


回归分析总结
============================================================
回归的目的是用因(x)与果(y)之间的关系,最后达到用因来预测果的目的,相关分析中所涉及的变量x和y都是随机变量;回归分析中,因变量y是随机变量,自变量x可以是随机变量,也可以是非随机的确定变量。
x是没有误差的固定变量,或其误差可以忽略,而y是随机变量,且有随机误差。
==================================================
前提:
在回归中,x是一个观察的已知常数,β是未知常数,y是随机变量,无论何种情况下,误差项都是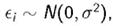
线性模型假设:
1.先画散点图判断y与x是线性关系的
2.y1、y2、y3....yn是独立的,都是正态分布的,
3.误差项也都是独立的且正态分布的
4.残差是方差齐性的,就是不会随x变化而变化等,可以利用散点图来判断:

也可以使用直方图来判断:

===================================================
判定系数等于相关系数的平方:
就一般计算程序来说,是先求出相关系数 r并对其进行假设检验,如果r显著并有进行回归分析之必要,再建立回归方程。
=====================================================
最小二乘法来估计参数,就是使得实际值与估计值的差距的平方最小。
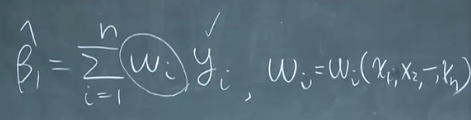
β可以被已知的未知数计算得到是无偏估计的值。但是用最小二乘法可以得到最好的线性无偏估计量,因为变异比较小。所以这种方法就是最稳定的最通用的方法。
如果只有一个β1,也就是只有y与x1,则使用两样本t检验和回归分析是一样的。因为两样本t检验就可以计算β的置信区间,因此也可以在该回归方程中计算β的置信区间。用β来看y与x的相关性,如果y与x有相关性,则β就不为零。
另一种估计参数方法是最大似然函数,用此法估计参数值是一样的,但是仅对于y是连续值情况。
===================================================
分类:
之前讨论y是正态分布,然后将怎么做回归分析
现在讨论y不是正态分布,怎么做回归分析
0、1使用
或者0、1、2、3、4、5使用泊松分布
因为y是count data,也就是泊松分布,所以随机项也是泊松分布系统项必须是线性模型,
,所以在连接函数上下功夫,目的是将E(y)与系统项建立关系。
于是有以下三类:
1.(Y1,Y2,。....YN)可能是正态的。在这种情况下,我们会说随机分量是正态分布。该成分导致了普通回归和方差分析。
2.y是Bernoulli随机变量(其值为0或1),即随机分量为二项分布时,我们通常关注的是Logistic回归模型或Proit模型。
3.y是计数变量1,2,3,4,5,6等,即y具有泊松分布,此时的连接函数时ln(E(y)),这个对泊松分布取对数的操作就是泊松回归模型。
===========================================================
随机项是正态时,在一次方项前的参数是线性效应
在二次方项前的参数是曲线效应
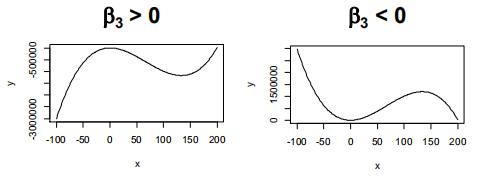
具有一个自变量的三阶模型
1.因变量和1个自变量之间的关系具有“波形”。
2如果出现一个曲率翻转时使用该模型
==========================================================
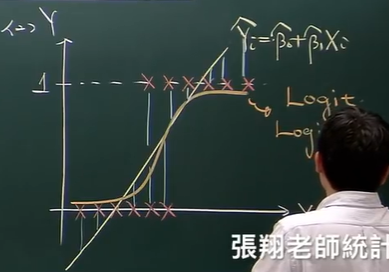
随机项是二项分布时,就是y值通常只有0或1时,y是Bernoulli随机变量(其值为0或1),即随机分量为二项分布时,我们通常关注的是Logistic回归模型或log-linear((就是一步步去做泊松分布)模型。也可用卡方检验
用线性方程估计的y是概率值,在仅知道线性回归的情况下,最终得到的回归方程是这样的,虽然观察值只有0和1,但是根据这些点到函数图像的残差平方最小还是可以得出这个回归曲线,但是这与实际情况不符,因为对于二项分布的结果,仅有0和1,没有其他更大或者更小的值,所以就有了logistics回归。
Odds胜算
Odds=成功/失败=p/(1-p);logistics回归就是log(odds)=βx+β0,即log(p/(1-p))=βx+β0
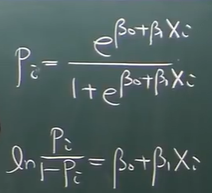
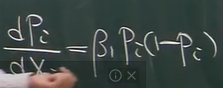
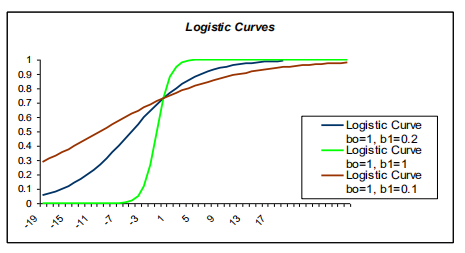
,此梯度就是斜率。它取决于β和x值,如图所示,随x变化而变化,或者,随β变化而变化:
所以没有办法用最小平方法,因为观察数据不是0就是1,不管是1还是1都会使得ln()函数无法表达出来。所以使用最大似然估计
前提:
- y是1或0。
- x是独立的
3.自变量不是彼此的线性组合。
4.图像不是线性的。
5.不要求方差的同质性,因为方差本来就不是同质的。
6.不要求误差分布是正态分布,本来就是针对二项分布的。
分类:
1.如果y是顺序变量,比如疾病轻中重,有序logistics三元回归ordered logistics regression,具体上是两个比较叠加,一个是轻度和中度;一个是中度和重度。
2.如果y是类别变量,比如判别有病或者没病,那就是二元logistics回归
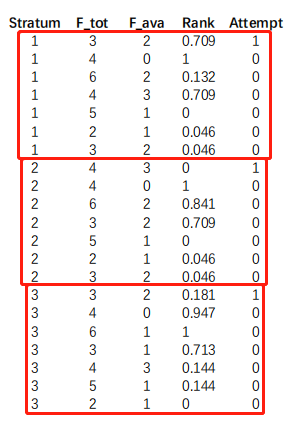
3.条件logistics回归就是基于不同条件下的logistics回归,如图,分成三组:
===========================================================
随机项是计数变量1,2,3,4,5,6等,即y具有泊松分布,此时的连接函数时ln(E(y)),这个对泊松分布取对数的操作就是泊松回归模型。
泊松分布:
- 一段时间与另一段时间成比例
- 一段时间发生次数与时间长短成比例
- 在极短的时间内发生的次数为零
二项分布的极端状况,n趋近无穷大,p趋近于0

公式也可以由二项分布化简而来
过分散是二项分布和泊松数据偶尔出现的现象。对于泊松数据,当响应Y的方差大于泊松方差时,即如果模型是泊松分布,如果模型完全拟合则y的方差与均值应该都相同是一个定值λ,但是有时候观测值得到的方差和均值不同,这就是过分散。
计数数据的零截断和零膨胀模型
零截断意味着响应变量的值不能为0。零膨胀是指计数中有很多零。如果计数资料中含有大量的“0”,则考虑使用零膨胀泊松模型(zero inflated poisson regression, ZIP)或者零膨胀负二项回归
=========================================================
判断有几个变量:
1.做Cp值,如图,如果直线在某处停止,停止处的横坐标便是真实存在几个变量值。

- 分别计算一个变量的AIC或BIC,两个变量的AIC或BIC....n个变量的AIC或BIC,比较之后,如果AIC或BIC比较小则证明这是真实的变量值。
多元线性回归:β1的解释是,其他x2----Xn都不发生改变(即这些变量被控制),只有x1发生改变,单位改变的x1使得y改变的该变量。用最小二乘法估计矩阵。只有所有向量都是线性独立才能计算特征值,所以之前要判断各变量之间确实没有多元共线性。
======================================
看整体x:决定系数是用于评判所有x变量对于y是不是有贡献对于多元线性模型的理解,可以把它认为是多元方差分析,它的决定系数是:

如果加入更多变量,则决定系数变更大,所以这就是R square不足的地方。于是提出
用来平衡模型的复杂程度。之前用F检验,检测一个β斜率,现在用F检验检测多个β斜率。
======================================
看单个x:贡献率:也可以单独挑出来单个变量,评判单变量对于y是否有贡献

看多个x:看两项合起来的因素组,对y的贡献情况,介于上两者之间。
变异分割中的分数[a]就是该变量分担多少变异
==========================================
如果x有高次项,应该先设定成y=β0+β1x+β2x^2+β3x^3+β4x^4,而不是上来就写y=β0+β1x+β4x^4,因为存在高次项,所以一定会有多重共线性形成,即线性相关性。可以使用以下通式:
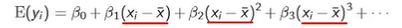
Piecewise线性关系就是每一段的斜率都不相同
Dummy variables用于比较多个组,把一个组作为基础组,其他组作为比较组,然后比较,它的解释是自变量是每一个斜率都是两类别变量下的连续值的差距。

=====================
数据转换
转换为正态分布
转换为方差齐性
转换为更简单的模型
不同y值类型与对应方程的选择:

==========================================================
ANOVA是一种特殊的线性回归
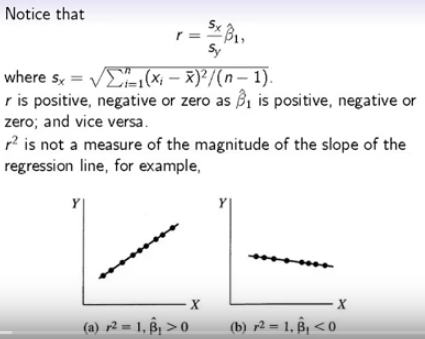
如图:线性回归和线性相关之间的关系:r只和斜率的正负号相同,但是不等同于斜率。r取决于x的变异,y的变异和斜率大小。r只看与拟合的图像重合率有多高。

不做任何操作的变异放在分母,操作了之后的变异放在分子,如果回归比较好,那么SSE会比较好。

线性关系比较好的意思就是实际上的点能够match到我设定的模型上。
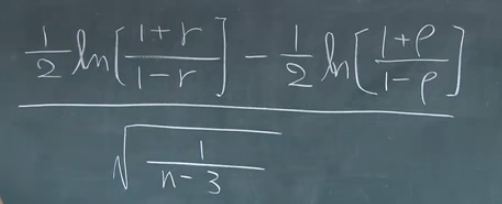 ~N(0,1)
~N(0,1)
据此就可以求出置信区间。
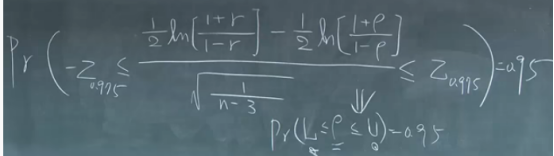
如果x或y出现计数变量,有以下三种情况,
情况一:X或Y都是计数变量
情况二:X是计数变量,Y是连续变量(方差分析)
情况三:X是连续变量,Y是计数变量
普通的r是person correlation coefficient
Spearman correlation coefficient 是将数值变成数值大小对应的序号。
通常都用。
=========================================
在ANOVA中:

只有一个x时有这样的结论:
T分布与F分布的关系是,从图示上可以认为是将t分布负半轴的部分加和到正半轴来,就变成了F分布:
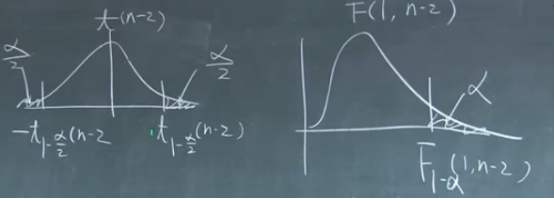

SSR是1,是因为SSR是 ,在这里面X是已知的,只有β是变动值,所以是1.
,在这里面X是已知的,只有β是变动值,所以是1.
而SSE是n-2,是因为SSE本来来自n个y值,但是该n个值受到两个估计参数的限制
====================================================
多元回归模型的评估步骤
- 检测变量类型
多重决定系数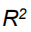 衡量了所有自变量的总体贡献,之后的adj R square是修正值。
衡量了所有自变量的总体贡献,之后的adj R square是修正值。
- 进行残差分析
用于测试函数表达,是线性的还是非线性的,比如加入高次项等。评估违反假设的情况,是何种类型,比如不独立等。
- 测试参数显著性-整个模型and单个参数
使用F检测(SSR/SSE)来检测模型显著性,同方差分析中对斜率的判别。
- 测试多重共线性
多重共线性的X变量会导致不稳定参数
判定高度共线性方法:
两两之间下有两种方法
1.协方差矩阵
2.散点图
除此之外还有
3.VIF:
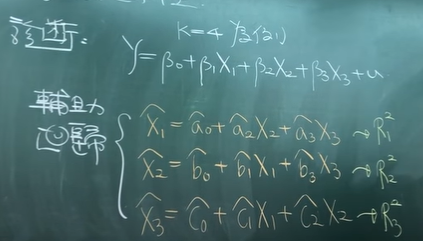
如图所示,仅在X内部计算,与Y没有关系
对X1有相关系数R1,就有VIF1
对X2有相关系数R2,就有VIF2
对X3有相关系数R3,就有VIF3
Max{VIF}>10,则是有危害性的共线性,也就是只要其中的R有任何一个大于0.9那么其对应的VIF就会大于10;只要其中的R有任何一个大于0.8那么其对应的VIF就会大于5 ;
