Java web中常见编码乱码问题(一)
最近在看Java web中中文编码问题,特此记录下。
本文将会介绍常见编码方式和Java web中遇到中文乱码问题的常见解决方法:
一、常见编码方式:
1、ASCII 码
众所周知,这是最简单的编码。它总共可以表示128个字符,0~31是控制字符如换行、回车、删
除等,32~126是打印字符,可以通过键盘输入并且能够显示出来的。
2、ISO-8859-1
它是基于ASCII码基础上扩展的,它总共能表示256个字符,涵盖了大多数西欧语言字符。详见
ISO-8859-1 编码 该编码不支持中文,举个中文编码栗子:
字符串“I am 君山”用 ISO-8859-1 编码,下面是编码结果:
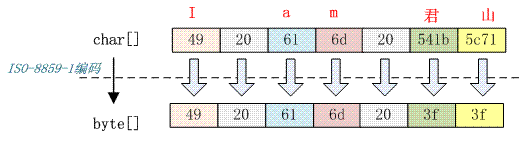
由于ISO-8859-1 是单字节编码且不支持中文,直接将中文字符转成‘3f’, 3f也就是常见的"?"字符
3、GB2312
它是双字节编码,共包含6763个汉字。
4、GBK
汉字内码扩展规范,是基于GB2312上拓展的,加入了更多的汉字,能表示21003个汉字。它的编码
是和GB2312兼容的。也就是说用GB2312编码的汉字可以用GBK来解码,并且不会乱码。倒过来就不完
全可以了,因为GB2312描述的汉字比GBK少。
5、UTF-16
UTF-16是基于Unicode上定义的, 用两个字节来表示Unicode的转换格式,它采用定长的表示方法,
即不能什么字符都可以用两个字节表示。两个字节是16个bit,所以就做UTF-16。(Unicode 囊括了世界
上所有语言,所有语言均可通过Unicode来相互翻译,详解 Unicode 编码)
6、UTF-8
由于UTF-16统一采用两个字节来表示一个字符, 有很多字符用一个字节表示即可。所以存储空间放
大了一倍,还会增加网络传输的流量,所以推出了UTF-8。 UTF-8采用了一种变长技术,每个编码区域有
不同的字码长度。
通过上面介绍和对比,对于中文字符的处理我想UTF-8是最理想的中文编码。
二、常见乱码问题分析
1、中文变成看不懂的字符
如果一串中文字符变成了一串看不懂的字符如:"Ì Ô £ ¡Î Ò Ï²»¶ £ ¡",这种情况通常是编码
字符集与解码时所用的字符集不一致所造成的。比如使用GBK编码,如果使用ISO-8859-1解码
的话结果就是这样。
2、一个汉字变成了一个问号
如果编码和解码的字符集都是一致的,那么可以确定该字符编码不支持中文,例如:ISO-8859-1
3、一个汉字变成了两个问号
中文经过多次编码且其中有一次编码或者解码使用了不支持中文的字符集
三、常见案例分析(tomct+google)
1、参数传输乱码
背景:从jsp中传参数(包括中文)请求后台数据,在后台获取到的请求参数乱码。
1.1 前端编码设置,先讲解下jsp中编码的配置:
a、其中contentType中charset用来设置服务器发送给客户端时的内容编码;pageEncoding 用
来设置JSP源文件本身和响应正文中的字符编码。通俗的说pageEncoding是jsp文件本身的编码,如果
pageEncoding设置为ISO-8859-1,则jsp页面中不能保存中文字符,会自动提示你是否要设置为UTF-8.
b、jsp文件编码字符集默认为ISO-8859-1, JSP源文件字符集时,优先级为pageEncoding>
contentType。如果都没有设置,默认ISO-8859-1。
c、设置响应输出的字符集时,优先级为contentType>pageEncoding。如果都没有设置,默认
ISO-8859-1。
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
综上所述,解决该问题乱码的第一步要设置jsp中的编码,最好统一为UTF-8。
exmaple(乱码示例):

页面效果如下:

1.2 后端编码设置
a、首先要设置tomcat编码,其中要了解两个参数(conf/server.xml):URIEncoding 和
useBodyEncodingForURI,可以查看官方文档说明:
http://tomcat.apache.org/tomcat-7.0-doc/config/http.html, 以下是我理解:
1)URIEncoding是对所有GET方式的请求的数据进行统一的重新编码,默认编码为
ISO-8859-1(针对URI上的请求参数)
2)useBodyEncodingForURI:此设置仅适用于请求的查询字符串(针对请求体中内容)。
与URIEncoding不同,它不影响请求URI的路径部分。如果不知道请求字符编码(浏览器不提供,
并且SetCharacterEncodingFilter不设置或使用Request.setCharacterEncoding方法的类
似过滤器),默认编码始终为“ISO-8859-1”。URIEncoding设置对此默认值没有影响。
该参数为false。通俗的说:
true表示get和post的编码保持一致,post方式的编码是什么,get方式的编码就是什么。
false表示get和post的字符编码各自设置,互相没有关系。
example1(只设置URIEncoding):
server.xml
<Connector connectionTimeout="20000" port="9080" protocol="HTTP/1.1"
redirectPort="443" URIEncoding="UTF-8" />
controller:
@RequestMapping(value = "/testURI", method=RequestMethod.POST) @ResponseBody public String testURI(HttpServletRequest request){ String username = request.getParameter("username"); String nickname = request.getParameter("nickname"); System.out.println("姓名:" + username + ", 昵称:" + nickname); return "姓名:" + username + ", 性别:" + nickname; }
jsp:
<form action="${pageContext.request.contextPath }/testURI.html?username=张三" method="post">
<input type="text" name="nickname" value="老张三"/>
<input type="submit" value="提交"/>
</form>
输出结果: 姓名:张三, 昵称:èå¼ ä¸
从结果中可以看出, URIEncoding只对URI中的参数进行编码。
example2:只修改controller中代码,就都会显示正常
@RequestMapping(value = "/testURI", method=RequestMethod.POST) @ResponseBody public String testURI(HttpServletRequest request) throws UnsupportedEncodingException{ request.setCharacterEncoding("UTF-8"); String username = request.getParameter("username"); String nickname = request.getParameter("nickname"); System.out.println("姓名:" + username + ", 昵称:" + nickname); return "姓名:" + username + ", 性别:" + nickname; }
其实第二种做法并不是很方便,一般通过设置URIEncoding+encodingFilter即可解决。
example3(通常做法):
web.xml代码如下,其余跟example1一样即可。
<filter> <filter-name>encodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>UTF-8</param-value> </init-param> <init-param> <param-name>forceEncoding</param-name> <param-value>true</param-value> </init-param> </filter> <filter-mapping> <filter-name>encodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
example4:
@RequestMapping(value = "/testURI", method=RequestMethod.POST)
@ResponseBody
public String testURI(HttpServletRequest request) throws UnsupportedEncodingException{
request.setCharacterEncoding("UTF-8");
String username = request.getParameter("username");
String nickname = request.getParameter("nickname");
System.out.println("姓名:" + username + ", 昵称:" + nickname);
return "姓名:" + username + ", 性别:" + nickname;
}
如果只设置URIEncoding=ISO-8859-1,request.setCharacterEncoding("UTF-8");只会
对请求体中的参数进行编码,所以username是乱码的。

example5: 在example4的基础上设置useBodyEncodingForURI="true"
设置useBodyEncodingForURI=true时,就会将请求参数和请求体中的参数根据
request.setCharacterEncoding或者contentType中的字符集编码。

本文先记录至此,参考文献有《深入分析Java web解析》《tomcat docs》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号