

Est--编码序列,gene 片段且具有标签
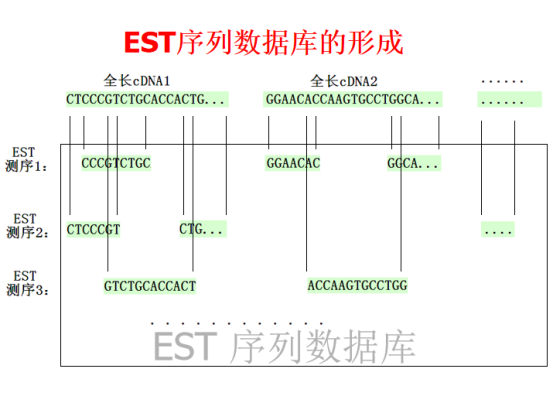
其中,est数据库中是类似测序1、测序2、测序3这样的序列。实验室测得的序列是cDNA,通过上图方法拼接,电脑克隆(dbest)。如果有overlap则认为两个序列来自于同一个gene,overlap的碱基数目是40(不建议低于30,不建议高于40),过少容易拼接乱,过多对碱基突变的容忍性差。就一条序列来说,将比对后延长的结果进行二次比对,以此类推,直到不能延长为止。
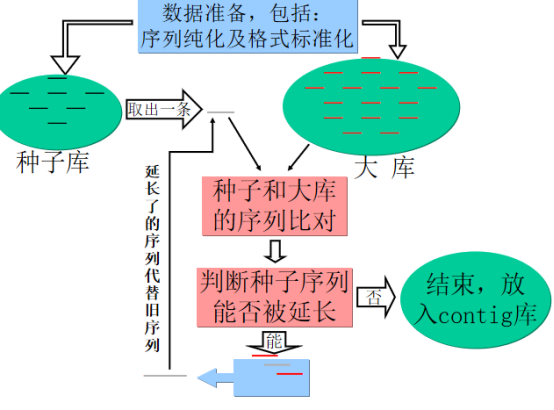
est数据库的覆盖率超过95%。
先利用其他数据库(eg:引物数据库、末端数据库)过滤一遍。即因此在进行Contig电脑组装之前,需要探测并去除EST数据库中的污染序列。
拼接质检方法:Kozak规则,即第一个ATG侧翼序列的碱基分布所满足的统计规律,若将第一个ATG中的碱基A,T,G分别标为1,2,3位,则Kozak规则可描述如下:(1)第4位的偏好碱基为G;(2)ATG的5’端约15bp范围的侧翼序列内不含碱基T;(3)在-3,-6和-9位置。
挑战:
嵌合体问题:基因家族内的gene相似度高,电脑克隆的阈值不足以区分,miss之后将两个不同位置的gene弄混。这需要实验验证。嵌合体cDNA是指来源于不同基因的序列,由于偶然因素被组装在一起形成的Contig。我们构建的神经网络能探测组装过程形成的嵌合体。
发现SNP:对于某一个gene出现多个略有差别的序列,着多个序列中可能存在SNP。
利用何种数据库发现新基因?
基因组序列数据库和EST数据库。
发现原理是什么?
基因组序列数据库是识别,识别编码序列特征和非编码序列有何差异,有多种算法。
EST数据库是拼接,归属于同一gene的est拼接在一起,算法比较单一。
使用EST序列装载gene,可以帮助发现新gene、SNP、可变剪接和发现非编码RNA。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号