Redis做为缓存的几个问题
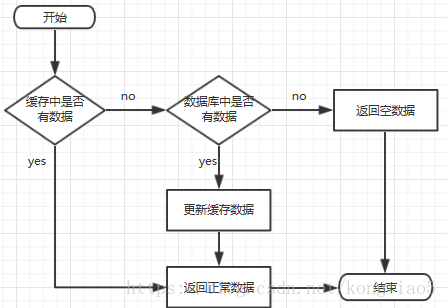
缓存理流程:
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
1.缓存雪崩

解决方案3:如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
解决方案4:设置热点数据永远不过期。
2.缓存穿透
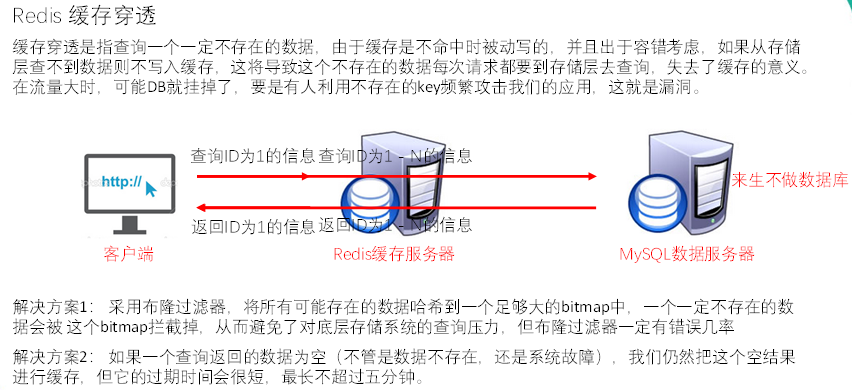
解决方案3:接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
解决方案4:从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。 这样可以防止攻击用户反复用同一个id暴力攻击
3.缓存击穿

解决方案2:设置热点数据永远不过期
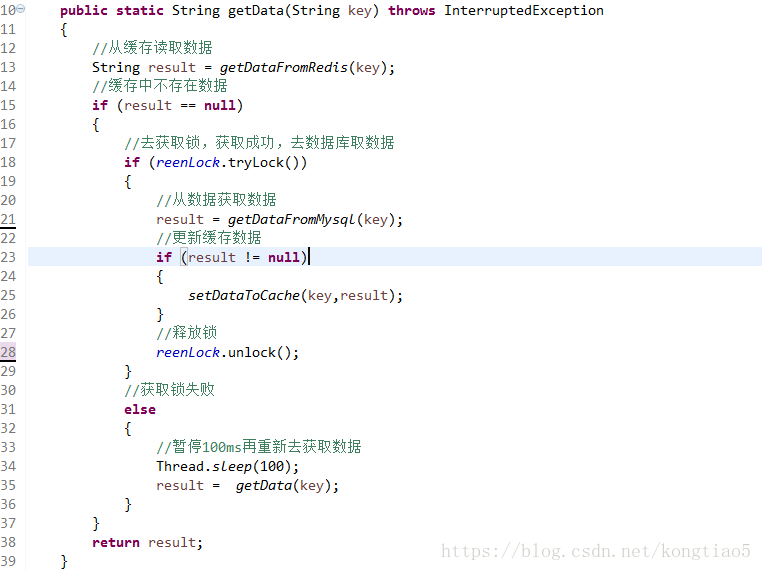
注--------其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家的。所以,务实主义的小编,对主打商品都是早早的做好了准备,让缓存永不过期。即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了。
大道至简,mutex key互斥锁真心用不上。
4.缓存预热
描述:
新的缓存系统没有任何缓存数据,缓存预热就是系统上线后,在缓存重建数据的过程中,系统性能和数据库负载都不太好,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方案
1、数据量不大,可以在项目启动的时候自动进行加载
2、定时刷新缓存
5.缓存热备
描述:
缓存热备即当一台缓存服务器不可用时能实时切换到备用缓存服务器,不影响缓存使用。集群模式下,每个主节点都会有一个或多个从节点来当备用,一旦主节点挂点,从节点立即充当主节点使用。
解决方案:
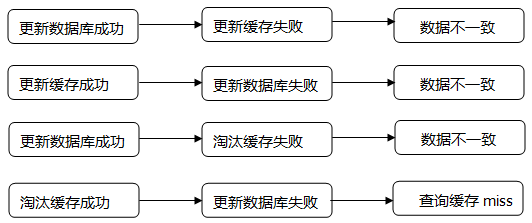
6.缓存一致性问题
当数据时效性要求很高时,需要保证缓存中的数据与数据库中的保持一致,而且需要保证缓存节点和副本中的数据也保持一致,不能出现差异现象。
这就比较依赖缓存的过期和更新策略。一般会在数据发生更改的时,主动更新缓存中的数据或者移除对应的缓存。
7.缓存无底洞问题
该问题由 facebook 的工作人员提出的, facebook 在 2010 年左右,memcached 节点就已经达3000 个,缓存数千 G 内容。
他们发现了一个问题---memcached 连接频率,效率下降了,于是加 memcached 节点,添加了后,发现因为连接频率导致的问题,仍然存在,并没有好转,称之为”无底洞现象”。
目前主流的数据库、缓存、Nosql、搜索中间件等技术栈中,都支持“分片”技术,来满足“高性能、高并发、高可用、可扩展”等要求。有些是在client端通过Hash取模(或一致性Hash)将值映射到不同的实例上,有些是在client端通过范围取值的方式映射的。当然,也有些是在服务端进行的。但是,每一次操作都可能需要和不同节点进行网络通信来完成,实例节点越多,则开销会越大,对性能影响就越大。
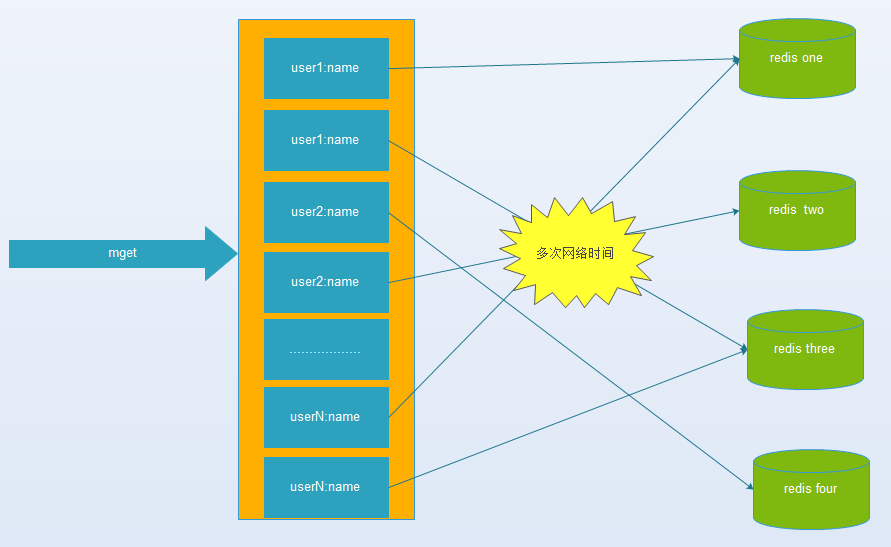
主要可以从如下几个方面避免和优化:
1. 数据分布方式
有些业务数据可能适合Hash分布,而有些业务适合采用范围分布,这样能够从一定程度避免网络IO的开销。
2. IO优化
可以充分利用连接池,NIO等技术来尽可能降低连接开销,增强并发连接能力。
3. 数据访问方式
一次性获取大的数据集,会比分多次去获取小数据集的网络IO开销更小。
当然,缓存无底洞现象并不常见。在绝大多数的公司里可能根本不会遇到。
8.说明
作为一个并发量较大的应用,在使用缓存时有三个目标:
第一,加快用户访问速度,提高用户体验。
第二,降低后端负载,减少潜在的风险,保证系统平稳。
第三,保证数据“尽可能”及时更新。下面将按照这三个维度对上述两种解决方案进行分析。
互斥锁 (mutex key):
这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好的降低后端存储负载并在一致性上做的比较好。
永远不过期
这种方案由于没有设置真正的过期时间,实际上已经不存在热点 key 产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。

