Hadoop集群搭建前的大数据环境配置
Hadoop集群安装配置教程
1.大数据环境配置统一
当Hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。这时,数据就可以分布到多个节点上,不同数据节点上的数据计算可以并行执行,这时的MapReduce分布式计算能力才能真正发挥作用。
为了降低分布式模式部署难度,本教程简单使用三个节点来搭建集群环境。
首先进行虚拟机克隆
1)使用VMware加载资料中虚拟机node1
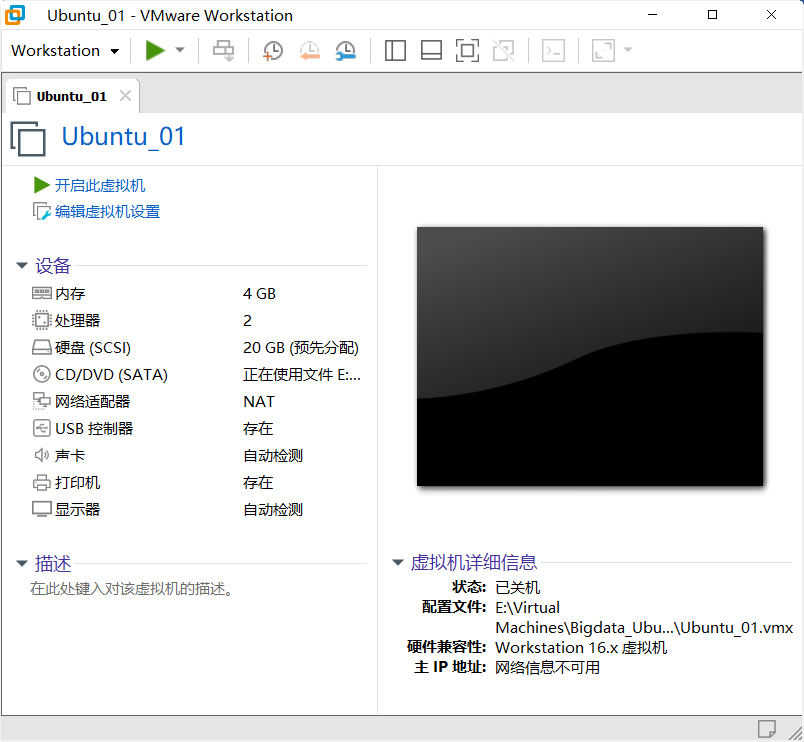
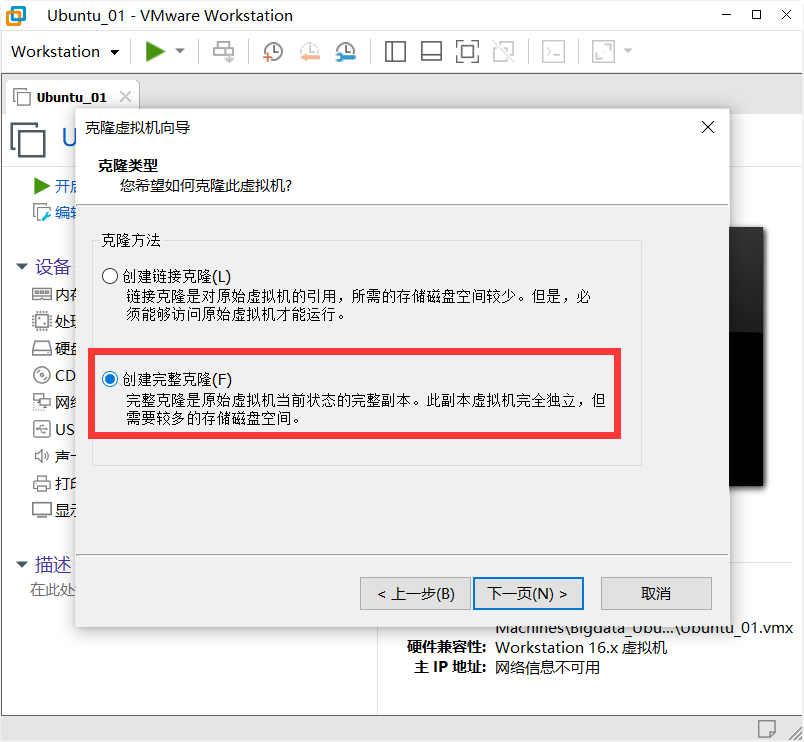
2)克隆虚拟机,注意克隆虚拟机的时候,虚拟机必须是关闭状态
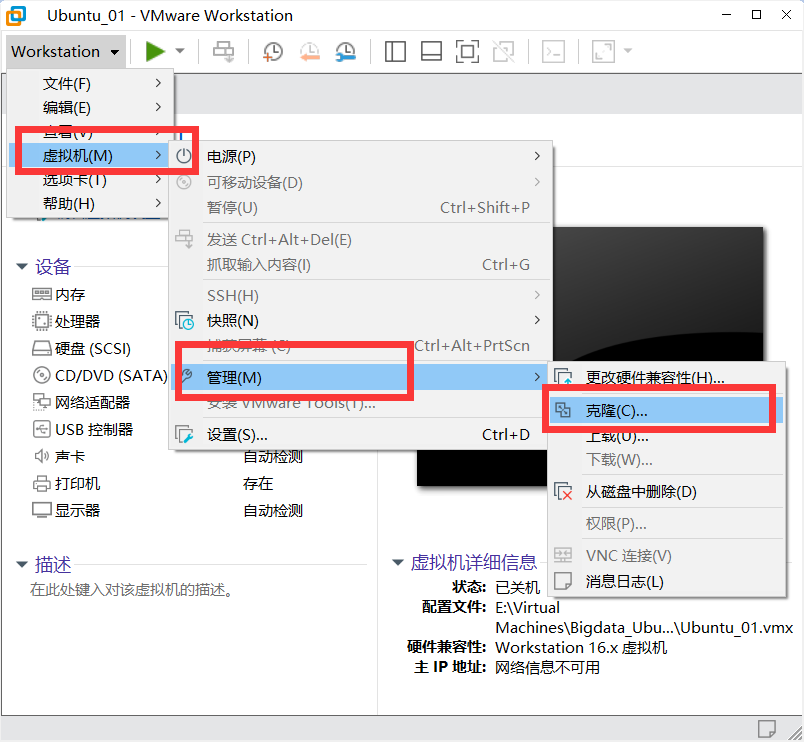
下一步
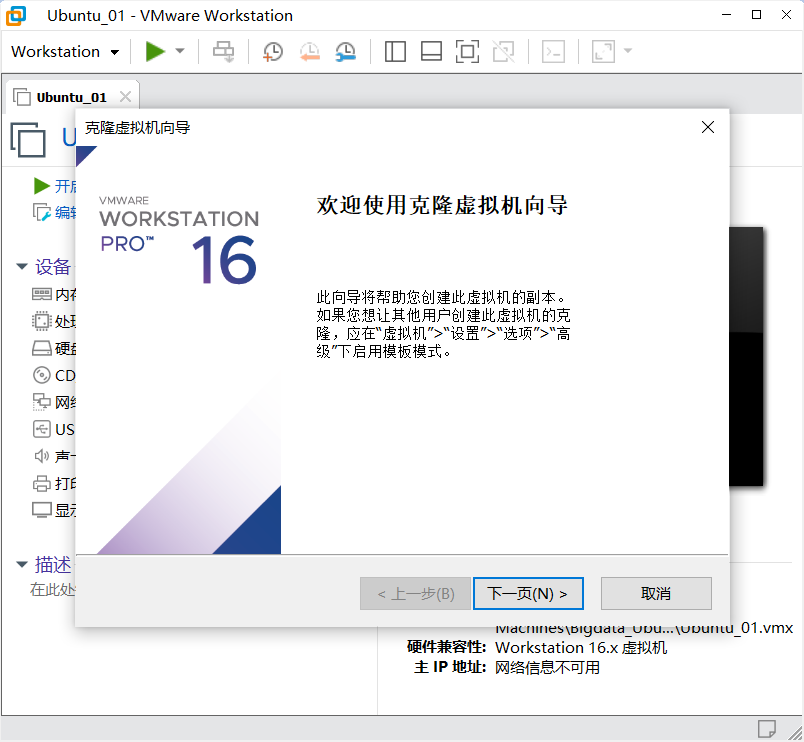
下一步
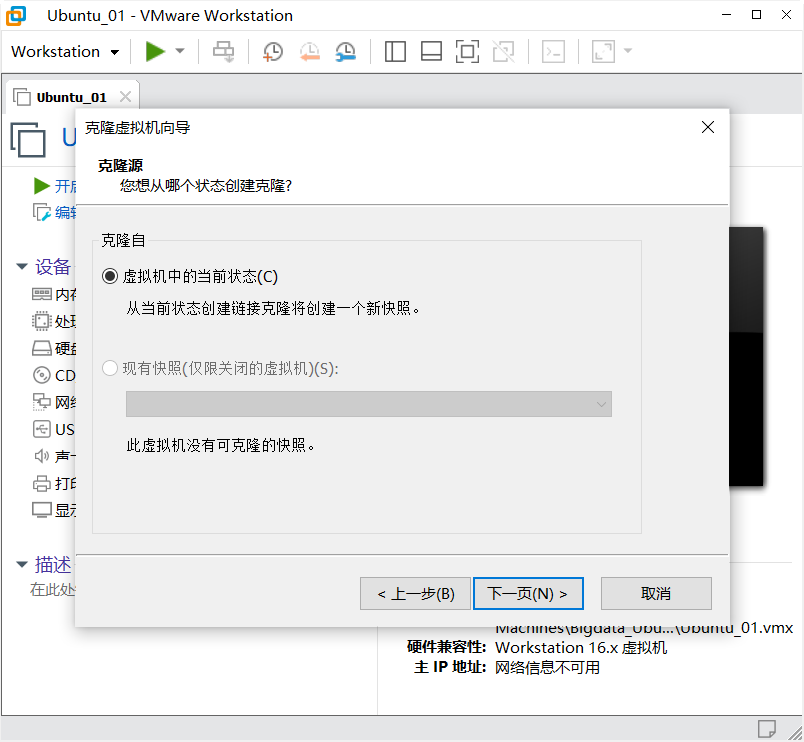
创建完整克隆
完成

虚拟机三重复以上操作
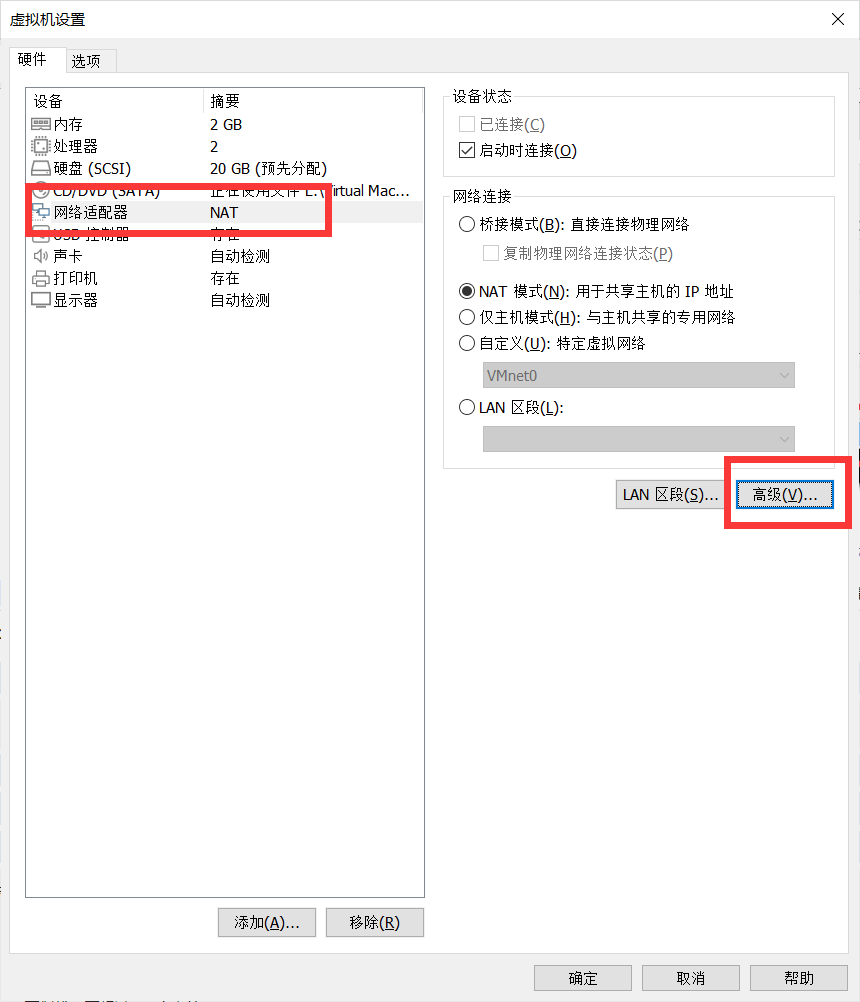
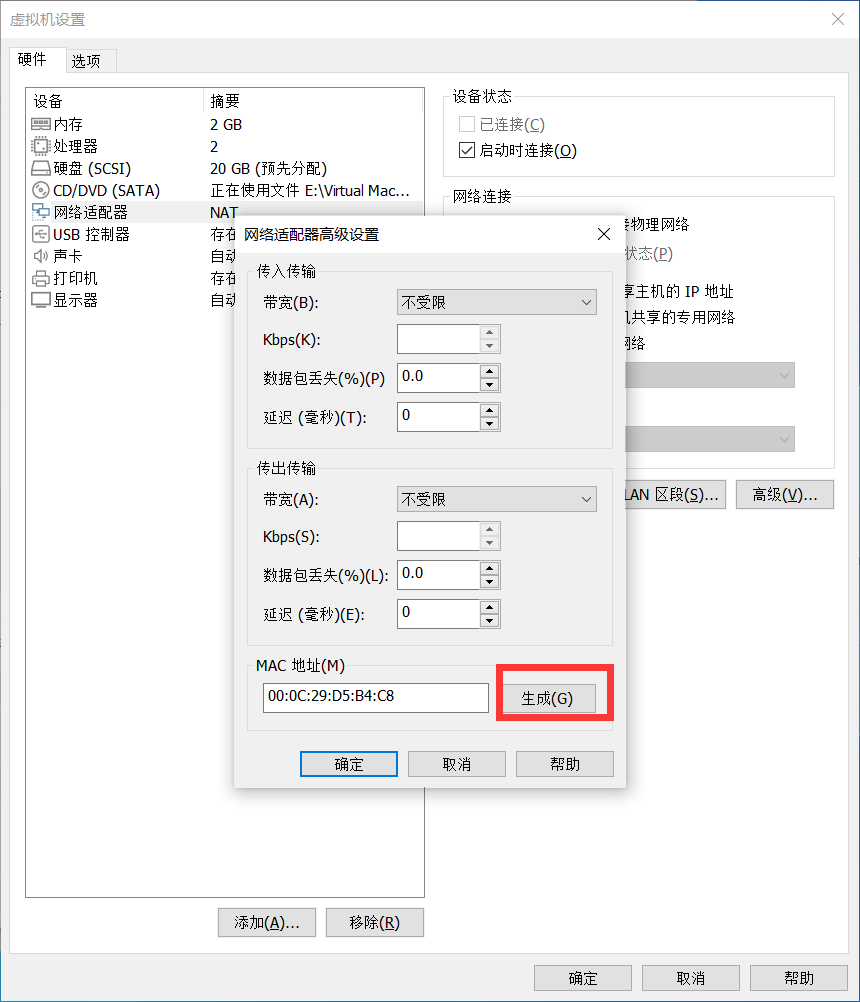
配置MAC地址
Slave1和Slave2都是从Master克隆过来的,他们的MAC地址都一样,所以需要让Slave1和Slave2重新生成MAC地址,生成方式如下:
生成新的MAC地址
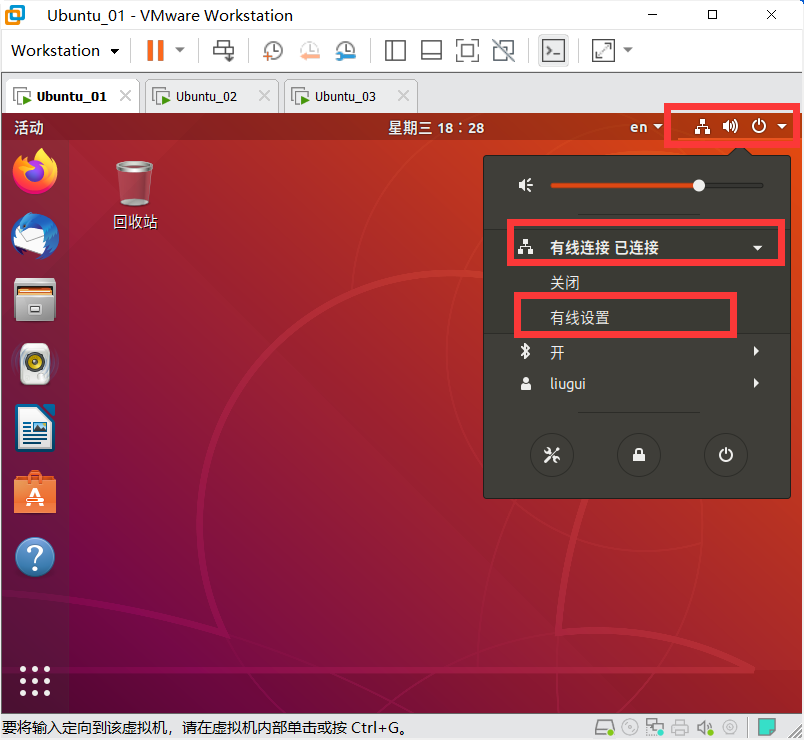
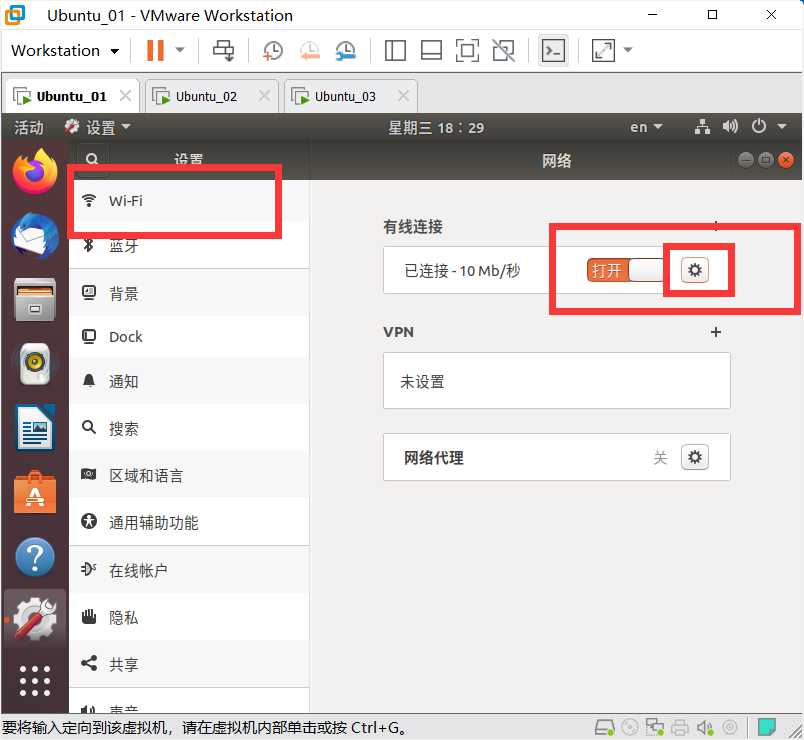
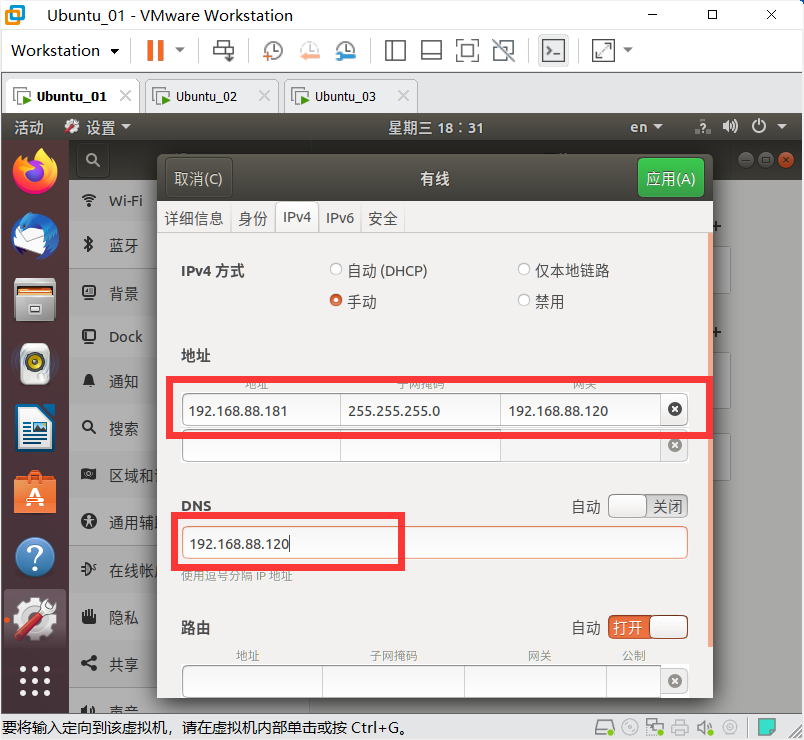
配置IP地址
设置静态网络
Master,IP地址为192.168.88.181
Slave1,IP地址为192.168.88.182
Slave2,IP地址为192.168.88.183
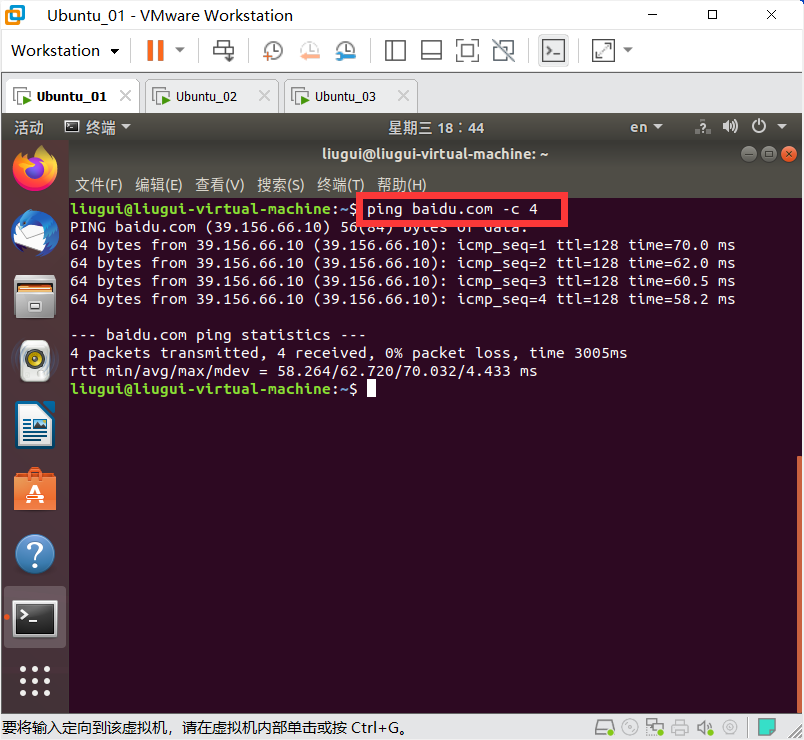
测试网络
ping baidu.com -c 4
修改三台机器之间的映射
1、配置每台虚拟机主机名:
分别编辑每台虚拟机的hostname文件,直接填写主机名,保存退出即可。
sudo vim /etc/hostname
第一台主机主机名为: Master.itcast.cn
第二台主机主机名为: Slave1.itcast.cn
第三台主机主机名为: Slave2.itcast.cn
2、配置每台虚拟机域名映射
分别编辑每台虚拟机的hosts文件:
三台虚拟机的配置内容都一样。
sudo vim /etc/hosts
在原有内容的基础上,填下以下内容:
192.168.88.161 node1 node1.itcast.cn
192.168.88.162 node2 node2.itcast.cn
192.168.88.163 node3 node3.itcast.cn
在原有内容的基础上,修改以下内容:
在Slave1上修改:
127.0.1.1 Master
修改为:
127.0.1.1 Slave1
在Slave2上修改:
127.0.1.1 Master
修改为:
127.0.1.1 Slave2
三台机器机器免密码登录
三台机器生成公钥与私钥
三台机器执行以下命令:
ssh-keygen
回车三次形成密钥
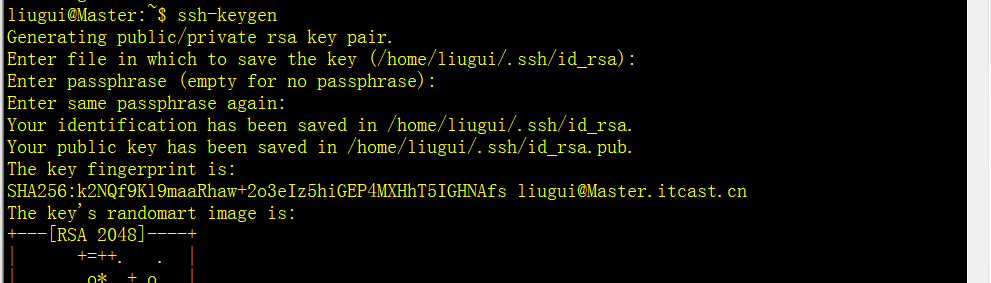
三台机器机器执行以下命令:
ssh-copy-id Master
ssh-copy-id Slave1
ssh-copy-id Slave2
测试SSH免密登录
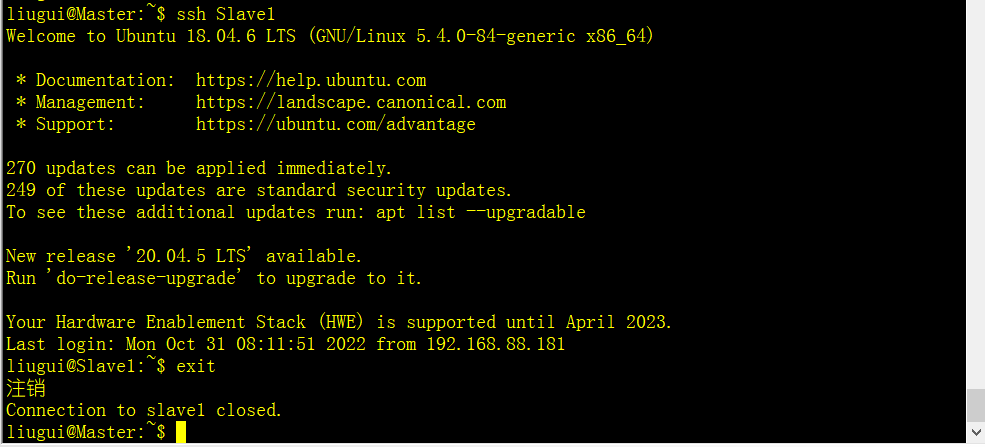
可以在任何一台主机上通过ssh 主机名命令去远程登录到该主机,输入exit退出登录
例如:在Master机器上,免密登录到Slave1机器上
ssh Slave1
exit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号