


RDF和Jena RDF API简介
这是官方文章《An Introduction to RDF and the Jena RDF API》的译文。原文是在刺猬的温驯这里看到的。其中的图片没法显示了,还有一段丢失了。于是我在此也补充翻译一下。^_^
前言
本文是一篇对W3C的资源描述框架(RDF)和 Jena(一个Java的RDF API)的教程性介绍. 本文是为那些不熟悉RDF的, 以及那些通过建立原形可以达到最好学习效果的, 或是因为其他原因希望能快速操作Jena的程序员而写的. 我们假设读者在阅读本文前已具有一定的XML和Java知识.
如果读者在没有理解RDF数据模型的基础上就迅速进入操作阶段,往往会导致失败和失望. 然而,如果光学习数据模型又是十分枯燥乏味的, 并常常会导致曲折的形而上学的难题. 更好的学习办法是在理解数据模型的同时练习操作它. 可以先学习一点数据模型再动手试一试.然后在学习一点再试一试. 这样一来就能达到理论实践相结合的效果.数据模型本身十分简单,所以学习过程不会太长.
RDF具有XML的语法, 所以许多熟悉XML的人就会认为以XML语法的形式来思考RDF. 然而, 这是不对的. RDF应该以它数据模型的形式来被理解. RDF数据可是用XML来表示, 但是理解数据模型的重要性更在理解此语法重要性之上.
Jena API的一个运行例子, 包括本教程中所有例子的工作源代码都可以在http://www.hpl.hp.com/semweb/下载.
________________________________________
目录
1. 导言
2. 陈述Statements
3. RDF写操作
4. RDF读操作
5. Jena RDF 包
6. 操纵模型
7. 查询模型
8. 对模型的操作
9. 容器Containers
10. 关于Literals和数据类型的更多探讨
11. 术语表
________________________________________
导言
资源描述框架是(RDF)是描述资源的一项标准(在技术上是W3C的推荐标准). 什么是资源? 这实在是一个很难回答的问题, 其精确的定义目前尚在争论中. 出于我们的目的, 我们可以把资源想象成任何我们可以确定识别的东西. 在本教程中,读者你本身就是一个资源, 而你的主页也是一个资源, 数字1和故事中巨大的白鲸都是资源.
在本教程中, 我们的例子会围绕人们展开. 假设人们会使用VCARDS, 而VCARD将由RDF表示机制来描述. 我们最好把RDF考虑成由结点和箭头的形式构成的图. 一个简单的vcard在RDF中可能看起来是这样的:
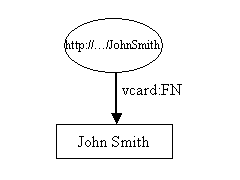
资源John Smith在图中用椭圆表示, 并被一个统一资源定位符(URI) 所标识, 在本例中是"http://.../JohnSmith"). 如果你想要通过你的浏览器来访问这个资源的话,你很有可能会失败. 四月的愚人节笑话并不经得起考验, 相反如果你的浏览器把John Smith传递到你的桌面的话, 你才该感到惊讶. 如果你并不熟悉URI's的话, 你可以把它们想象成简单的陌生名字.
资源拥有属性(property). 在这些例子中, 我们对John Smith名片上出现的那些属性很感兴趣.图1只显示了一个属性, John Smith的全名. 属性是由标有属性名的箭头表示的. 属性的名字也是一个URI, 但是由于URI十分冗长笨重, 所以图中将它显示为XML qname的形式. 在':'之前的部分称为命名空间前缀并表示了一个命名空间. 在':'之后的部分称为局部名, 并表示在命名空间中的一个名字. 在写成RDF XML形式时, 属性常常以qname的形式表示, 这是一个在图形和文本中的简单的缩写方法. 然而, 严格地讲, 属性应该用URI来标识. 命名空间前缀:局部名的形式是一种命名空间连接局部名的URI缩写. 当浏览器访问时, 用并没有强制属性的URI必须指向一些具体的事物.
每个属性都有一个值. 在此例中, 值为一个文本(literal), 我们现在可以把它看成一个字符串.文本在图中显示为长方形.
Jena是一个Java API, 我们可以用它来创建和操纵诸如上述例图的RDF图. Jena设有表示图(graph), 资源(resource), 属性和文本(literal)的对象类. 表示资源, 属性和文本的接口分别称为Resource, Property, 和Literal. 在Jena中, 一个图(graph)被称为一个模型并被Model接口所表示.
创建上述例图或称为上述模型的代码很简单:
// some definitions
static String personURI = "http://somewhere/JohnSmith";
static String fullName = "John Smith";
// create an empty Model
Model model = ModelFactory.createDefaultModel();
// create the resource
Resource johnSmith = model.createResource(personURI);
// add the property
johnSmith.addProperty(VCARD.FN, fullName);
这些代码先定义了一些常量, 然后使用了ModelFactory类中的createDefaultMode()方法创建了一个空的基于内存存储的模型(Model 或 model). Jena还包含了Model接口的其他实现方式. 例如, 使用关系数据库的, 这些类型 Model接口也可以从ModelFactory中创建.
于是John Smith这个资源就被创建了, 并向其添加了一个属性. 此属性由一个"常" ("constant")类VCARD提供, 这个类保存了在VCARD模式(schema)中所有定义的表示对象. Jena也为其他一些著名的模式提供了常类的表示方法, 例如是RDF和RDF模式, Dublin 核心标准和DAML.
创建资源和添加属性的代码可以写成更紧凑的层叠形式:
Resource johnSmith =
model.createResource(personURI)
.addProperty(VCARD.FN, fullName);
这个例子的工作代码可以在Jena发布的材料的教程包中的Tutorial1中找到. 作为练习, 你自己可以获得此代码并修改其以创建一个简单VCARD.
现在让我们为vcard再增加一些更详细的内容, 以便探索更多的RDF和Jena的特性.
在第一个例子里, 属性值为一个文本. 然而RDF属性也可以采用其他的资源作为其属性值. 下面这个例子使用常用的RDF技术展示了如何表示John Smith名字的不同部分: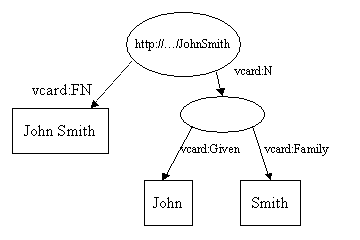
在这里我们增加了一个新的属性, vcard:N, 来表示John Smith名字的结构. 这个模型有几点有趣之处. 注意属性vcard:N使用一个资源作为起属性值. 同时注意代表复合名字的椭圆并没有URI标识. 它被认为是一个空白结点(blank Node).
创建此例的Jena代码也十分简单. 首先是一些声明和对空模型的创建.
// some definitions
String personURI = "http://somewhere/JohnSmith";
String givenName = "John";
String familyName = "Smith";
String fullName = givenName + " " + familyName;
// create an empty Model
Model model = ModelFactory.createDefaultModel();
// create the resource
// and add the properties cascading style
Resource johnSmith
= model.createResource(personURI)
.addProperty(VCARD.FN, fullName)
.addProperty(VCARD.N,
model.createResource()
.addProperty(VCARD.Given, givenName)
.addProperty(VCARD.Family, familyName));
此例的工作代码可以在Jena发布材料的教程包的Tutorial2中得到.
________________________________________
陈述
RDF模型中的每一个箭头表示为一个陈述(statement). 每一个陈述声明了关于某个资源的某个事实. 一个陈述有三部分组成.
主体, 也就是箭头的出发的资源.
谓词, 也就是标识箭头的属性.
客体, 也就是箭头所指向的那个资源或文本.
一个陈述有时也叫做一个三元组的原因就是它由三部分组成.
一个RDF模型(译者注: 指Jena中的接口Model)是由一组陈述所组成的. 在Tutorial2中, 每调用一次addProperty函数就会在模型中增加另一个陈述. (因为一个模型是由一组陈述组成的, 所以增加一个重复的陈述并不会产生任何意义.) Jena模型接口定义了一个listStatements()方法, 此方法会返回一个StmtIterator类型的变量. StmtItor是Java中Iterator的一个子类型, 这个StmtIterator变量重复迭代了该接口模型中的所有陈述. StmtIterator类型中有一个方法nextStatement(), 该方法会从iterator返回下一个陈述. (就和next()返回的一样, 但是已将其映射为Statement类型). 接口Statement提供了访问陈述中主体, 谓词和客体的方法.
现在我们会用使用那个接口来扩展Tutorial2, 使起列出所有的创建的陈述并将它们打印出来. 此例完整的代码可以在Tutorial3中找到.
// list the statements in the Model
StmtIterator iter = model.listStatements();
// print out the predicate, subject and object of each statement
while (iter.hasNext()) {
Statement stmt = iter.nextStatement(); // get next statement
Resource subject = stmt.getSubject(); // get the subject
Property predicate = stmt.getPredicate(); // get the predicate
RDFNode object = stmt.getObject(); // get the object
System.out.print(subject.toString());
System.out.print(" " + predicate.toString() + " ");
if (object instanceof Resource) {
System.out.print(object.toString());
} else {
// object is a literal
System.out.print(" /"" + object.toString() + "/"");
}
System.out.println(" .");
}
因为一个陈述的客体可以是一个资源也可以是一个文本. getObject()方法会返回一个类型为RDFNode的客体, RDFNode是Resource和Literal类共同的超类. 为了确定本例中的客体确切的类型, 代码中使用 instanceof来确定其类型和相应的处理.
运行后, 此程序回产生与此相似的输出:
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#N anon:14df86:ecc3dee17b:-7fff.
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Family "Smith".
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Given "John" .
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#FN "John Smith".
现在你明白了为什么模型构建会更加清晰. 如果你仔细观察, 就会发现上面每一行都由三个域组成, 这三个域分别代表了每一个陈述的主体, 谓词和客体. 在此模型中有四个箭头, 所以会有四个陈述. "anon:14df86:ecc3dee17b:-7fff"是有Jena产生的一个内部标识符, 它不是一个URI, 也不应该与URI混淆. 它只是Jena处理时使用的一个内部标号.
W3C的RDF核心工作小组定义了一个类似的表示符号称为N-三元组(N-Triples). 这个名字表示会使用"三元组符号". 在下一节中我们会看到Jena有一个内置的N-三元组写机制(writer).
________________________________________
写RDF
Jena设有读写XML形式的RDF方法. 这些方法可以被用来将一个RDF模型保存到文件并在日后重新将其读回.
Tutorial3创建了一个模型并将其以三元组的形式输出. Tutorial4对Tutorial3做了修改, 使其将此模型以RDF XML的形式输出到标准输出流中. 这个代码依然十分简单: model.write可以带一个OutputStream的参数.
// now write the model in XML form to a file
model.write(System.out);
应该有类似的输出:
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:about='http://somewhere/JohnSmith'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
<rdf:Description rdf:nodeID="A0">
<vcard:Given>John</vcard:Given>
<vcard:Family>Smith</vcard:Family>
</rdf:Description>
</rdf:RDF>
W3C的RDF规格说明书规定了如何用 XML的形式来表示RDF. RDF XML的语法十分复杂. 读者可以在RDF核心工作小组制定的RDF入门篇(primer)中找到更详细的指导. 但是不管怎么样, 让我们先迅速看一下应该如何解释上面的RDF XML输出
RDF常常嵌入在一个<rdf:RDF>元素中. 如果有其他的方法知道此XML是RDF的话,该元素是可以不写的. 然而我们常常会使用它. 在这个RDF元素中定义了两个在本文档中使用的命名空间. 接下来是一个<rdf:Description>元素, 此元素描述了URI为"http://somewhere/JohnSmith"的资源. 如果其中的rdf:about属性被省略的话, 这个元素就表示一个空白结点.
<vcard:FN>元素描述了此资源的一个属性. 属性的名字"FN"是属于vcard命名空间的. RDF会通过连接命名空间前缀的URI和名字局部名"FN"来形成该资源的URI "http://www.w3.org/2001/vcard-rdf/3.0#FN". 这个属性的值为文本"John Smith".
<vcard:N>元素是一个资源. 在此例中, 这个资源是用一个相对URI来表示的. RDF会通过连接这个相对URI和此文档的基准URI来把它转换为一个绝对URI.
但是, 在这个RDF XML输出中有一个错误, 它并没有准确地表示我们所创建的模型. 模型中的空白结点被分配了一个URI. 它不再是空白的了. RDF/XML语法并不能表示所有的RDF模型. 例如它不能表示一个同时是两个陈述的客体的空白结点. 我们用来写这个RDF/XML的'哑'writer方法并没有试图去正确的书写这个模型的子集, 虽然其原本可以被正确书写. 它给每一个空白结点一个URI, 使其不再空白.
Jena有一个扩展的接口, 它允许新的为不同的RDF串行化语言设计的writer可以被轻易地插入. 以上的调用会激发一个标准的'哑'writer方法. Jena也包含了一个更加复杂的RDF/XML writer, 它可以被用携带另一个参数的write()方法所调用.
// now write the model in XML form to a file
model.write(System.out, "RDF/XML-ABBREV");
此writer, 也就是所谓的PrettyWriter, 利用RDF/XML缩写语法把模型写地更为紧凑. 它也能保存尽可能保留空白结点. 然而, 它并不合适来输出大的模型. 因为它的性能不可能被人们所接受. 要输出大的文件和保留空白结点, 可以用N-三元组的形式输出:
// now write the model in XML form to a file
model.write(System.out, "N-TRIPLE");
这会产生类似于Tutorial3的输出, 此输出会遵循N-三元组的规格.
________________________________________
读RDF
Tutorial 5 演示了如何将用RDF XML记录的陈述读入一个模型. 在此例中, 我们提供了一个小型RDF/XML形式的vcard的数据库. 下面代码会将其读入和写出. 注意: 如果要运行这个小程序, 应该把输入文件放在你的classpath所指向的目录或jar中.
// create an empty model
Model model = ModelFactory.createDefaultModel();
// use the class loader to find the input file
InputStream in = Tutorial05.class
.getClassLoader()
.getResourceAsStream(inputFileName);
if (in == null) {
throw new IllegalArgumentException(
"File: " + inputFileName + " not found");
}
// read the RDF/XML file
model.read(new InputStreamReader(in), "");
// write it to standard out
model.write(System.out);
read()方法中的第二个参数是一个URI, 它是被用来解决相对URI的. 因为在测试文件中没有使用相对URI, 所以它允许被置为空值. 运行时, Tutorial5会产生类似如下的XML输出
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:nodeID="A0">
<vcard:Family>Smith</vcard:Family>
<vcard:Given>John</vcard:Given>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/JohnSmith/'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/SarahJones/'>
<vcard:FN>Sarah Jones</vcard:FN>
<vcard:N rdf:nodeID="A1"/>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/MattJones/'>
<vcard:FN>Matt Jones</vcard:FN>
<vcard:N rdf:nodeID="A2"/>
</rdf:Description>
<rdf:Description rdf:nodeID="A3">
<vcard:Family>Smith</vcard:Family>
<vcard:Given>Rebecca</vcard:Given>
</rdf:Description>
<rdf:Description rdf:nodeID="A1">
<vcard:Family>Jones</vcard:Family>
<vcard:Given>Sarah</vcard:Given>
</rdf:Description>
<rdf:Description rdf:nodeID="A2">
<vcard:Family>Jones</vcard:Family>
<vcard:Given>Matthew</vcard:Given>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/RebeccaSmith/'>
<vcard:FN>Becky Smith</vcard:FN>
<vcard:N rdf:nodeID="A3"/>
</rdf:Description>
</rdf:RDF>
________________________________________
前缀的操作
显示前缀定义
在前面的章节中,我们可以看到在输出XML中声明了命名空间前缀vcard并且用这个前缀表示资源的URI缩写。. 虽然RDF只使用URI的全长拼写,而不是用它的缩写形式。JENA却使用前缀对应(映射)的方式,提供了在输出时操作命名空间的写法。兴趣个简单的例子。
Model m = ModelFactory.createDefaultModel(); String nsA = "http://somewhere/else#"; String nsB = "http://nowhere/else#"; Resource root = m.createResource( nsA + "root" ); Property P = m.createProperty( nsA + "P" ); Property Q = m.createProperty( nsB + "Q" ); Resource x = m.createResource( nsA + "x" ); Resource y = m.createResource( nsA + "y" ); Resource z = m.createResource( nsA + "z" ); m.add( root, P, x ).add( root, P, y ).add( y, Q, z ); System.out.println( "# -- no special prefixes defined" ); m.write( System.out ); System.out.println( "# -- nsA defined" ); m.setNsPrefix( "nsA", nsA ); m.write( System.out ); System.out.println( "# -- nsA and cat defined" ); m.setNsPrefix( "cat", nsB ); m.write( System.out );
从这段代码运行的结果产生的三段RDF/XML,由于对应的前缀应对(映射)不同产生的RDF/XML也不同。默认的形式显示在第一段,没有任何前缀的形式(其实是系统内容的前缀,只是名字不好看)。
# -- no special prefixes defined <rdf:RDF xmlns:j.0="http://nowhere/else#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:j.1="http://somewhere/else#" > <rdf:Description rdf:about="http://somewhere/else#root"> <j.1:P rdf:resource="http://somewhere/else#x"/> <j.1:P rdf:resource="http://somewhere/else#y"/> </rdf:Description> <rdf:Description rdf:about="http://somewhere/else#y"> <j.0:Q rdf:resource="http://somewhere/else#z"/> </rdf:Description> </rdf:RDF>
我们可以看到这个RDF命名空间是自动声明的, 因数它是标签<rdf:RDF>和<rdf:resource>必需的。 属性P和Q的使用也需要声音XML命名空间, 但在这个例子中,没有显示的为模型给定它们的前缀。它们就选择系统内部生成的(虚拟的)命名空间: j.0 和 j.1。
方法setNsPrefix(String prefix, String URI)声明了命名空间URI可以由prefix缩写。JENA需要为它指定的这个prefix符合XML命名空间名字的规范,并且URI以非名称字符结束。在输出RDF/XML时,就会使用这些声明的前缀来缩写RDF/XML中的命名空间:
# -- nsA defined <rdf:RDF xmlns:j.0="http://nowhere/else#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:nsA="http://somewhere/else#" > <rdf:Description rdf:about="http://somewhere/else#root"> <nsA:P rdf:resource="http://somewhere/else#x"/> <nsA:P rdf:resource="http://somewhere/else#y"/> </rdf:Description> <rdf:Description rdf:about="http://somewhere/else#y"> <j.0:Q rdf:resource="http://somewhere/else#z"/> </rdf:Description> </rdf:RDF>
这里可以看到nsA已经被用在属性标签中了,但是别的命名空间依然使用系统构建的。在JENA代码中,只是用到这个方法,并不需要别的任何操作了:
# -- nsA and cat defined <rdf:RDF xmlns:cat="http://nowhere/else#" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:nsA="http://somewhere/else#" > <rdf:Description rdf:about="http://somewhere/else#root"> <nsA:P rdf:resource="http://somewhere/else#x"/> <nsA:P rdf:resource="http://somewhere/else#y"/> </rdf:Description> <rdf:Description rdf:about="http://somewhere/else#y"> <cat:Q rdf:resource="http://somewhere/else#z"/> </rdf:Description> </rdf:RDF>
两个前缀都使用到输出中的URI缩写中了,没有使用任何的系统内部的前缀。
隐式定义前缀
除了调用setNsPrefix方法声明前缀,其它JENA也会记住你在调用model.read()方法时读入RDF使用的前缀。
把前面代码生成的RDF/XML(有前缀的)粘贴到一个文件中,命名为file:/tmp/fragment.rdf。然后运行以下代码。
Model m2 = ModelFactory.createDefaultModel(); m2.read( "file:/tmp/fragment.rdf" ); m2.write( System.out );
你将会看到从入库的文件中使用的前缀也会出现在输出文件各。所有的前缀都被声明在了输出文件上,除非那个前缀没有被使用(声明了但未使用)。如果有某些前缀不想用,不希望出现在输出中,可以调用removeNsPrefix(String prefix)方法取消使用。
N-Triples没有关于缩写URI的方式,不需要在意前缀和在输出上使用前缀。JENA也支持N3,没有前缀缩写,在输入中记录,在输出中使用(这句不知道怎么翻译了,原文:Since NTriples doesn't have any short way of writing URIs, it takes no notice of prefixes on output and doesn't provide any on input. The notation N3, also supported by Jena, does have short prefixed names, and records them on input and uses them on output.)。
JENA还有对模型中的前缀映射有更进一步的操作,比如把现有的些映射关系封装成一个java的Map对象(接口),或者一次性添加一批映射。关于PrefixMapping的更多细节请参阅相关文档。
________________________________________
Jena RDF 包
Jena是一个为语义网应用设计的一个Java API. 对应用开发者而言, 主要可用的RDF包是com.hp.hpl.jena.rdf.model. 因为API是以接口的方式定义的, 所以应用代码可以使用不同的实现机制而不用改变代码本身. 这个包包含了可以表示模型, 资源, 属性, 文本, 陈述和其他RDF关键概念的接口, 还有一个用来创建模型的ModelFactory. 所以如果要应用代码与实现类保持独立, 最好尽可能地使用接口, 而不要使用特定的实现类.
com.hp.hpl.jena.Tutorial包包含了本教程所有例子中使用到的工作源代码.
com.hp.hpl.jena.impl这些包包含了许多执行时所常用的执行类. 比如, 它们定义了诸如ResourseImpl, PropertyImpl和LiteralImpl的类, 这些类可以被不同的应用直接使用也可以被继承使用. 应用程序应该尽可能少地直接使用这些类. 例如, 与其使用ResouceImpl来创建一个新的实例, 更好的办法是使用任何正在使用的模型的createResource方法来完成. 那样的话, 如果模型的执行采用了一个优化的Resouce执行, 那么在这两种类型中不需要有任何的转换工作.
________________________________________
操纵模型
到目前为止, 本教程主要讲述的是如何创建, 读入和输出RDF模型. 现在是时候要讲述如何访问模型中的信息.
如果有了一个资源的URI, 那么就可以用Model.getResource(String uri)来从模型获取这个资源对象. 这个方法被定义来返回一个资源对象, 如果它确实存在于模型中, 否则的话就创建一个新的. 例如, 如何从模型中获取Adam Smith资源, 这个模型是Tutorial5中从文件读入的:
// retrieve the John Smith vcard resource from the model
Resource vcard = model.getResource(johnSmithURI);
Resouce接口定义了一系列用于访问某个资源的属性的方法. Resource.getProperty(Property p)方法访问了该资源的属性. 这个方法不允许通常的Java访问的转换, 因为所返回的对象是Statement, 而不是你所预计的Property. 返回整个陈述的好处是允许应用程序通过使用它的某个访问方法来访问该陈述的客体来访问这个属性值. 例如如何获取作为vcard:N属性值的资源:
// retrieve the value of the N property
Resource name = (Resource) vcard.getProperty(VCARD.N)
.getObject();
一般而言, 一个陈述的客体可以是一个资源或是一个文本. 所以此应用程序代码知道这个值一定是个资源, 就将类型资源映射到返回的对象上. Jena的目标之一是提供会返回值为特定类型的方法, 这样,应用程序就不必再做类型转换工作, 也不必再编译时做类型检查工作. 以上的代码片段也可以写成更方便的形式:
// retrieve the value of the FN property
Resource name = vcard.getProperty(VCARD.N)
.getResource();
类似地, 属性的文本值也可以被获取:
// retrieve the given name property
String fullName = vcard.getProperty(VCARD.FN)
.getString();
在这个例子中, 资源vcard只有一个vcard:FN属性和一个vcard:N属性. RDF允许资源有重复的属性, 例如Adam可能有超过一个的昵称. 让我们假设他有两个昵称:
// add two nickname properties to vcard
vcard.addProperty(VCARD.NICKNAME, "Smithy")
.addProperty(VCARD.NICKNAME, "Adman");
正如前面所提到的那样, Jena将RDF模型表示为一组陈述, 所以在模型中新增一个与原有陈述有着相同的主体,谓词和客体的陈述并不会后什么作用. Jena没有定义会返回模型中存在的两个昵称中的哪一个. Vcard.getProperty(VCARD.NICKNAME)调用的结果是不确定的. Jena会返回这些值中的某一个, 但是并不保证两次连续的调用会同一个值.
一个属性很有可能会出现多次, 而方法Resource.listProperty(Property p)可以用来返回一个iterator, 这个iterator会列出所有的值. 此方法所返回的iterator返回的对象的类型为Statement.我们可以像这样列出所有的昵称:
// set up the output
System.out.println("The nicknames of /""
+ fullName + "/" are:");
// list the nicknames
StmtIterator iter = vcard.listProperties(VCARD.NICKNAME);
while (iter.hasNext()) {
System.out.println(" " + iter.nextStatement()
.getObject()
.toString());
}
此代码可以在Tutorial6中找到, 运行后会产生如下输出:
The nicknames of "John Smith" are:
Smithy
Adman
一个资源的所有属性可以用不带参数的listStatement()方法列出.
________________________________________
查询模型
前一节讨论了如何通过一个有着已知URI的资源来操纵模型. 本节要讨论查询模型. 核心的Jena API只支持一些有限的查询原语. 对于更强大查询设备RDQL的介绍不在此文档中.
列出模型所有陈述的Model.listStatements()方法也许是最原始的查询模型方式. 然而并不推荐在大型的模型上使用这个方法. 类似的有Model.listSubjects(), 但其所返回的iterator会迭代所有含有属性的资源, 例如是一些陈述的主体.
Model.listSubjectsWithProperty(Property p, RDFNode o)方法所返回的iterator跌代了所有具有属性p且p属性的值为o的资源. 我们可能会预计使用rdf:type属性来搜索资源的类型属性以获得所有的vcard资源:
// retrieve all resource of type Vcard.
ResIterator iter = model.listSubjectsWithProperty(RDF.type, VCARD.Vcard);
然而, 不幸的是, 我们现在正在使用的vcard模式并没有为vcard定义类型. 然而, 如果我们假设只有类型为vcard的资源才会使用vcard:FN属性, 并且在我们的数据中, 所有此类资源都有这样一个属性, 那么我们就可以像这样找到所有的vcard:
// list vcards
ResIterator iter = model.listSubjectsWithProperty(VCARD.FN);
while (iter.hasNext()) {
Resource r = iter.nextResource();
...
}
所有的这些查询方法不过是在原语查询方法model.listStatements(Select s)上稍做变化而已. 此方法会返回一个iterator, 该iterator会跌代模型中所有被s选中的陈述. 这个selector接口被设计成可扩展的, 但是目前, 它只有一个执行类,那就是com.hp.hpl.jena.rdf.model包中的SimpleSelector类. 在Jena中使用SimpleSelector是很少见的情况, 即当需要直接使用一个特定类而不是使用接口. SimpleSelector的构造函数带有三个参数:
Selector selector = new SimpleSelector(subject, predicate, object)
这个selector会选择所有主体与参数subject相配, 谓词与参数predicate相配, 且客体与参数object相配的陈述.
如果某个参数值为null, 则它表示与任何值均匹配; 否则的话, 它们就会匹配一样的资源或文本. (当两个资源有相同的URI或是同一个空白结点时, 这两个资源就是一样的; 当两个文本是一样的当且仅当它们的所有成分都是一样的.) 所以:
Selector selector = new SimpleSelector(null, null, null);
会选择模型中所有的陈述.
Selector selector = new SimpleSelector(null, VCARD.FN, null);
会选择所有谓词为VCARD.FN的陈述, 而对主体和客体没有要求. 作为一个特殊的缩写,
listStatements( S, P, O )
等同与
listStatements( new SimpleSelector( S, P, O ) )
下面的代码可以在Tutorial7中找到, 列举了数据库中所有vcard中的全名.
// select all the resources with a VCARD.FN property
ResIterator iter = model.listSubjectsWithProperty(VCARD.FN);
if (iter.hasNext()) {
System.out.println("The database contains vcards for:");
while (iter.hasNext()) {
System.out.println(" " + iter.nextStatement()
.getProperty(VCARD.FN)
.getString());
}
} else {
System.out.println("No vcards were found in the database");
}
这个会产生类似如下的输出:
The database contains vcards for:
Sarah Jones
John Smith
Matt Jones
Becky Smith
你的下一个练习是修改此代码以使用SimpleSelector而不是使用listSubjectsWithProperty来达到相同的效果.
让我们看看如何对所选择的陈述实行更好的控制. SimpleSelector可以被继承, 它的select方法可以被修改来实现更好的过滤:
// select all the resources with a VCARD.FN property
// whose value ends with "Smith"
StmtIterator iter = model.listStatements(
new SimpleSelector(null, VCARD.FN, (RDFNode) null) {
public boolean selects(Statement s)
{return s.getString().endsWith("Smith");}
});
这个示例使用了一个简洁的Java技术, 就是当创建此类的一个实例时重载一个内联的方法. 这里selects(…)方法会检查以保证全名以"Smith"做结尾. 重要的是要注意对主体, 谓语和客体的过滤是在调用selects(…)方法之前的执行的, 所以额外的测试只会被应用于匹配的陈述.
完整的代码可以在Tutorial8中找到, 并会产生如下的输出:
The database contains vcards for:
John Smith
Becky Smith
你也许会认为下面的代码:
// do all filtering in the selects method
StmtIterator iter = model.listStatements(
new
SimpleSelector(null, null, (RDFNode) null) {
public boolean selects(Statement s) {
return (subject == null || s.getSubject().equals(subject))
&& (predicate == null || s.getPredicate().equals(predicate))
&& (object == null || s.getObject().equals(object))
}
}
});
等同于:
StmtIterator iter =
model.listStatements(new SimpleSelector(subject, predicate, object)
虽然在功能上它们可能是等同的, 但是第一种形式会列举出模型中所有的陈述, 然后再对它们进行逐一的测试. 而第二种形式则允许执行时建立索引来提供性能. 你可以在一个大模型中自己试试验证一下, 但是现在先为自己倒一杯咖啡休息一下吧.
________________________________________
对模型的操作
Jena提供了把模型当作一个集合整体来操纵的三种操作方法. 即三种常用的集合操作:并, 交和差.
两个模型的并操作就是把表示两个模型的陈述集的并操作. 这是RDF设计所支持的关键操作之一. 它此操作允许把分离的数据源合并到一起. 考虑下面两个模型:
 和
和 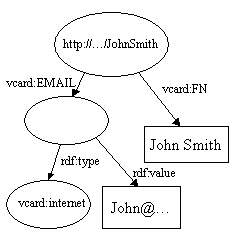
当它们被合并时, 两个http://...JohnSmith会合并成一个, 重复的vcard:FN箭头会被丢弃, 此时就会产生:
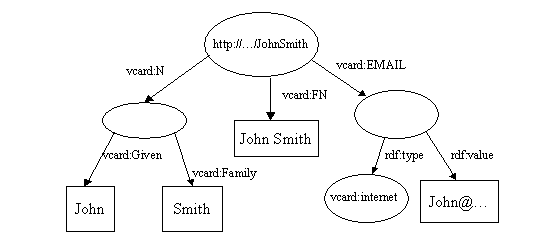
让我们看一下这个代码的功能(完整的代码在Tutorial9中), 再看看会发生什么.
// read the RDF/XML files
model1.read(new InputStreamReader(in1), "");
model2.read(new InputStreamReader(in2), "");
// merge the Models
Model model = model1.union(model2);
// print the Model as RDF/XML
model.write(system.out, "RDF/XML-ABBREV");
petty writer会产生如下的输出:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about="http://somewhere/JohnSmith/">
<vcard:EMAIL>
<vcard:internet>
<rdf:value>John@somewhere.com</rdf:value>
</vcard:internet>
</vcard:EMAIL>
<vcard:N rdf:parseType="Resource">
<vcard:Given>John</vcard:Given>
<vcard:Family>Smith</vcard:Family>
</vcard:N>
<vcard:FN>John Smith</vcard:FN>
</rdf:Description>
</rdf:RDF>
即便你不熟悉RDF/XML的语法细节, 你仍然可以清楚的看见模型如同预期般被合并了. 我们可以在类似的方式下运算模型的交操作和差操作.
________________________________________
容器
RDF定义了一类特殊的资源来表示事物的集合. 这些资源称为容器. 一个容器的成员可以是资源也可以是文本. 有三类容器:
一个BAG是一个无序的集合.
一个ALT是一个用来表示备选项的无序的集合.
一个SEQ是一个有序的集合.
一个容器由一个资源表示. 该资源会有一个rdf:type属性, 属性值为rdf:Bag, 或rdf:Alt, 或是rdf:Seq, 再或是这些类型的子类型, 这取决于容器的类型. 容器的第一个成员是容器的rdf:_1的属性所对应的属性值; 第二个成员是容器的rdf:_2属性的值, 依此类推. 这些rdf:_nnn属性被称为序数属性.
例如, 一个含有Smith的vcard的简单bag容器的模型可能会看起来是这样的:
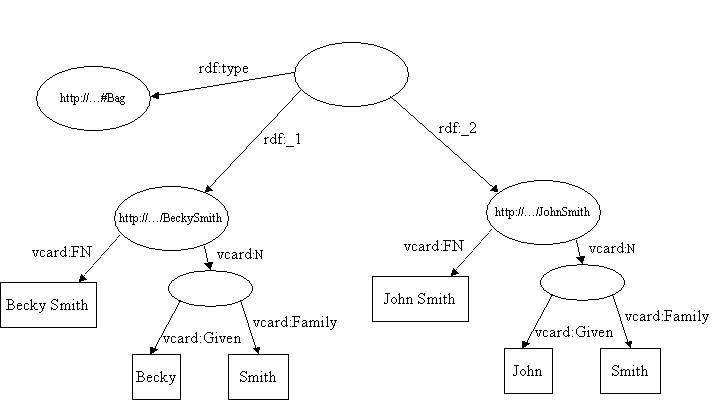
虽然bag容器的成员们被rdf:_1,rdf_2等等的属性所表示, 但是这些属性的顺序却并不重要. 即便我们将rdf:_1和rdf:_2的属性值交换, 但是交换后的模型仍然表示相同的信息.
Alt是设计用来表示被选项的. 例如, 我们假定有一个表示软件产品的资源. 它可能有一个属性指示从哪里可以获得次软件产品. 这个属性值可能是一个包含各种下载地址的Alt集合. Alt是无序的, 除了rdf:_1属性有着特殊的意义, 它表示默认的选项.
尽管我们可以用基本的资源和属性机制来处理容器, Jena为处理容器设计了显式的接口和执行类. 要避免在使用一个对象来操作容器的同时去使用低层方法来改变容器.
让我们修改Tutorial8以创建一个bag:
// create a bag
Bag smiths = model.createBag();
// select all the resources with a VCARD.FN property
// whose value ends with "Smith"
StmtIterator iter = model.listStatements(
new SimpleSelector(null, VCARD.FN, (RDFNode) null) {
public boolean selects(Statement s) {
return s.getString().endsWith("Smith");
}
});
// add the Smith's to the bag
while (iter.hasNext()) {
smiths.add(iter.next().getSubject());
}
如果我们将次模型输出可以看见它含有类似如下的成分:
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
...
<rdf:Description rdf:nodeID="A3">
<rdf:type rdf:resource='http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag'/>
<rdf:_1 rdf:resource='http://somewhere/JohnSmith/'/>
<rdf:_2 rdf:resource='http://somewhere/RebeccaSmith/'/>
</rdf:Description>
</rdf:RDF>
这表示了Bag资源.
容器接口提供了一个iterator来列举容器的内容:
// print out the members of the bag
NodeIterator iter2 = smiths.iterator();
if (iter2.hasNext()) {
System.out.println("The bag contains:");
while (iter2.hasNext()) {
System.out.println(" " +
(Resource) iter2.next())
.getProperty(VCARD.FN)
.getString());
}
} else {
System.out.println("The bag is empty");
}
并会产生如下的输出:
The bag contains:
John Smith
Becky Smith
本例的可执行代码可以在Tutorial10中找到.
Jena类所提供的操纵容器的方法包括增加新成员, 在容器中间插入新成员和删除已有的成员. Jena容器类目前保证所使用的序数属性列表会从rdf:_1开始并且是相邻的. RDF核心工作小组放松了此项限制, 以允许有局部的容器表示. 所以这是Jena将来可能会修改的地方之一.
________________________________________
关于文本(Literals)和数据类型的更多探讨
RDF文本(literals)并不仅仅是简单的字符串而已. 文本可能有一个语言标签来指示该文本使用的语言. 有英语语言标签的文本"chat"会被认为与有着法语语言标签的文本"chat"是不同的. 这个奇怪的特性是原有RDF/XML语法产生的赝象(artefact).
另外, 事实上共有两种文本. 在一种里, 字符串成分只是简单的字符串. 而在另一种里, 字符串成分被预计为格式良好的XML片段. 当一个RDF模型被写成RDF/XML形式时, 一个特殊的使用parseType='Literal'的属性(attribute)构造会被使用来表示它.
在Jena中, 当一个文本被创建时, 这些属性就被设置了. 例如, 在Tutorial11中:
// create the resource
Resource r = model.createResource();
// add the property
r.addProperty(RDFS.label, model.createLiteral("chat", "en"))
.addProperty(RDFS.label, model.createLiteral("chat", "fr"))
.addProperty(RDFS.label, model.createLiteral("<em>chat</em>", true));
// write out the Model
model.write(system.out);
会产生:
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'
>
<rdf:Description rdf:nodeID="A0">
<rdfs:label xml:lang='en'>chat</rdfs:label>
<rdfs:label xml:lang='fr'>chat</rdfs:label>
<rdfs:label xml:lang='en' rdf:parseType='Literal'><em>chat</em></rdfs:label>
</rdf:Description>
</rdf:RDF>
如果两个文本被认为是相同的, 它们一定都是XML的文本或都是简单的文本. 另外, 它们两个要么都没有语言标签, 要么有相同的语言标签. 对简单的文本而言, 两者的字符串一定是相同的. XML文本的等同有两点要求. 第一, 前面提到的要求必须被满足并且字符串必须相同. 第二, 如果它们字符串的cannonicalization一样的话, 它们就是一样的.(译者注: 找不到cannonicalization中文的解释.).
Jena接口也支持类型文字. 老式的对待类型文字的方法是把他们当成是字符串的缩写: 有类型的值会通过Java的常用方法转换为字符串, 并且这些字符串被存储在模型中. 例如, 可以试一试(注意:对于简单类型文字, 我们可以省略对model.createLiteral(…)的调用):
// create the resource
Resource r = model.createResource();
// add the property
r.addProperty(RDFS.label, "11")
.addProperty(RDFS.label, 11);
// write out the Model
model.write(system.out, "N-TRIPLE");
产生的输出如下:
_:A... <http://www.w3.org/2000/01/rdf-schema#label> "11" .
因为两个文本都是字符串"11", 所以只会有一个陈述被添加.
RDF核心工作小组定义了支持RDF数据类型的机制. Jena支持那些使用类型文字的机制; 但是本教程中不会对此讨论.
________________________________________
术语表
空白结点
表示一个资源, 但是并没有指示该资源的URI. 空白结点的作用如同第一逻辑中的存在符合变量.
Dublin 核心
一个关于网络资源的元数据标准. 更详细的信息可以在Dublin Core web site找到.
文本
一个可以作为属性值的字符串.
客体
三元组的一部分, 也就是陈述的值.
谓词
三元组的属性部分.
属性
属性(property)是资源的一个属性(attribute). 例如, DC.title是一个属性, RDF.type也是一个属性.
资源
某个实体. 它可以是一个网络资源, 例如一个网页; 它也可以是一个具体的物理对象, 例如一棵树或一辆车; 它也可以是一个抽象的概念, 例如国际象棋或足球. 资源由URI命名.
陈述
RDF模型中的一个箭头, 通常被解理解为一个事实
主体
RDF模型中箭头出发点的那个资源.
三元组
一个含有主体, 谓词和客体的结构. 是陈述的另一种称呼.
________________________________________
脚注
RDF资源的标签可以包括一个片段标签, 例如http://hostname/rdf/Tutorial/#ch-Introduction, 所以, 严格地讲, 一个RDF资源是由一个URI表示的.
文本可以表示为一个字符串, 也可以有一个可选的语言编码来表示该字符串的语言. 例如, 文本可能有一个表示英语的语言编码"en", 而文本"deux"可能有一个表示法语的语言编码"fr".


