

网卡收发数据包的过程
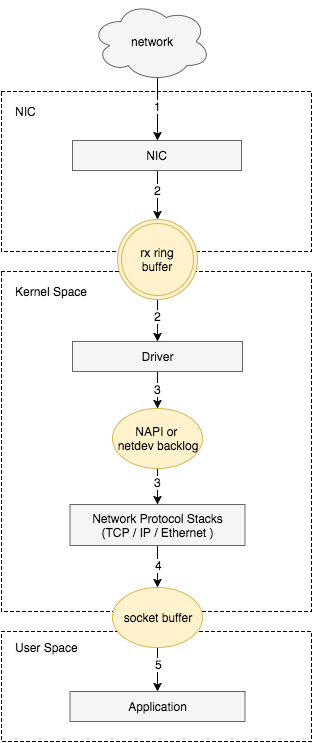
一、接收数据包的流程
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
- 网卡收到数据包。
- 将数据包从网卡硬件缓存转移到服务器内存中。
- 通知内核处理。
- 经过TCP/IP协议逐层处理。
- 应用程序通过
read()从socket buffer读取数据。
将网卡收到的数据包转移到主机内存(NIC与驱动交互)
NIC在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是rx ring buffer。它是由NIC和驱动程序共享的一片区域,事实上,rx ring buffer存储的并不是实际的packet数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
- 驱动在内存中分配一片缓冲区用来接收数据包,叫做
sk_buffer; - 将上述缓冲区的地址和大小(即接收描述符),加入到
rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址; - 驱动通知网卡有一个新的描述符;
- 网卡从
rx ring buffer中取出描述符,从而获知缓冲区的地址和大小; - 网卡收到新的数据包;
- 网卡将新数据包通过DMA直接写到
sk_buffer中。
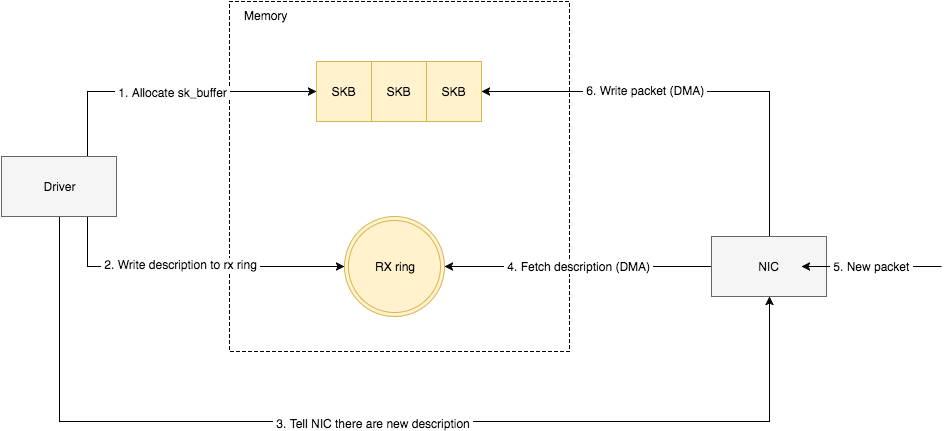
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC接收到的数据包无法及时写到sk_buffer,就会产生堆积,当NIC内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为rx_fifo_errors,在/proc/net/dev中体现为fifo字段增长,在ifconfig中体现为overruns指标增长。
通知系统内核处理(驱动与Linux内核交互)
这个时候,数据包已经被转移到了sk_buffer中。前文提到,这是驱动程序在内存中分配的一片缓冲区,并且是通过DMA写入的,这种方式不依赖CPU直接将数据写到了内存中,意味着对内核来说,其实并不知道已经有新数据到了内存中。那么如何让内核知道有新数据进来了呢?答案就是中断,通过中断告诉内核有新数据进来了,并需要进行后续处理。
提到中断,就涉及到硬中断和软中断,首先需要简单了解一下它们的区别:
- 硬中断: 由硬件自己生成,具有随机性,硬中断被CPU接收后,触发执行中断处理程序。中断处理程序只会处理关键性的、短时间内可以处理完的工作,剩余耗时较长工作,会放到中断之后,由软中断来完成。硬中断也被称为上半部分。
- 软中断: 由硬中断对应的中断处理程序生成,往往是预先在代码里实现好的,不具有随机性。(除此之外,也有应用程序触发的软中断,与本文讨论的网卡收包无关。)也被称为下半部分。
当NIC把数据包通过DMA复制到内核缓冲区sk_buffer后,NIC立即发起一个硬件中断。CPU接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费sk_buffer中的数据,交给内核协议栈处理。
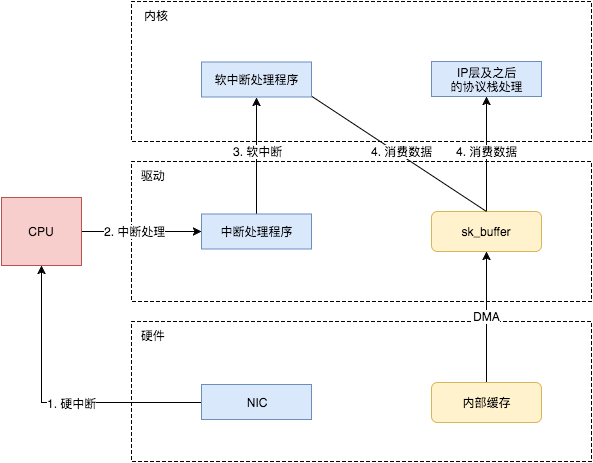
通过中断,能够快速及时地响应网卡数据请求,但如果数据量大,那么会产生大量中断请求,CPU大部分时间都忙于处理中断,效率很低。为了解决这个问题,现在的内核及驱动都采用一种叫NAPI(new API)的方式进行数据处理,其原理可以简单理解为 中断+轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
二、softnet_stat
内核会为每个CPU Core都实例化一个softnet_data对象,这个对象中的input_pkt_queue用于管理接收的数据包。假如所有的中断都由一个CPU Core来处理的话,那么所有数据包只能经由这个CPU的input_pkt_queue,如果接收的数据包数量非常大,超过中断处理速度,那么input_pkt_queue中的数据包就会堆积,直至超过netdev_max_backlog,引起丢包。这部分丢包可以在cat /proc/net/softnet_stat的输出结果中进行确认:

其中每行代表一个CPU,
- 第一列是中断处理程序接收的帧数
- 第二列是由于超过
netdev_max_backlog而丢弃的帧数。 - 第三列则是在
net_rx_action函数中处理数据包超过netdev_budge指定数量或运行时间超过2个时间片的次数。在检查线上服务器之后,发现第一行CPU。硬中断的中断号及统计数据可以在/proc/interrupts中看到,对于多队列网卡,当系统启动并加载NIC设备驱动程序模块时,每个RXTX队列会被初始化分配一个唯一的中断向量号,它通知中断处理程序该中断来自哪个NIC队列。在默认情况下,所有队列的硬中断都由CPU 0处理,因此对应的软中断逻辑也会在CPU 0上处理,在服务器 TOP 的输出中,也可以观察到 %si 软中断部分,CPU 0的占比比其他core高出一截。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2022-11-16 TEMPORARY_DISABLE_PATH_RESTRICTIONS was a temporary migration method, and is now obsolete.