嵌入式工程师经典面试题
1、 用预处理指令#define 声明一个常数,用以表明1年中有多少秒(忽略闰年问题)
#define SECONDS_PER_YEAR (60 * 60 * 24 * 365)UL
注意:(1)#define 语法的基本知识(例如:不能以分号结束,括号的使用,等等)
(2) 意识到这个表达式将使一个16位机的整型数溢出-因此要用到长整型符号L,告诉编译器这个常数是的长整型数.
(3) 如果你在你的表达式中用到UL(表示无符号长整型),那么你有了一个好的起点。记住,第一印象很重要。
2 . 写一个"标准"宏MIN ,这个宏输入两个参数并返回较小的一个。
#define MIN(A,B) ((A) <= (B) ? (A) : (B))
注意:(1)标识#define在宏中应用的基本知识。这是很重要的。因为在 嵌入(inline)操作符 变为标准C的一部分之前,宏是方便产生嵌入代码的唯一方法,对于嵌入式系统来说,为了能达到要求的性能,嵌入代码经常是必须的方法。
(2) 三重条件操作符的知识。这个操作符存在C语言中的原因是它使得编译器能产生比if-then-else更优的代码,了解这个用法是很重要的。
(3) 懂得在宏中小心地把参数用括号括起来
(4) 我也用这个问题开始讨论宏的副作用,例如:当你写下面的代码时会发生什么事?
least = MIN(*p++, b);
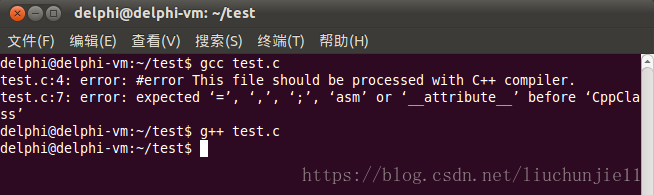
3. 预处理器标识#error的目的是什么?
#error 用于生成一个编译错误消息。
用法:#error message //message不需要双引号包围
示例:
#include <stdio.h>
#ifndef __cplusplus
#error this file should be processed with C++ Compiler
#endif
class CppClass
{
private:
int m_value;
public:
CppClass()
{
}
~CppClass()
{
}
};
int main()
{
return 0;
}
输出:
4、嵌入式系统中经常要用到无限循环,你怎么样用C编写死循环呢?
方法一:while循环
while(1);
方法二:for循环
for(;;);
方法三:goto语句
Loop:
....
goto Loop;
5、用变量a给出下面的定义
(1)一个整型数; // int a;
(2)一个指向整型数的指针; // int * a;
(3)一个指向指针的指针,它指向的指针指向一个整型数 // int ** a;
(4)一个有10个整型数的数组 // int a[10];
(5)一个有10个指针的数组,该指针是指向一个整型数的 // int *a[10];
(6)一个指向有10个整型数数组的指针 // int (*a)[10];
(7)一个指向函数的指针,该函数有一个整型参数并返回一个整型数。 // int (*a)(int );
(8)一个有10个指针的数组,该指针指向一个函数,该函数有一个整型参数并返回一个整型数 int (*a[10])(int);
int p; //这是一个普通的整型变量 int *p; //首先从P 处开始,先与*结合,所以说明P 是一个指针,然后再与int 结合,说明指针所指向的内容的类型为int 型.
//所以P是一个返回整型数据的指针 int p[3]; //首先从P 处开始,先与[]结合,说明P 是一个数组,然后与int 结合,说明数组里的元素是整型的,所以P 是一个由整型数据组成的数组 int *p[3]; //首先从P 处开始,先与[]结合,因为其优先级比*高,所以P 是一个数组,然后再与*结合,说明数组里的元素是指针类型,然后再与int 结合,
//说明指针所指向的内容的类型是整型的,所以P 是一个由返回整型数据的指针所组成的数组 int (*p)[3]; //首先从P 处开始,先与*结合,说明P 是一个指针然后再与[]结合(与"()"这步可以忽略,只是为了改变优先级),
//说明指针所指向的内容是一个数组,然后再与int 结合,说明数组里的元素是整型的.所以P 是一个指向由整型数据组成的数组的指针
int **p; //首先从P 开始,先与*结合,说是P 是一个指针,然后再与*结合,说明指针所指向的元素是指针,然后再与int 结合,
//说明该指针所指向的元素是整型数据.由于二级指针以及更高级的指针极少用在复杂的类型中,所以后面更复杂的类型我们就不考虑多级指针了,
//最多只考虑一级指针. int p(int); //从P 处起,先与()结合,说明P 是一个函数,然后进入()里分析,说明该函数有一个整型变量的参数,然后再与外面的int 结合,
//说明函数的返回值是一个整型数据。 Int (*p)(int); //从P 处开始,先与指针结合,说明P 是一个指针,然后与()结合,说明指针指向的是一个函数,然后再与()里的int 结合,
//说明函数有一个int 型的参数,再与最外层的int 结合,说明函数的返回类型是整型,所以P 是一个指向有一个整型参数且返回类型为整型的函数的指针 int *(*p(int))[3]; //可以先跳过,不看这个类型,过于复杂从P 开始,先与()结合,说明P 是一个函数,然后进入()里面,与int 结合,说明函数有一个整型变量参数,
//然后再与外面的*结合,说明函数返回的是一个指针,,然后到最外面一层,先与[]结合,说明返回的指针指向的是一个数组,然后再与*结合,
//说明数组里的元素是指针,然后再与int 结合,说明指针指向的内容是整型数据.所以P 是一个参数为一个整数据且返回一个指向由整型
//指针变量组成的数组的指针变量的函数.
6、关键字static的作用是什么?
在C语言中,关键字static有三个明显的作用:
(1)在修饰变量的时候,static 修饰的静态局部变量只执行初始化一次,而且延长了局部变量的生命周期,直到程序运行结束以后才释放。
(2) 当static修饰全局变量和函数时,该函数和全局变量只能在本文件中使用。
(3)static修饰变量时,如果没有对变量进行初始化,那么编译器回自动对该变量初始化0.
在C++中:
(1)静态数据成员在同一个类的实例之间可以共享,如果不想让它共享,可以将它设为私有的或保护的。
(2)静态成员函数可以通过类名和对象名来调用,
(3)静态成员函数可以直接访问该类的静态数据和函数成员,而访问非静态成员,必须通过对象名。
(4)当static修饰全局变量和函数时,该函数和全局变量只能在本文件中使用。
(5)被static修饰的成员函数是不分配空间的。
(6)被static修饰的数据成员在类外初始化,通过类名来访问。
(7)被static修饰的成员函数的调用(类名::函数名()).
(8)静态成员函数没有this指针,因为它不属于任何一个具体的对象。
(9)静态成员函数不能被声明为虚函数或volatile。
7、const的用法。
(1)可以定义const常量。
(2)Const可以修饰函数的参数和返回值,甚至定义体。被const修饰的东西都受到强制保护。
(3)Const修饰成员函数时,用于成员函数前面,则返回值不能作为左值。用在后面,则该成员函数的数据成员不能改变。
(4)Const修饰数据成员时,必须使用冒号语法。
在C程序中,const主要有定义变量、修饰函数参数、修饰函数返回值。
在C++程序中,还可以修饰函数的定义体,定义类中成员函数为恒态函数,既不改变类中的数据成员。
const int a; //常整型数
int const a; //常整型数
const int *a; //一个指向常整型数的指针(整型数是不可修改的,但指针可以)
int * const a; //一个指向整型数的常指针(指针指向的整型数可修改的,指针是
//不可修改的))
int const * a const; //一个指向常整型数的长指针(指针指向的整型数和指针都不可修改)
8、关键字Volatile有什么含义?并给出三个不同的例子?
volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,都会直接从变量地址中读取数据。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。下面举例说明。在DSP开发中,经常需要等待某个事件的触发,所以经常会写出这样的程序:
short flag;
void test()
{
do1();
while(flag==0);
do2();
}
这段程序等待内存变量flag的值变为1之后才运行do2()。变量flag的值由别的程序更改,这个程序可能是某个硬件中断服务程序。例如:如果某个按钮
按下的话,就会对DSP产生中断,在按键中断程序中修改flag为1,这样上面的程序就能够得以继续运行。但是,编译器并不知道flag的值会被别的程序修
改,因此在它进行优化的时候,可能会把flag的值先读入某个寄存器,然后等待那个寄存器变为1。如果不幸进行了这样的优化,那么while循环就变成了死
循环,因为寄存器的内容不可能被中断服务程序修改。为了让程序每次都读取真正flag变量的值,就需要定义为如下形式:
volatile short flag;
需要注意的是,没有volatile也可能能正常运行,但是可能修改了编译器的优化级别之后就又不能正常运行了。因此经常会出现debug版本正常,但是
\release版本却不能正常的问题。所以为了安全起见,只要是等待别的程序修改某个变量的话,就加上volatile关键字。
下面是volatile变量的几个例子:
1) 并行设备的硬件寄存器(如:状态寄存器)
2) 一个中断服务子程序中会访问到的非自动变量(Non-automatic variables)
3) 多线程应用中被几个任务共享的变量
1) 一个参数既可以是const还可以是volatile吗?解释为什么。
2) 一个指针可以是volatile 吗?解释为什么。
3) 下面的函数有什么错误:
int square(volatile int *ptr)
{
return *ptr * *ptr;
}
下面是答案:
1) 是的。一个例子是只读的状态寄存器。它是volatile因为它可能被意想不到地改变。它是const因为程序不应该试图去修改它。
2) 是的。尽管这并不很常见。一个例子是当一个中服务子程序修该一个指向一个buffer的指针时。
3) 这段代码有点变态。这段代码的目的是用来返指针*ptr指向值的平方,但是,由于*ptr指向一个volatile型参数,编译器将产生类似下面的代码:
int square(volatile int *ptr)
{
int a,b;
a = *ptr;
b = *ptr;
return a * b;
}
由于*ptr的值可能被意想不到地该变,因此a和b可能是不同的。结果,这段代码可能返不是你所期望的平方值!正确的代码如下:
long square(volatile int *ptr)
{
int a;
a = *ptr;
return a * a;
}
9、嵌入式系统总是要用户对变量或寄存器进行位操作。给定一个整型变量a,写两段代码,第一个设置a的bit 3,第二个清除a 的bit 3。在以上两个操作中,要保持其它位不变。
#define BIT3 (0x1 << 3)
static int a;
void set_bit3(void)
{
a |= BIT3;
}
void clear_bit3(void)
{
a &= ~BIT3;
}
10. 嵌入式系统经常具有要求程序员去访问某特定的内存位置的特点。在某工程中,要求设置一绝对地址为0x67a9的整型变量的值为0xaa66。编译器是一个纯粹的ANSI编译器。写代码去完成这一任务。
这一问题测试你是否知道为了访问一绝对地址把一个整型数强制转换(typecast)为一指针是合法的。这一问题的实现方式随着个人风格不同而不同。典型的类似代码如下:
int *ptr;
ptr = (int *)0x67a9;
*ptr = 0xaa55;
一个较晦涩的方法是:
*(int * const)(0x67a9) = 0xaa55;
11. 中断是嵌入式系统中重要的组成部分,这导致了很多编译开发商提供一种扩展—让标准C支持中断。具代表事实是,产生了一个新的关键字 __interrupt。下面的代码就使用了__interrupt关键字去定义了一个中断服务子程序(ISR),请评论一下这段代码的。
__interrupt double compute_area (double radius)
{
double area = PI * radius * radius;
printf("\nArea = %f", area);
return area;
}
答:1) ISR 不能返回一个值。如果你不懂这个,那么你不会被雇用的。
2) ISR 不能传递参数。如果你没有看到这一点,你被雇用的机会等同第一项。
3) 在许多的处理器/编译器中,浮点一般都是不可重入的。有些处理器/编译器需要让额处的寄存器入栈,有些处理器/编译器就是不允许在ISR中做浮点运算。此外,ISR应该是短而有效率的,在ISR中做浮点运算是不明智的。
4) 与第三点一脉相承,printf()经常有重入和性能上的问题。如果你丢掉了第三和第四点,我不会太为难你的。不用说,如果你能得到后两点,那么你的被雇用前景越来越光明了。
12、从键盘输入两个正整数 a 和 b,求其最大公约数和最小公倍数。
算法思想
利用格式输入语句将输入的两个数分别赋给 a 和 b,然后判断 a 和 b 的关系,如果 a 小于 b,则利用中间变量 t 将其互换。再利用辗转相除法求出最大公约数,进而求出最小公倍数。最后用格式输出语句将其输出。
辗转相除法, 又名欧几里德算法(Euclidean algorithm),是求最大公约数的一种方法。它的具体做法是:用较大数除以较小数,再用出现的余数(第一余数)去除除数,再用出现的余数(第二余数)去除第一余数,如此反复,直到最后余数是0为止。如果是求两个数的最大公约数,那么最后的除数就是这两个数的最大公约数。
#include <stdio.h>
int main()
{
int a,b,c,m,t;
printf("请输入两个数:\n");
scanf("%d%d",&a,&b);
if(a<b)
{
t=a;
a=b;
b=t;
}
m=a*b;
c=a%b;
while(c!=0)
{
a=b;
b=c;
c=a%b;
}
printf("最大公约数是:\n%d\n",b);
printf("最小公倍数是:\n%d\n",m/b);
}
调试运行结果
当输入的两个数为 15 和 65 时,打印出的结果如下所示
请输入两个数:
15 65
最大公约数是:
5
最小公倍数是:
195
总结
实例中用到了辗转相除法来求最大公约数。在求最小公倍数时要清楚最大公约数和最小公倍数的关系,即两数相乘的积除以这两个数的最大公约数就是最小公倍数。
13、程序实现判断某一年是否是闰年?
算法思想:闰年的判断条件: 年份能被四整除且不能被100整除或能被400整除
#include<stdio.h>
void main()
{
if((year%4==0)&&(year%100!=0)||(year%400==0))
{
printf("the year is leap");
}
else
{
printf("the year isn't leap");
}
}
14、求斐波那契数列前40个数。
f1 =1 (n=1) f2=1(n=2) f(n)= f(n-1)+f(n-2) (n>3)
#include<stdio.h>
void main()
{
long int a1=1,a2=1; //40个数已经超过int的范围
int i;
for(i=1;i<=20;i++)
{
printf("%12ld %12ld ",a1,a2); //以12位的长整型输出
if(i%2 == 0) printf("\n");
a1 = a1+ a2;
a2 = a2+ a1;
}
}
运行结果:
1 1 2 3
5 8 13 21
34 55 89 144
233 377 610 987
1597 2584 4181 6765
10946 17711 28657 46368
75025 121393 196418 317811
514229 832040 1346269 2178309
3524578 5702887 9227465 14930352
24157817 39088169 63245986 102334155
15、冒泡排序
所谓的冒泡排序,其实指的是对数组中的数据进行排序,按照从小到大的顺序来进行排列.
void main() { int i,j,temp=0; int a[8] = {6,4,8,2,5,3,7,1}; int arrysize = sizeof(a)/sizeof(a[0]); for(i=0;i<arrysize;i++) { for(j=0;j<arrysize-i-1;j++) { if(a[j] > a[j+1]) { temp = a[j]; a[j] = a[j+1]; a[j+1] = temp; } } } for(i=0;i<arrysize;i++) { printf("%d ",a[i]); } }
16、选择排序(Selection Sort)
算法原理
选择排序(Selection-sort)是一种简单直观的排序算法。
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
void SelectionSort(int *Array,int ArraySize)
{
int i,j,temp;
for(i=0;i<ArraySize-1;i++)
{
for(j = i+1;j<ArraySize;j++)
{
if(Array[i]<Array[j])
{
temp = Array[i];
Array[i] = Array[j];
Array[j] = temp;
}
}
}
}
void main()
{
int i;
int Array[10] = {4,3,5,7,6,9,1,6,9,0};
int size = sizeof(Array)/sizeof(Array[0]);
SelectionSort(Array,size);
for(i=0;i<size;i++)
{
printf(" %d",Array[i]);
}
}
17、插入排序
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
算法描述
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5。
void InsertionSort(int *arr, int size)
{
int i, j, tmp;
for (i = 1; i < size; i++) {
if (arr[i] < arr[i-1]) {
tmp = arr[i];
for (j = i - 1; j >= 0 && arr[j] > tmp; j--) {
arr[j+1] = arr[j];
}
arr[j+1] = tmp;
}
}
}
18、归并排序(Merge Sort)
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
5.1 算法描述
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
#define MAXSIZE 100 void Merge(int *SR, int *TR, int i, int middle, int rightend) { int j, k, l; for (k = i, j = middle + 1; i <= middle && j <= rightend; k++) { if (SR[i] < SR[j]) { TR[k] = SR[i++]; } else { TR[k] = SR[j++]; } } if (i <= middle) { for (l = 0; l <= middle - i; l++) { TR[k + l] = SR[i + l]; } } if (j <= rightend) { for (l = 0; l <= rightend - j; l++) { TR[k + l] = SR[j + l]; } } } void MergeSort(int *SR, int *TR1, int s, int t) { int middle; int TR2[MAXSIZE + 1]; if (s == t) { TR1[s] = SR[s]; } else { middle = (s + t) / 2; MergeSort(SR, TR2, s, middle); MergeSort(SR, TR2, middle + 1, t); Merge(TR2, TR1, s, middle, t); }
}
19、快速排序(Quick Sort)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
算法描述
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
void QuickSort(int *arr, int maxlen, int begin, int end)
{
int i, j;
if (begin < end) {
i = begin + 1;
j = end;
while (i < j) {
if(arr[i] > arr[begin]) {
swap(&arr[i], &arr[j]);
j--;
} else {
i++;
}
}
if (arr[i] >= arr[begin]) {
i--;
}
swap(&arr[begin], &arr[i]);
QuickSort(arr, maxlen, begin, i);
QuickSort(arr, maxlen, j, end);
}
}
void swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号