🔥 面试必备:高频算法题汇总「图文解析 + 教学视频 + 范例代码」必知必会 排序 + 二叉树 部分!🔥

排序
所谓排序算法,即通过特定的算法因式将一组或多组数据按照既定模式进行重新排序。这种新序列遵循着一定的规则,体现出一定的规律,因此,经处理后的数据便于筛选和计算,大大提高了计算效率。
对于排序:
- 我们首先要求其具有一定的稳定性
- 即当两个相同的元素同时出现于某个序列之中
- 则经过一定的排序算法之后
- 两者在排序前后的相对位置不发生变化。
所以,就让我们先来看看,面试中,有哪些超高频的排序算法
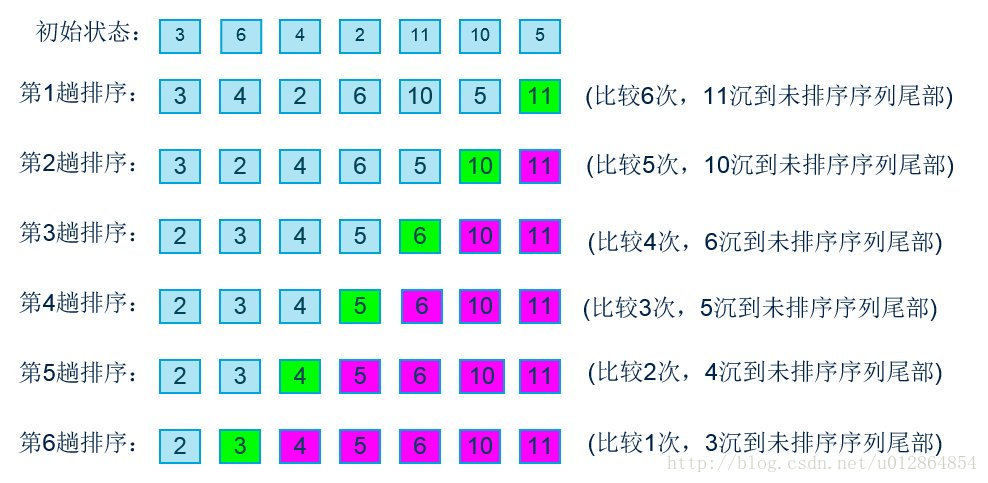
冒泡排序
冒泡排序可以说是最基础的了,无非就是两个 for 循环嵌套,然后两两比较交换罢了。这就不多说了。
步骤:
1、比较相邻的元素。如果第一个比第二个大(小),就交换他们两个。
2、对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大(小)的数。
3、针对所有的元素重复以上的步骤,除了最后已经选出的元素(有序)。
4、持续每次对越来越少的元素(无序元素)重复上面的步骤,直到没有任何
视频:
示例代码:
public void bubbleSort(int[] arr) {
int temp = 0;
boolean swap;
for (int i = arr.length - 1; i > 0; i--) { // 每次需要排序的长度
// 增加一个swap的标志,当前一轮没有进行交换时,说明数组已经有序
swap = false;
for (int j = 0; j < i; j++) { // 从第一个元素到第i个元素
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swap = true;
}
}
if (!swap){
break;
}
}
}
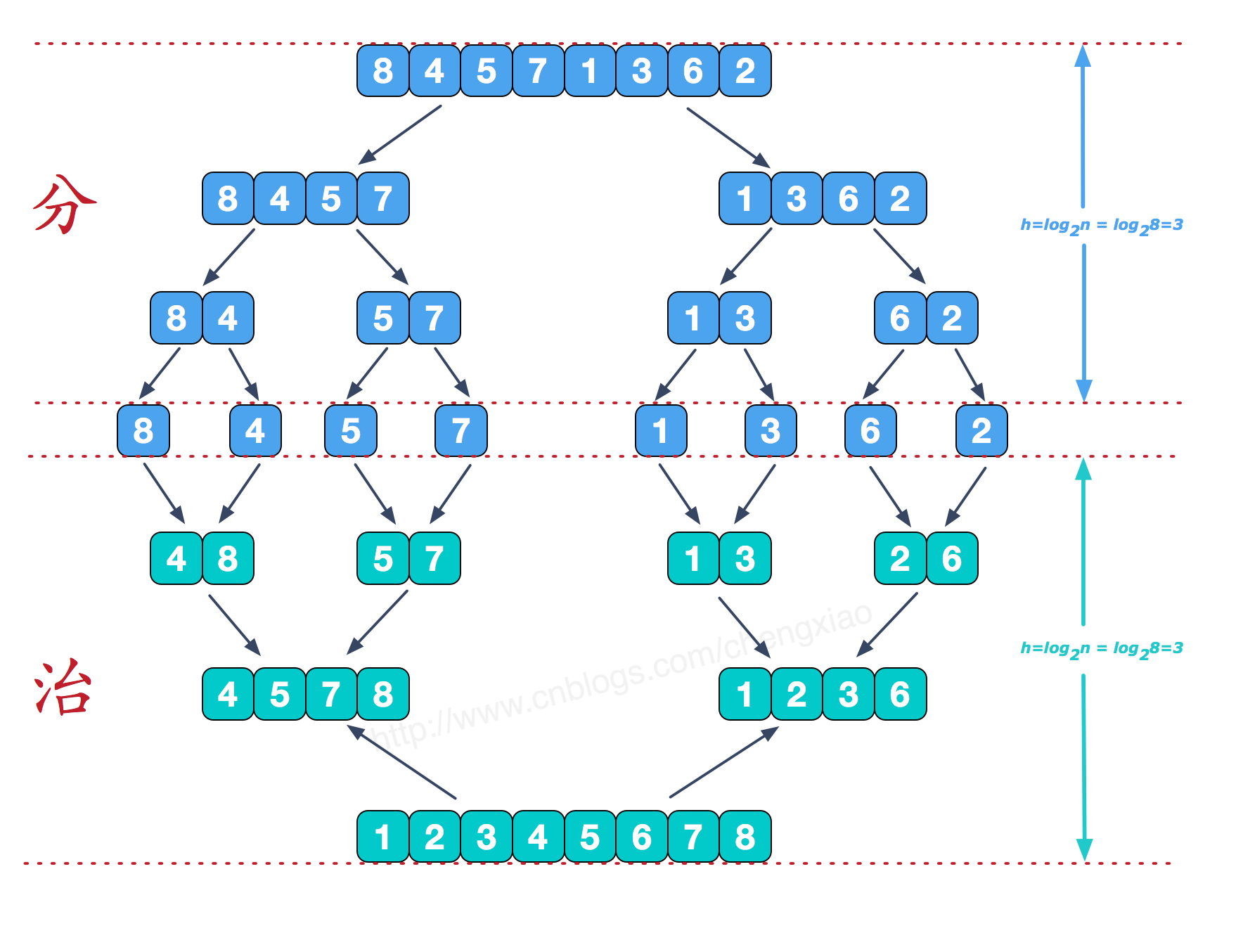
归并排序
对于归并排序而言,思想可以概括为:分而治之。也就是将一个数组,首先划分为一堆单个的数,然后再一个接一个的,进行两两有序合并,最后就得到了一个有序数组。
步骤:
-
将待排序的数列分成若干个长度为1的子数列
-
然后将这些数列两两合并;得到若干个长度为2的有序数列
-
再将这些数列两两合并;得到若干个长度为4的有序数列
-
再将它们两两合并;直接合并成一个数列为止
-
这样就得到了我们想要的排序结果
视频:
示例代码:
// 入口
public void mergeSort(int[] arr) {
int[] temp = new int[arr.length];
internalMergeSort(arr, temp, 0, arr.length - 1);
}
private void internalMergeSort(int[] arr, int[] temp, int left, int right) {
// 当left == right时,不需要再划分
if (left < right) {
int mid = (left + right) / 2;
// 左右往下拆分
internalMergeSort(arr, temp, left, mid);
internalMergeSort(arr, temp, mid + 1, right);
// 拆分结束后返回结果进行合并
mergeSortedArray(arr, temp, left, mid, right);
}
}
// 合并两个有序子序列
public void mergeSortedArray(int[] arr, int[] temp, int left, int mid, int right) {
int i = left;
int j = mid + 1;
int k = 0;
while (i <= mid && j <= right) {
temp[k++] = arr[i] < arr[j] ? arr[i++] : arr[j++];
}
// 合并完,将非空的那列拼入
while (i <= mid) {
temp[k++] = arr[i++];
}
while (j <= right) {
temp[k++] = arr[j++];
}
// 把temp数据复制回原数组
for (i = 0; i < k; i++) {
arr[left + i] = temp[i];
}
}
快速排序
快速排序的思想,可以简单的概括为:两边包抄、一次一个。每选一个基准点,一次排序后确定它的最终位置,一步到位。
步骤:
1、先从数列中取出一个数作为基准数
2、分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边
3、再对左右区间重复第二步,直到各区间只有一个数
概括来说为 挖坑填数+分治法
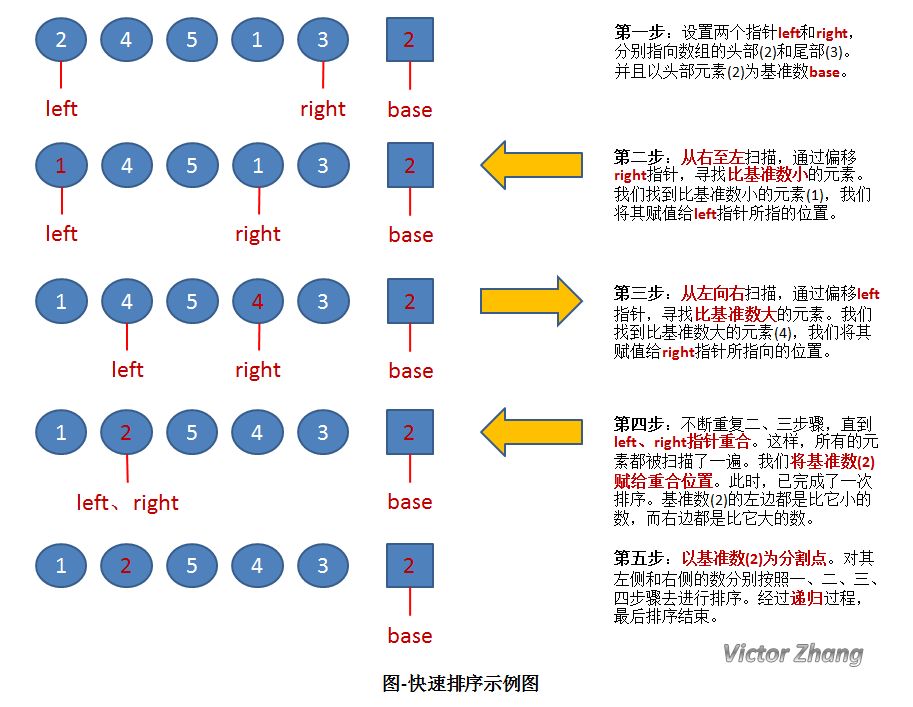
注: 快排算法不唯一,到目前为止我已经看到三种排法,这里我用最老的,就是很多教材上的排法解析
视频:
示例代码:
public void quickSort(int[] arr){
quickSort(arr, 0, arr.length-1);
}
private void quickSort(int[] arr, int low, int high){
if (low >= high)
return;
int pivot = partition(arr, low, high); //将数组分为两部分
quickSort(arr, low, pivot - 1); //递归排序左子数组
quickSort(arr, pivot + 1, high); //递归排序右子数组
}
private int partition(int[] arr, int low, int high){
int pivot = arr[low]; //基准
while (low < high){
while (low < high && arr[high] >= pivot) {
high--;
}
arr[low] = arr[high]; //交换比基准大的记录到左端
while (low < high && arr[low] <= pivot) {
low++;
}
arr[high] = arr[low]; //交换比基准小的记录到右端
}
//扫描完成,基准到位
arr[low] = pivot;
//返回的是基准的位置
return low;
}
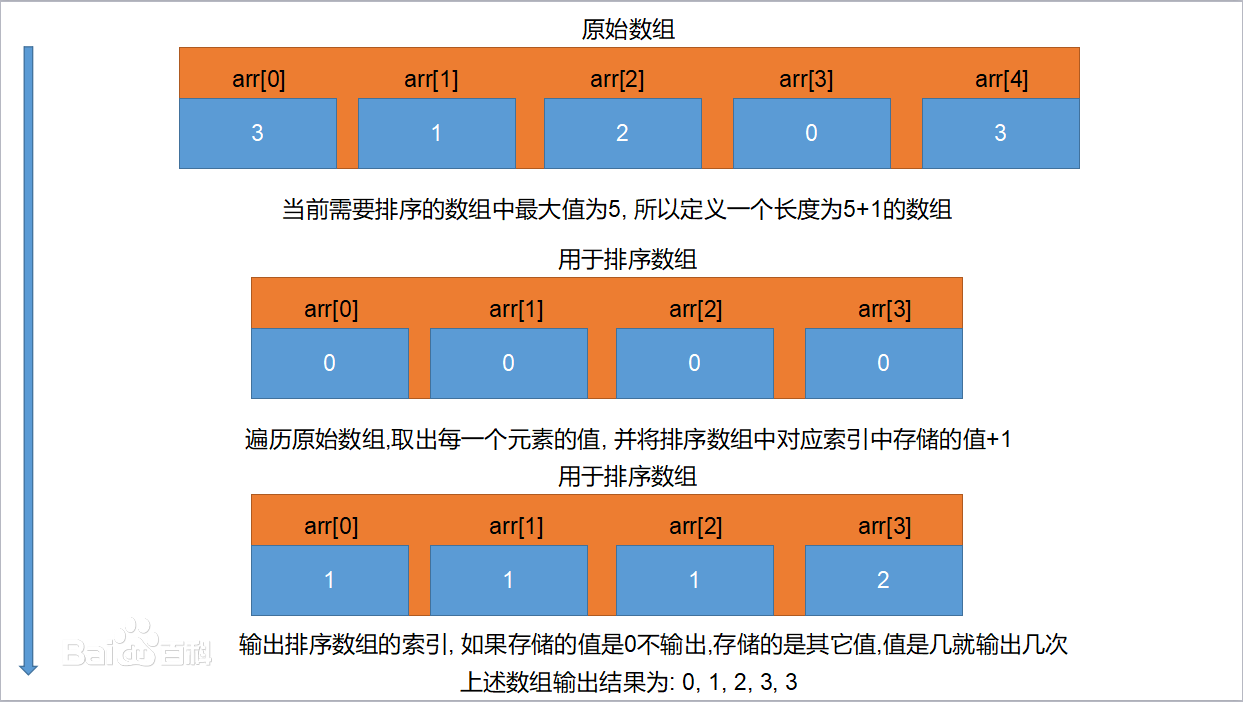
计数排序
计数排序顾名思义,其思想就在于记录各个数的出现次数,最后按顺序取出即可。
步骤:
-
建一个长度为K+1的的数组C,里面的每一个元素初始都置为0(Java里面默认就是0)。
-
遍历待排序的数组,计算其中的每一个元素出现的次数,比如一个key为i的元素出现了3次,那么C[i]=3。
-
累加C数组,获得元素的排位,从0开始遍历C, C[i+1]=C[i]+C[i-1]
-
建一个临时数组T,长度与待排序数组一样。从数组末尾遍历待排序数组,把元素都安排到T里面,直接从C里面就可以得到元素的具体位置, 不过记得每处理过一个元素之后都要把C里面对应位置的计数减1。
视频:
示例代码:
我在网上看了巨多代码,但基本都是用来处理 0 以上数的计数排序。下面介绍的这个算法,可以适应小于 0 的数的计数排序,不过我加了很多注释,也很好理解:
public void countSort(int[] arr) {
// 找到最大值和最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
int[] b = new int[arr.length]; // 存储数组
int[] count = new int[max - min + 1]; // 计数数组
for (int num = min; num <= max; num++) {
// 初始化各元素值为0,数组下标从0开始因此减min
count[num - min] = 0;
}
for (int i = 0; i < arr.length; i++) {
int num = arr[i];
count[num - min]++; // 每出现一个值,计数数组对应元素的值+1
// 此时count[i]表示数值等于i的元素的个数
}
for (int i = min + 1; i <= max; i++) {
count[i - min] += count[i - min - 1];
// 此时count[i]表示数值<=i的元素的个数
// 这样做的目的是为了方便最后赋值,
// 「从下个方法的 ‘count[num - min]--’ 可以看出」
}
for (int i = 0; i < arr.length; i++) {
int num = arr[i]; // 原数组第i位的值
int index = count[num - min] - 1; //加总数组中对应元素的下标
b[index] = num; // 将该值存入存储数组对应下标中
count[num - min]--; // 加总数组中,该值的总和减少1。
}
// 将存储数组的值替换给原数组
for(int i=0; i < arr.length;i++){
arr[i] = b[i];
}
}
桶排序
桶排序的思想是,首先按特定规则,划分出若干个’桶‘,每个‘桶’有个范围,将大小在对应‘桶’范围内的数,对号入座。再依次将每个‘桶’内的数有序排列,最后按顺序拼接各个‘桶’即可。
步骤:
- 根据待排序集合中最大元素和最小元素的差值范围和映射规则,确定申请的桶个数;
- 遍历待排序集合,将每一个元素移动到对应的桶中;
- 对每一个桶中元素进行排序,并移动到已排序集合中。
步骤 3 中提到的已排序集合,和步骤 1、2 中的待排序集合是同一个集合。与计数排序不同,桶排序的步骤 2 完成之后,所有元素都处于桶中,并且对桶中元素排序后,移动元素过程中不再依赖原始集合,所以可以将桶中元素移动回原始集合即可。

视频:
示例代码:
上面讲的计数排序其实一定程度上,也可以看作一种特殊的桶排序,同样的,网上桶排序代码大一堆,啥语言都有。但却没有一个解决小于 0 数排序问题的,要么就不处理要么就抛出异常,下面这个算法,有效的解决了,小于 0 数排序的难题
public static void bucketSort(int[] arr){
// 首先还是找出最大、最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < arr.length; i++){
max = Math.max(max, arr[i]);
min = Math.min(min, arr[i]);
}
// 桶数
// 在桶排序中,对桶的划分个数是随意的
// 这个方法划分的桶数量随带划分数列的密集程度改变而改变
int bucketNum = (max - min) / arr.length + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);
// 初始化各个桶
for(int i = 0; i < bucketNum; i++){
bucketArr.add(new ArrayList<Integer>());
}
// 将每个元素放入相应的桶
for(int i = 0; i < arr.length; i++){
int num = (arr[i] - min) / (arr.length);
bucketArr.get(num).add(arr[i]);
}
// 对每个桶进行排序
for(int i = 0; i < bucketArr.size(); i++){
Collections.sort(bucketArr.get(i));
for (int j = 0; j < bucketArr.get(i).size(); j++) {
arr[j] = bucketArr.get(i).get(j);
}
}
}
二叉树
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
这里就我们就来看看,面试中会怎么样来考察我们有关二叉树的问题,首先我们先定义一个节点类:
后文测试所使用的节点类如下:
ps:解释LeetCode上那种class TreeNode { public TreeNode left, right; public int val; public TreeNode(int val) { this.val = val; } }
顺序遍历
二叉树的遍历分为以下三种:
-
先序遍历:遍历顺序规则为【根左右】
-
中序遍历:遍历顺序规则为【左根右】
-
后序遍历:遍历顺序规则为【左右根】
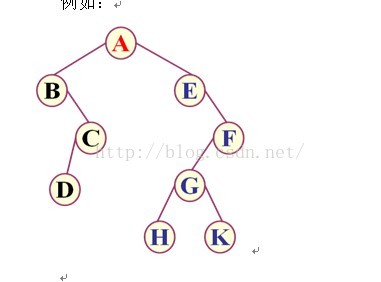
下面以上图为例,我们通过代码实现三种基本遍历:
先序遍历:
首先是代码实现:
// 先序遍历
public void preTraverse(TreeNode root) {
if (root != null) {
System.out.println(root.val);
preTraverse(root.left);
preTraverse(root.right);
}
}
遍历结果:ABCDEFGHK
中序遍历:
首先是代码实现:
// 中序遍历
public void inTraverse(TreeNode root) {
if (root != null) {
inTraverse(root.left);
System.out.println(root.val);
inTraverse(root.right);
}
}
遍历结果:BDCAEHGKF
后序遍历:
首先是代码实现:
// 后序遍历
public void postTraverse(TreeNode root) {
if (root != null) {
postTraverse(root.left);
postTraverse(root.right);
System.out.println(root.val);
}
}
遍历结果:DCBHKGFEA
视频
层次遍历
二叉树的层次遍历很好理解,在这里我举个例子。首先我们先给出一棵二叉树:
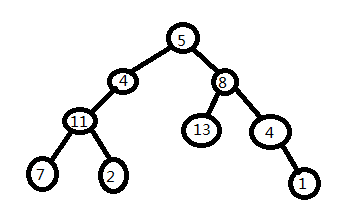
层次遍历顾名思义,就是从上到下,逐层遍历,每层从左往右输出
计算结果:5 - 4 - 8 - 11 - 13 - 4 - 7 - 2 - 1
关于遍历算法,常见的有:
- 深度优先遍历(DFS)
- 广度优先遍历(BFS)
在我刷题的过程中遇到过这样一道题:
Given a binary tree, return the zigzag level order traversal of its nodes’ values. (ie, from left to right, then right to left for the next level and alternate between).即 Z 字型遍历,所以这里再加上一种:
- Z 字形遍历
下面我们来看看代码上的实现:
深度优先遍历(DFS)
我们所学的层次遍历只有 BFS(广搜),DFS 深搜本身是用于顺序排序的非递归实现。‘用DFS’ 来解决层次遍历这种题我也是第一次见。
它的步骤可以简要概括为:
-
常规深度搜索,记录下当前节点所在层 level
-
将当前节点加入 List 中对应的层
-
由于是从左往右搜索,所以也是从左往右加入
-
最后得到一个类似下面的结构
0 -- 5
1 -- 4 -> 8
2 -- 11 -> 13 - > 4
3 -- 7 -> 2 -> 1
这种遍历方式太少见,找不到相关的视频,好在原理容易理解
// 层次遍历(DFS)
public static List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null) {
return res;
}
dfs(root, res, 0);
return res;
}
private void dfs(TreeNode root, List<List<Integer>> res, int level) {
if (root == null) {
return;
}
if (level == res.size()) {
res.add(new ArrayList<>());
}
res.get(level).add(root.val);
dfs(root.left, res, level + 1);
dfs(root.right, res, level + 1);
}
广度优先遍历(BFS)
与 DFS 用递归去实现不同,BFS需要用队列去实现。
层次遍历的步骤是:
-
对于不为空的结点,先把该结点加入到队列中
-
从队中拿出结点,如果该结点的左右结点不为空,就分别把左右结点加入到队列中
-
重复以上操作直到队列为空
说白了就是:
父节点入队,父节点出队列,先左子节点入队,后右子节点入队。递归遍历全部节点即可
视频
public List<List<Integer>> levelOrder(TreeNode root) {
List result = new ArrayList();
if (root == null) {
return result;
}
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.offer(root);
while (!queue.isEmpty()) {
ArrayList<Integer> level = new ArrayList<Integer>();
int size = queue.size();
for (int i = 0; i < size; i++) {
TreeNode head = queue.poll();
level.add(head.val);
if (head.left != null) {
queue.offer(head.left);
}
if (head.right != null) {
queue.offer(head.right);
}
}
result.add(level);
}
return result;
}
Z 字形遍历
这个题型也很罕见,源于 LeetCode 上一道面试原题:
Given a binary tree, return the zigzag level order traversal of its nodes’ values. (ie, from left to right, then right to left for the next level and alternate between).给定一棵二叉树,从顶向下,进行Z字形分层遍历,即:如果本层是从左向右的,下层就是从右向左。
流程与 BFS 类似,就是多了个用于区分左右的 flag
-
对于不为空的结点,先把该结点加入到队列中
-
从队中拿出结点,如果该结点的左右结点不为空,就分别把左右结点加入到队列中
-
将 isFromLeft 值取反
-
重复以上操作直到队列为空
视频
同样的这个体型太特殊,所以没有相关视频解析,不过好在算法过程也很好理解
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null){
return result;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
boolean isFromLeft = false;
while(!queue.isEmpty()){
int size = queue.size();
isFromLeft = !isFromLeft;
List<Integer> list = new ArrayList<>();
for(int i = 0; i < size; i++){
TreeNode node;
if (isFromLeft){
node = queue.pollFirst();
}else{
node = queue.pollLast();
}
list.add(node.val);
if (isFromLeft){
if (node.left != null){
queue.offerLast(node.left);
}
if (node.right != null){
queue.offerLast(node.right);
}
}else{
if (node.right != null){
queue.offerFirst(node.right);
}
if (node.left != null){
queue.offerFirst(node.left);
}
}
}
result.add(list);
}
return result;
}
左右翻转
这是一道华为面试原题,题目大意是:
输入二叉树如下:
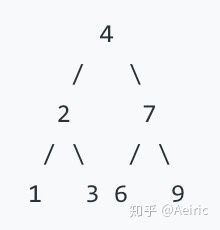
反转后输出:
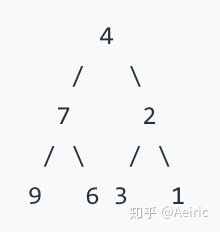
乍一看很难办,其实想一个解决方案很简单,这里我直接举三个方案:
方法一:比如我们用递归的思路,本质思想是:
-
本质思想也是左右节点进行交换
-
交换前递归调用对根结点的左右节点分别进行处理
-
保证交换前左右节点已经翻转。
三步搞定,我们看下代码实现:
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while(!stack.isEmpty()) {
final TreeNode node = stack.pop();
final TreeNode left = node.left;
node.left = node.right;
node.right = left;
if(node.left != null) {
stack.push(node.left);
}
if(node.right != null) {
stack.push(node.right);
}
}
return root;
}
方法二:循环,队列存储(BFS,非递归)
本质思想是:
-
左右节点进行交换
-
循环翻转每个节点的左右子节点
-
将未翻转的子节点存入队列中
-
循环直到栈里所有节点都循环交换完为止。
public TreeNode invertTree(TreeNode root) {
if (root == null) {
return null;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
TreeNode left = node.left;
node.left = node.right;
node.right = left;
if (node.left != null) {
queue.offer(node.left);
}
if (node.right != null) {
queue.offer(node.right);
}
}
return root;
}
方法三:「压轴出场,三步秒杀」递归
本质思想是:
-
左右节点进行交换
-
交换前递归调用对根结点的左右节点分别进行处理
-
保证交换前左右节点已经翻转。
同样三步搞定,我们看下代码:
public void invert(TreeNode root) {
if (root == null) {
return;
}
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
invert(root.left);
invert(root.right);
}
最大值
乍一看,是到送分题。我第一眼的想法就是:在方法中定义max用来保存遍历得到的最大值,结果每次递归时,都等于在重新定义max,这种方法不对。所以怎么办?
-
采用分治思想
-
从整棵树的底部开始
-
两两比较,放回最大值
看一眼算法你就懂了
public int getMax(TreeNode root) {
if (root == null) {
return Integer.MIN_VALUE;
} else {
int left = getMax(root.left);
int right = getMax(root.right);
return Math.max(Math.max(left, rigth), root.val);
}
}
最大深度
深度问题和最大值一样,容易想复杂,其实非常简单,也可以看作一种分治的思想
-
二叉树的最大深度是距根节点路径最长的某一树叶节点的深度。
-
二叉树的深度等于二叉树的高度,也就等于根节点的高度。根节点的高度为左右子树的高度较大者+1。
视频
public int maxDepth(TreeNode root) {
if (root == null) {
return 0;
}
int left = maxDepth(root.left);
int right = maxDepth(root.right);
return Math.max(left, right) + 1;
}
最小深度
这道题目太常见了,当我一看到题目时就错了:
题目:最小深度是从根节点到最近
叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
看到了吧,这时就得明确正确的递归结束条件
举个例子:
很多人写出的代码都不符合 1,2 这个测试用例,是因为没搞清楚题意
题目中说明: 叶子节点是指没有子节点的节点,这句话的意思是 1 不是叶子节点
题目问的是到叶子节点的最短距离,所以所有返回结果为 1 当然不是这个结果
另外这道题的关键是搞清楚递归结束条件
- 叶子节点的定义是左孩子和右孩子都为 null 时叫做叶子节点
- 当 root 节点左右孩子都为空时,返回 1
- 当 root 节点左右孩子有一个为空时,返回不为空的孩子节点的深度
- 当 root 节点左右孩子都不为空时,返回左右孩子较小深度的节点值
视频
public int minDepth(TreeNode root) {
if (root == null) {
return 0;
}
int left = minDepth(root.left);
int right = minDepth(root.right);
if (left == 0) {
return right + 1;
} else if (right == 0) {
return left + 1;
} else {
return Math.min(left, right) + 1;
}
}
平衡二叉树
概念:平衡二叉树每一个节点的左右两个子树的高度差不超过 1
-
设一个 flag
-
如果发现不平衡则就返回非 flag
视频
public boolean isBalanced(TreeNode root) {
return maxDepth(root) != -1;
}
private int maxDepth(TreeNode root) {
if (root == null) {
return 0;
}
int left = maxDepth(root.left);
int right = maxDepth(root.right);
if (left == -1 || right == -1 || Math.abs(left - right) > 1) {
return -1;
}
return Math.max(left, right) + 1;
}
Attention
为了提高文章质量,防止冗长乏味
下一部分算法题
-
本片文章篇幅总结越长。我一直觉得,一片过长的文章,就像一场超长的 会议/课堂,体验很不好,所以打算再开一篇文章来总结其余的考点
-
在后续文章中,我将继续针对
链表栈队列堆动态规划矩阵位运算等近百种,面试高频算法题,及其图文解析 + 教学视频 + 范例代码,进行深入剖析有兴趣可以继续关注 _yuanhao 的编程世界
相关文章
每个人都要学的图片压缩终极奥义,有效解决 Android 程序 OOM
Android 让你的 Room 搭上 RxJava 的顺风车 从重复的代码中解脱出来
ViewModel 和 ViewModelProvider.Factory:ViewModel 的创建者
单例模式-全局可用的 context 对象,这一篇就够了
缩放手势 ScaleGestureDetector 源码解析,这一篇就够了
Android 属性动画框架 ObjectAnimator、ValueAnimator ,这一篇就够了
看完这篇再不会 View 的动画框架,我跪搓衣板
看完这篇还不会 GestureDetector 手势检测,我跪搓衣板!
android 自定义控件之-绘制钟表盘
Android 进阶自定义 ViewGroup 自定义布局
欢迎关注_yuanhao的博客园!
为了方便大家跟进学习,我在 GitHub 建立了一个仓库
仓库地址:超级干货!精心归纳视频、归类、总结,各位路过的老铁支持一下!给个 Star !

