

生物统计学-描述统计
首先必须明确:生物实验的总体是无穷个,而研究人员做生物实验得到的数据永远是样本。因为不同类别的变量指向不同的统计方法,所以必须首先明确变量类型。
变量类型有:
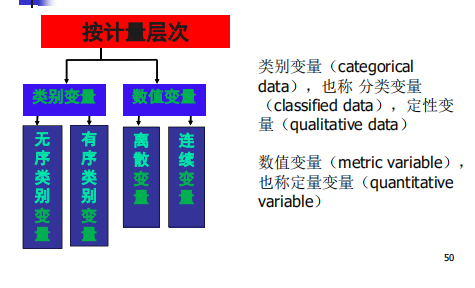
其中,类别变量的本质是字符串,数值变量的本质是数值型,所以,虽然有些类别变量表现为数字,但将它们做运算的结果是没有任何意义的。
数据类型的分类依据有:
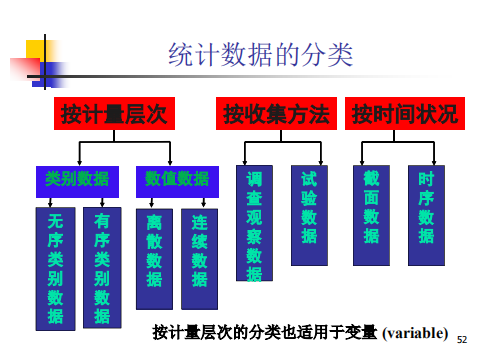
获取方式(观测数据;实验数据)、衡量尺度(数值型数据;顺序数据;分类数据)、属性(定性数据;定量数据)、数学性质(离散数据;连续数据)。。。。。:
其中,二次数据需注意经过何种处理,因为这样才能知道该数据是否适合本研究或者该数据对于本研究是否过时,这是数据筛选的一种。
得到了有效数据之后,将用表与图将这些数据的信息表现出来,关键在于用最简洁的表现方法表现出最大的信息量。
为了进一步分析数据,统计学上规定了一些术语:
随机变量是每次实验都会发生改变的数据,它不是某些数字,而是一种分布;样本容量是每次实验得到的数据个数(eg,一次实验测1000个A的浓度,样本容量为1000)
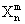 :样本容量是n,有m次试验
:样本容量是n,有m次试验
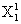 :第一次试验的数据中的第一个测量量,其真实数字将大写X改为小写x表示,并称为测量值。
:第一次试验的数据中的第一个测量量,其真实数字将大写X改为小写x表示,并称为测量值。
 :第一次试验的数据中的第二个测量量
:第一次试验的数据中的第二个测量量
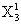 :第一次试验的数据中的第三个测量量
:第一次试验的数据中的第三个测量量
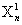 :第一次试验的数据中的第n个测量量
:第一次试验的数据中的第n个测量量
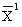 :第一次试验中所有n个测量量的平均值
:第一次试验中所有n个测量量的平均值
参数仅是对于总体而言的真值,而统计量完全由样本中的随机变量计算出来与参数无关,所以只能用统计量来进行参数估计和假设检验,而不能确定真实的参数值,所以统计量也是随机变量。具体而言,就是每次实验都会得到一个统计量的值作为参数的估计值,有可能回回都不一样。
为了准确描述统计量的特征,研究人员通过对统计量的数学运算,提取了(或者也放大了)统计量的某些特征。
想要得到统计量的集中区域特征,可以使用:算术平均数,但易受极端值影响,加权平均数可以减轻极端值的影响;中位数需要排序得到,但是不宜进行代数运算和统计推断,因为统计推断也需要能运算的值。众数对观察值个数和值的变化不敏感,所以它与其他统计量组合使用;几何平均数;调和平均数
要想评估统计量的分散长度,可以使用:极差明确了数据范围;方差是所有数据偏离均值的程度的均值,放大了微小的分散程度,便有判断;样本方差;总体方差;标准差;变异系数可以用于方差相同均值不同的数
为了得到统计量的不同位置的值,可以使用:平均数&众数可以得到中心位置的值;四分位数
为了从数值角度描述分布形态(而非图形角度),可以使用:峰度表现正态分布“山峰”的尖锐程度(eg值>0表明山峰比标准正态分布尖锐)
为了从数值角度描述偏离程度(而非图形角度),可以使用:偏度表现正态分布“山峰”的偏离程度(eg左,表明均值在峰值的左边)
有了描述统计,才能看出了其分布,才能依据分布推断总体,而不是用单一数值去推断总体
再次强调实验过程:收集数据主要依靠物理实验,利用描述统计工具完成整理阶段(数据实验),利用预测统计工具完成分析阶段(实验),最后的生物学解释取决于对生物学课题的熟悉程度。在实验开始之前拿小样本做估计是必要的,即便是小样本也或多或少反映了一些基本情况。

