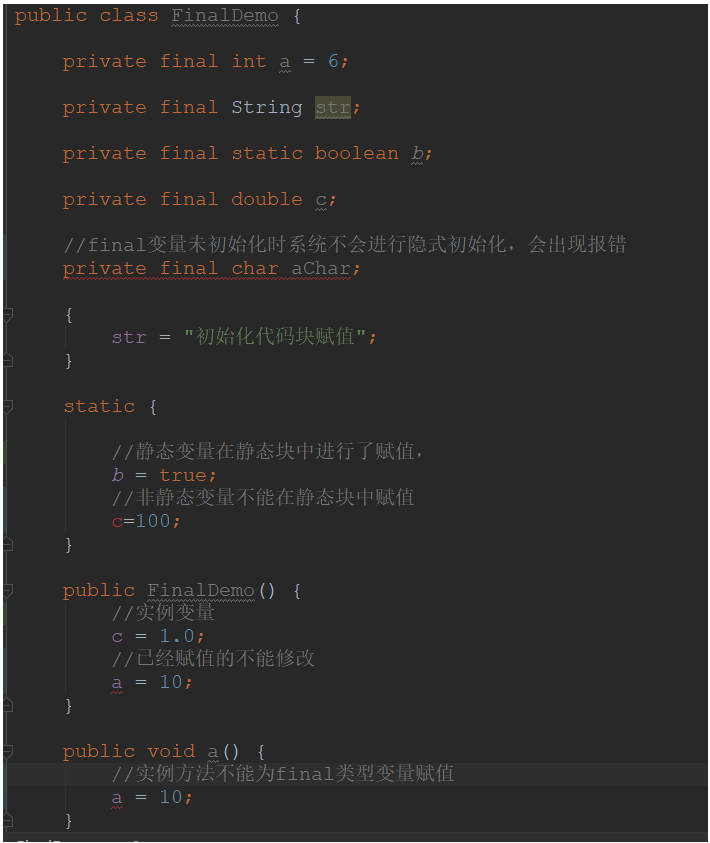
这里面要注意,在final变量未初始化时系统不会进行隐式初始化,会出现报错。
归纳总结:
-
类变量:必须要在静态初始化块中指定初始值或者声明该类变量时指定初始值,而且只能在这两个地方之一进行指定;
-
实例变量:必要要在非静态初始化块,声明该实例变量或者在构造器中指定初始值,而且只能在这三个地方进行指定。
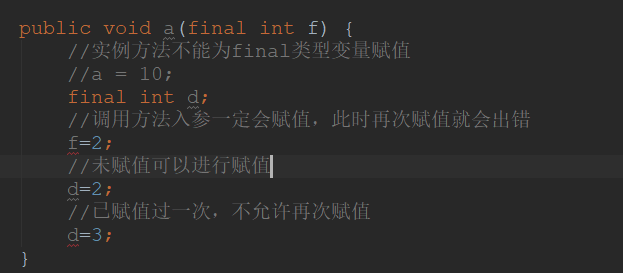
1.2 局部变量
对于局部变量使用final,理解就更简单,局部变量的仅有一次赋值,一旦赋值之后再次赋值就会出错:
1.3 基本数据类型 VS 引用数据类型
上面讨论的基本都是基本数据类型,基本数据类型一旦赋值之后,就不允许修改,那引用类型呢?

public class FinalDemo1 { //在声明final实例成员变量时进行赋值 private final static Person person = new Person(24, 170); public static void main(String[] args) { //对final引用数据类型person进行更改 person.age = 22; Person p = new Person(50, 160); //对引用类型变量直接修改会报错 //person = p; System.out.println(person.toString()); } static class Person { private int age; private int height; public Person(int age, int height) { this.age = age; this.height = height; } @Override public String toString() { return "Person{" + "age=" + age + ", height=" + height + '}'; } } }
上面的例子可以看出,我们可以对引用数据类型的属性进行更改,但是不能直接对引用类型的变量进行修改,
final只保证这个引用类型变量所引用的地址不会发生改变
二、方法
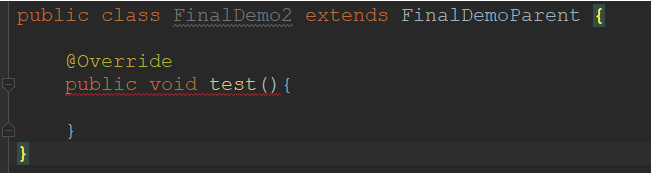
当一个方法被final关键字修饰时,说明此方法不能被子类重写
public class FinalDemoParent { //final修饰的方法不能被子类重载 public final void test() { } }
子类不能重写该方法
在Object中,getClass()方法就是final的,我们就不能重写该方法,但是hashCode()方法就不是被final所修饰的,我们就可以重写hashCode()方法。
当一个类被final修饰时,表示该类是不能被子类继承的,当我们想避免由于子类继承重写父类的方法和改变父类属性,带来一定的安全隐患时,就可以使用final修饰。
扩展思考,为什么String类为什么是final的?先看下源码

final修饰的String,代表了String的不可继承性,final修饰的char[]代表了被存储的数据不可更改性。但是:我们知道引用类型的不可变仅仅是引用地址不可变,不代表了数组本身不会变,这个时候,起作用的还有private,正是因为两者保证了String的不可变性。
那么为什么保证String不可变呢,因为只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么字符串池将不能实现,因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
因为字符串是不可变的,所以是多线程安全的
因为字符串是不可变的,所以在它创建的时候HashCode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
对于final域,编译器和处理器要遵守两个重排序规则。
- 在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
- 初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
我们通过下面的例子来看:
public class FinalDemo3 {
private int i;// 普通变量
private final int j;// final变量
private static FinalDemo3 obj;
public FinalDemo3() { // 构造函数
i = 1; // 写普通域
j = 2;// 写final域
}
public static void writer() {// 写线程A执行
obj = new FinalDemo3();
}
public static void reader() {// 读线程B执行
FinalDemo3 object = obj; // 读对象引用
int a = object.i; // 读普通域
int b = object.j; // 读final域
}
}
这里假设一个线程A执行writer()方法,随后另一个线程B执行reader()方法。下面我们通过这两个线程的交互来说明这两个规则。
4.1 写final域的重排序规则
写final域的重排序规则禁止对final域的写重排序到构造函数之外,这个规则的实现主要包含了两个方面:
-
JMM禁止编译器把final域的写重排序到构造函数之外;
-
编译器会在final域写之后,构造函数return之前,插入一个storestore屏障。这个屏障可以禁止处理器把final域的写重排序到构造函数之外。
我们分析writer()方法,writer方法虽然只有一行代码,但其实是做了两件事情的:
-
构造了一个FinalDemo3对象;
-
把这个对象赋值给成员变量obj。
我们先假设线程B读对象引用与读对象的成员域之间没有重排序,那以下是一种可能的执行时序:
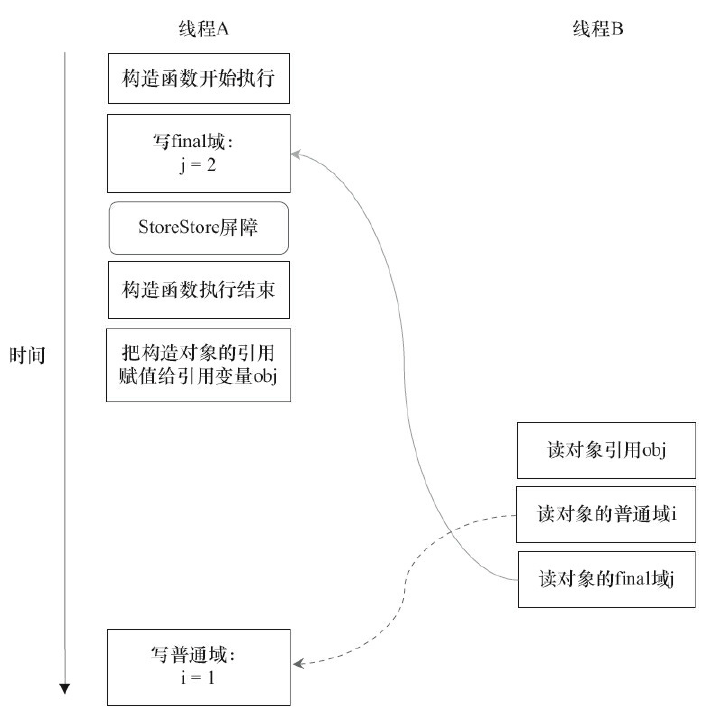
这里可以看出, 写普通域的操作被编译器重排序到了构造函数之外,读线程B错误地读取了普通变量i初始化之前的值。而写final域的操作,被写final域的重排序规则“限定”在了构造函数之内,读线程B正确地读取了final变量初始化之后的值。
写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域不具有这个保障。
要得到这个效果,还需要一个保证:在构造函数内部,不能让这个被构造对象的引用为其他线程所见,也就是对象引用不能在构造函数中“逸出”。
4.2 读final域的重排序规则
读final域的重排序规则是,在一个线程中,初次读对象引用与初次读该对象包含的final域,JMM禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读final域操作的前面插入一个LoadLoad屏障。
初次读对象引用与初次读该对象包含的final域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,也不会重排序这两个操作。但有少数处理器允许对存在间接依赖关系的操作做重排序(比如alpha处理器),这个规则就是专门用来针对这种处理器的。
reader()方法包含3个操作。
-
初次读引用变量obj。
-
初次读引用变量obj指向对象的普通域j。
-
初次读引用变量obj指向对象的final域i。
假设写线程A没有发生任何重排序,同时程序在不遵守间接依赖的处理器上执行,那以下一种可能的执行时序:
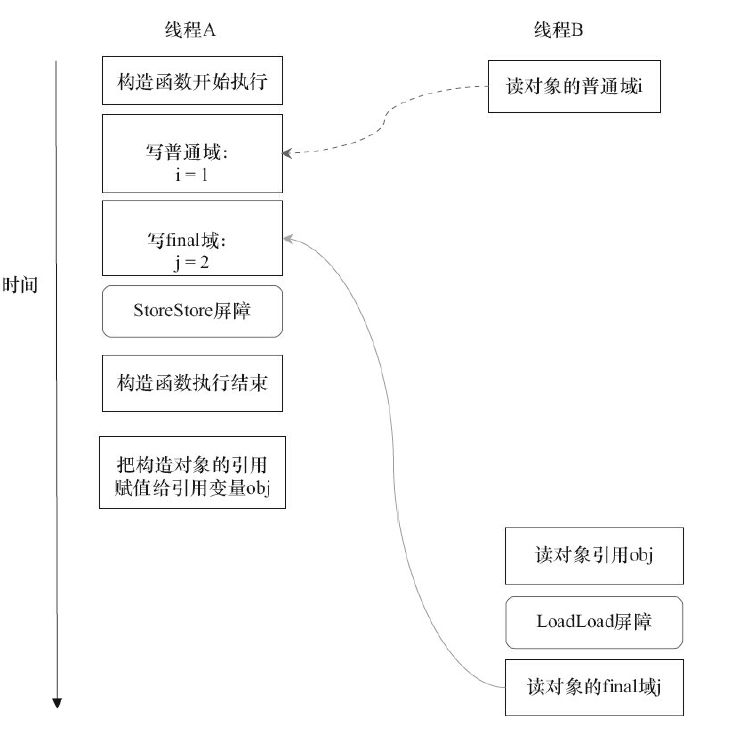
读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程A写入,这是一个错误的读取操作。而读final域的重排序规则会把读对象final域的操作“限定”在读对象引用之后,此时该final域已经被A线程初始化过了,这是一个正确的读取操作。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
4.3 final域为引用类型
上面看到的final域是基础数据类型,如果final域是引用类型,将会有什么效果?请看下列示例代码:
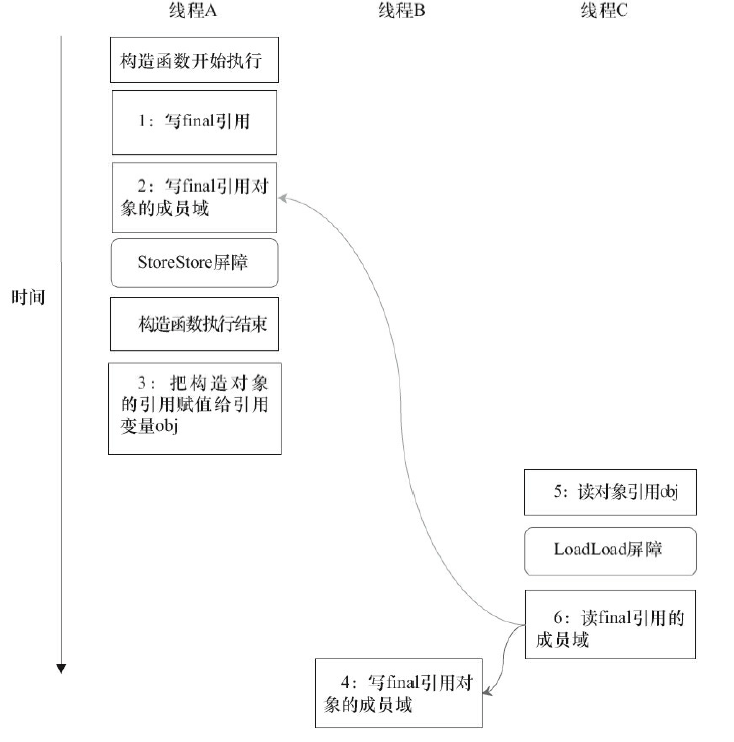
public class FinalDemo4 { final int[] intArray; // final是引用类型 static FinalDemo4 obj; public FinalDemo4() { // 构造函数 intArray = new int[1]; // 1 intArray[0] = 1; // 2 } public static void writerOne() { // 写线程A执行 obj = new FinalDemo4(); // 3 } public static void writerTwo() { // 写线程B执行 obj.intArray[0] = 2; // 4 } public static void reader() { // 读线程C执行 if (obj != null) { // 5 int temp1 = obj.intArray[0]; // 6 } } }
final域为一个引用类型,它引用一个int型的数组对象。对于引用类型,写final域的重排序规则对编译器和处理器增加了如下约束:在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
对上面的示例程序,假设首先线程A执行writerOne()方法,执行完后线程B执行writerTwo()方法,执行完后线程C执行reader()方法。那下面就可能是一种时序:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?