

生物医学大数据-蛋白质定量
现今肽段定量效率存在巨大差异。比如相同质量蛋白质,但是肽段和蛋白信号不均一,在物理条件一致时,仅有70%的重复率,并且当重复次数变多时,overlapping在变少。
无标定量法
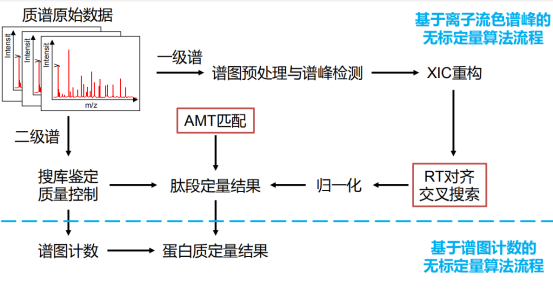
方法一是针对二级色谱的谱图计数,即统计二级色谱的数量,数量越多则蛋白丰度越高,但相同丰度蛋白也有不同的二级色谱数,所以算法目的是减少噪音。
方法二是针对一级色谱的离子流色谱峰XIC,即每个肽段的离子流色谱峰,可以取同一个肽段不同时间点上的信号强度,连接成峰,通过求该曲线的曲线下面积获取曲线信息,通过采集同一个肽段的所有信息利用交叉搜索策略,相互比对后填补丢失量:

在交叉搜索策略中,使用RT对对齐,分别是全局比对和局部比对,最后为了克服系统误差而进行归一化处理,比如max归一化是指将一组数据中的最大值定为1,每组都是同样标准。可以基于谱图数据库找到该二级色谱对应的序列,也可以统一过一级图谱的特征搜索AMT数据库。
基因组与蛋白质在实验技术上的差异,基因组测序重复性好,但是蛋白质质谱实验可重复性低。
脚本串接software无标定量软件,常用的XIC无标定量软件有:
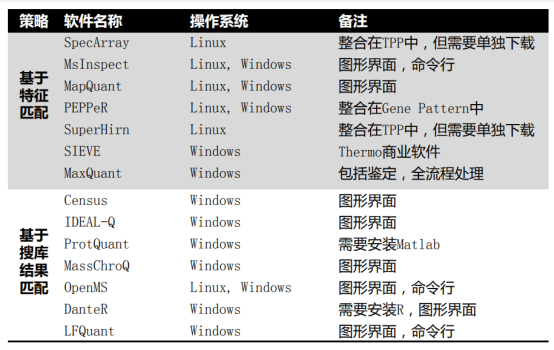
LFQuant 可以对谱图数据进行多级过滤,保留时间对齐和有较好的准确性评估和重复性评估
谱图计数速度快但是精度低和动态范围小,而XIC主要采用搜库能省时且准确,但特征比对就比较耗时。
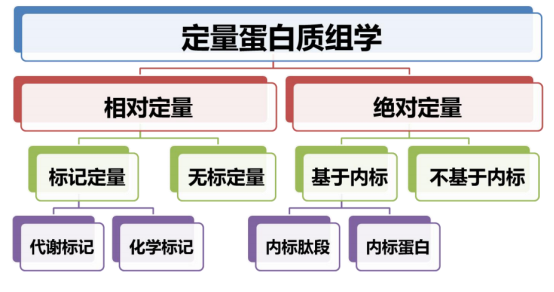
有标定量是采用稳定同位素标记方法:
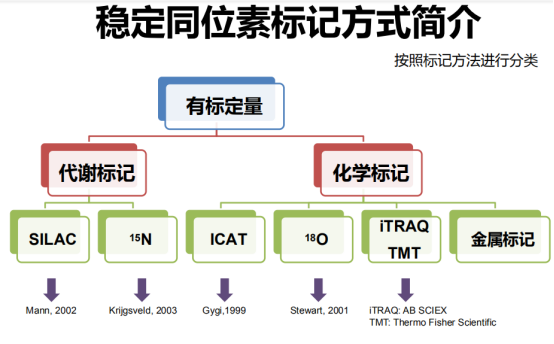
有标定量分为母离子和子离子定量:
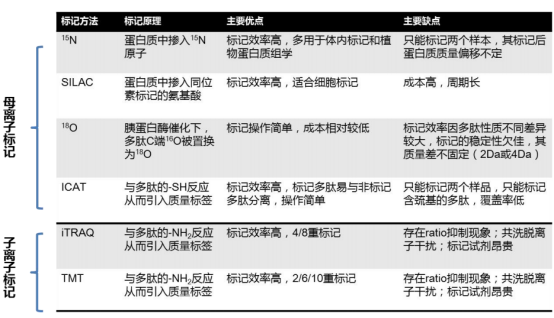
母离子标记software:
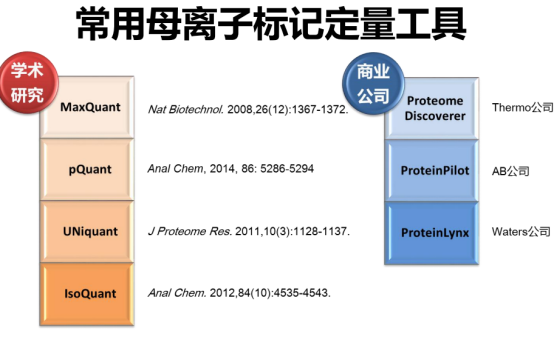
Eg:SILVER

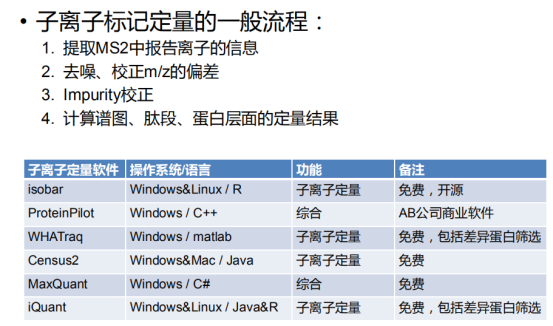
子离子定量软件:
无标定量的试验成本低,适用不同平台数据相比较的情况,较有标定量动态范围大。有标定量受到质谱平台影响小,较为准确。

相对定量比绝对定量误差要小,绝对定量的实验方法是SRM结合内标肽段,常用数据库:

计算方法是iBAQ或APEX等,其中APEX准确性较好。
差异蛋白筛选:

先对蛋白质进行定量,然后缺失值差补,再使用统计学检验方法进行统计学检验,然后使用统计学工具绘制火山图,最后得到差异蛋白列表。常用的Software:
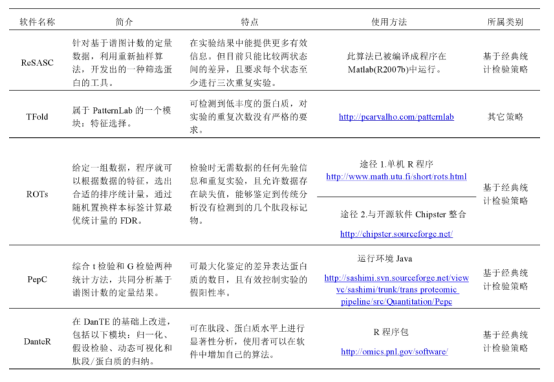
注意:蛋白质多缺失值需要至少三次重复,不滥用p-value,关于生物统计学问题可查看nature生物统计专题。
定量软件:MaxQuant&PANDA

C-HPP可将不同实验室定量结果整合:

高丰度蛋白作用于结构,低丰度作用于调节

