
python 把几个DataFrame合并成一个DataFrame——merge,append,join,conca

pandas provides various facilities for easily combining together Series, DataFrame, and Panel objects with various kinds of set logic for the indexes and relational algebra functionality in the case of join / merge-type operations.
1、merge
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
left ︰ 对象
right ︰ 另一个 对象
on︰ 要 加入 的 列 (名称) 。 必须 在 左 、 右 综合 对象 中 找到 。 如果 不 能 通过 left_index 和 right_index 是 假 , 将 推断 DataFrames 中 的 列 的 交叉点 为 连接 键
left_on ︰ 从 左边 的 综合 使用 作为 键 列 。 可以 是 列名 或 数组 的 长度 等于 长度 综合
right_on ︰ 从 正确 的 综合 , 以 用作 键 列 。 可以 是 列名 或 数组 的 长度 等于 长度 综合
left_index ︰ 如果为 True , 则 使用 索引 (行 标签) 从 左 综合 作为 其 联接 键。 在 与 多重 (层次) 的 综合 , 级别 数 必须 匹配 联接 键 从 右 综合 的 数目
right_index ︰ 相同 用法 作为 正确 综合 left_index
how︰ 之一 '左', '右', '外在'、 '内部'。 默认 为 内部 。 每个 方法 的 更 详细 说明 请 参阅 ︰
sort︰ 综合 通过 联接 键 按 字典 顺序 对 结果 进行排序 。 默认值 为 True , 设置 为 False 将 提高 性能 极大地 在 许多 情况下
suffixes︰ 字符串 后缀 并 不适 用于 重叠 列 的 元组 。 默认值 为 ('_x', '_y')。
copy︰ 即使 重新索引 是 不 必要 总是 从 传递 的 综合 对象 , 复制 的 数据 (默认值 True) 。 在 许多 情况下 不能 避免 , 但 可能会 提高 性能 / 内存 使用情况 。 可以 避免 复制 上述 案件 有些 病理 但 尽管如此 提供 此 选项 。
indicator︰ 将 列 添加 到 输出 综合 呼吁 _merge 与 信息 源 的 每 一行 。 _merge 是 绝对类型 , 并 对 观测 其 合并 键 只 出现 在 '左' 的 综合 , 观测 其 合并 键 只 会出现 在 '正确' 的 综合 , 和 两个 如果 观察 合并 关键 发现 在 两个 right_only left_only 的 值 。
1.result = pd.merge(left, right, on='key')
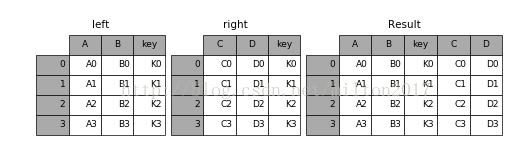
2.result = pd.merge(left, right, on=['key1', 'key2'])
3.result = pd.merge(left, right, how='left', on=['key1', 'key2'])
4.result = pd.merge(left, right, how='right', on=['key1', 'key2'])
5.result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
2、append
1.result = df1.append(df2)

2.result = df1.append(df4)
3.result = df1.append([df2, df3])
4.result = df1.append(df4, ignore_index=True)
4、join
left.join(right, on=key_or_keys)
pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)
1.result = left.join(right, on='key')

2.result = left.join(right, on=['key1', 'key2'])
3.result = left.join(right, on=['key1', 'key2'], how='inner')
4、concat
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
objs︰ 一个 序列 或 系列 、 综合 或 面板 对象 的 映射 。 如果 字典 中 传递 , 将 作为 键 参数 , 使用 排序 的 键 , 除非 它 传递 , 在 这 种情况下 的 值 将 会 选择 (见 下文)。 任何 没有任何 反对 将 默默地 被 丢弃 , 除非 他们 都 没有 在 这 种情况下 将 引发 ValueError 。
axis: {0, 1, ...}, 默认值 为 0。 要 连接 沿 轴 。
join : {'内部'、 '外'}, 默认 '外'。 如何 处理 其他 axis(es) 上 的 索引 。 联盟 内 、 外 的 交叉口 。
ignore_index ︰ 布尔值 、 默认 False 。 如果 为 True , 则 不要 串联 轴 上 使用 的 索引 值 。 由此产生 的 轴 将 标记 0, ... , n - 1。 这 是 有用 的 如果 你 串联 串联 轴 没有 有意义 的 索引 信息 的 对象 。 请注意 在 联接 中 仍然 受到尊重 的 其他 轴 上 的 索引 值 。
join_axes ︰ 索引 对象 的 列表 。 具体 的 指标 , 用于 其他 n - 1 轴 而不是 执行 内部/外部 设置 逻辑 。
keys ︰ 序列 , 默认 为 无 。 构建 分层 索引 使用 通过 的 键 作为 最 外面 的 级别 。 如果 多个 级别 获得通过 , 应 包含 元组 。
levels ︰ 列表 的 序列 , 默认 为 无 。 具体 水平 (唯一 值) 用于 构建 多重 。 否则 , 他们 将 推断 钥匙 。
names ︰ 列表中 , 默认 为 无 。 由此产生 的 分层 索引 中 的 级 的 名称 。
verify_integrity ︰ 布尔值 、 默认 False 。 检查 是否 新 的 串联 的 轴 包含 重复项 。 这 可以 是 相对于 实际 数据 串联 非常 昂贵 。
副本 ︰ 布尔值 、 默认 True 。 如果 为 False , 请 不要 , 不必要地 复制 数据 。
1.frames = [df1, df2, df3]
2.result = pd.concat(frames)

3.result = pd.concat(frames, keys=['x', 'y', 'z'])
4.result.ix['y']
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
5.result = pd.concat([df1, df4], axis=1)
6.result = pd.concat([df1, df4], axis=1, join='inner')
7.result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])
8.result = pd.concat([df1, df4], ignore_index=True)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· .NET10 - 预览版1新功能体验(一)