

内存管理
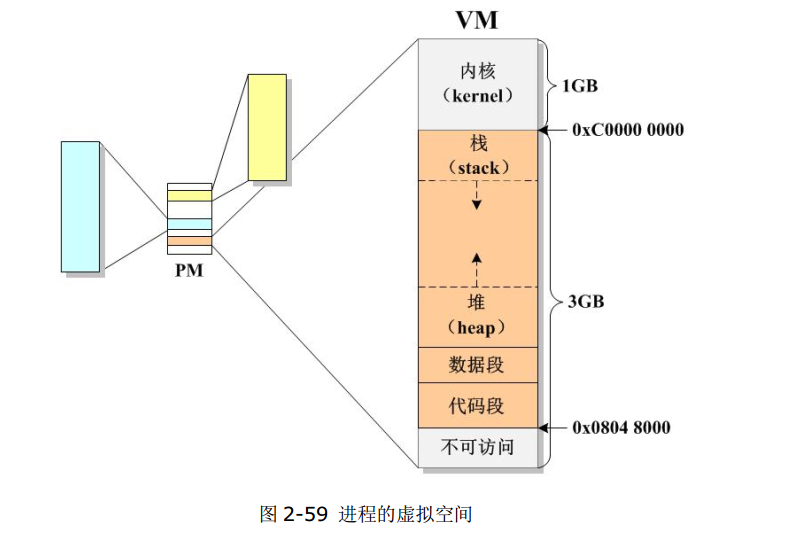
1、栈内存
-
被称为“栈”是因为进程在使用这块内存的时候是严格按照“后进先出”的原则来操作的,而这种后进先出的逻辑,就被称为栈。
-
随着进程的运行而不断发生变化:一旦有新的函数被调用,就会立即在栈顶分配一帧内存,专门用于存放该函数内定义的局部变量(包括所有的形参),当一个函数执行完毕返回之后,他所占用的那帧内存将被立即释放。
-
全称为“运行时栈”,栈主要就是用来存储进程执行过程中所产生的局部变量的,当然为了可以实现函数的嵌套调用和返回,栈还必须包含函数切换时当下的代码地址和相关寄存器的值,这个过程被称为“保存现场”,等被调函数执行结束之后,再“恢复现场”。因此,如果进程嵌套调用了很多函数,就会导致栈不断增长,但是栈的大小又是有一个最大限度的,这个限度一般是8MB,超过了这个最大值将会产生所谓的“栈溢出”导致程序崩溃,所以我们在进程中不宜嵌套调用太深的函数,也不要定义太多太大的局部变量。
2、堆内存
- 堆内存(以下简称堆〉是一块自由内存,原因是在这个区域定义和释放变量完全由你来决定,即所谓的自由区。堆跟栈的最大区别在于堆是不设大小限制的,最大值取决于系统的物理内存。
- 堆的全称是“运行时堆(run-time heap)”,跟栈一样,会随着进程的运行而不断地增大或缩小,由于对堆的操作非常重要,
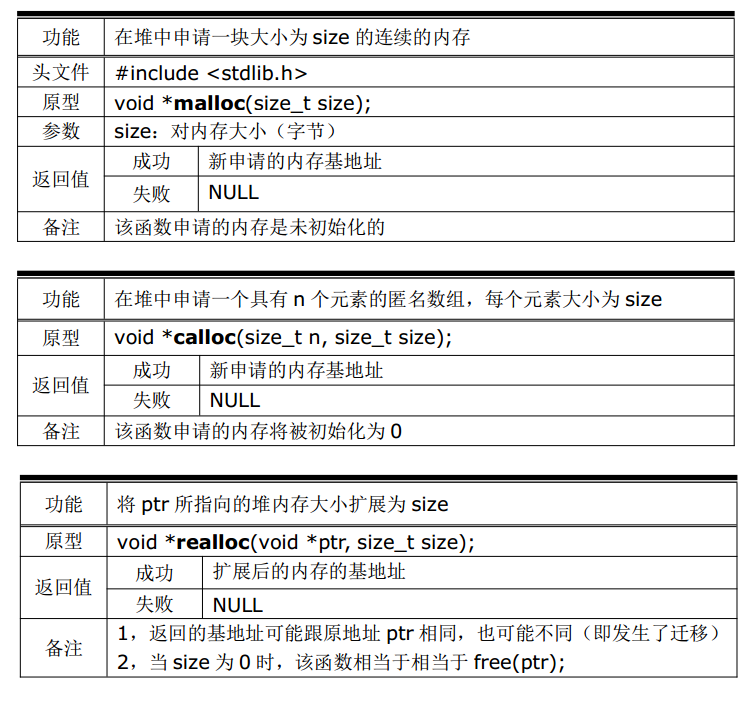
堆内存操作API的介绍如下:

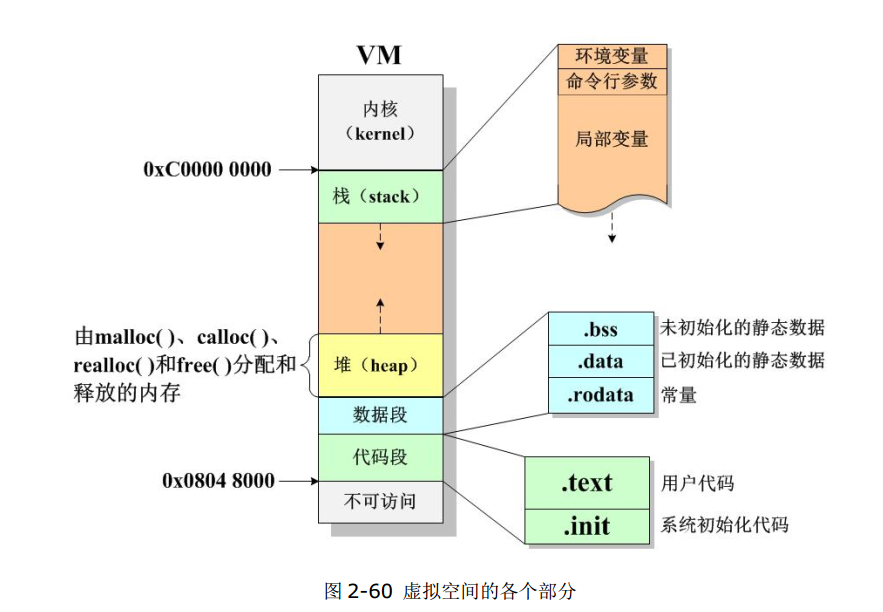
3、数据段
数据段实际上分为三个部分:
- .bss段:专门用来存放未初始化的静态数据,它们都将被初始化为0。
- .data段:专门存放已经初始化的静态数据,这么初始值从程序文件中拷贝而来。
- .rodata段:存放只读数据,即常量,比如进程中所有的字符串、字符常量、整型浮点型常量等。
4、代码段
代码段实际上也至少分为两部分:.text段和.init段。
- .text 段用来存放用户程序代码,也就是包括main函数在内的所有用户自定义函数。
- .init 段则用来存储系统给每一个可执行程序自动添加的“初始化”代码,这部分代码功能包括环境变量的准备、命令行参数的组织和传递等,并且这部分数据被放置在了栈底。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)