Java 集合框架 03
集合框架·HashSet 和 TreeSet
HashSet存储字符串并遍历
* A:Set集合概述及特点
* 通过API查看即可
* 无索引,不可以重复,无序
* B:案例演示
* HashSet存储字符串并遍历
HashSet<String> hsHashSet = new HashSet<String>(); boolean b1 = hsHashSet.add("a"); boolean b2 = hsHashSet.add("a"); System.out.println(b1); System.out.println(b2);

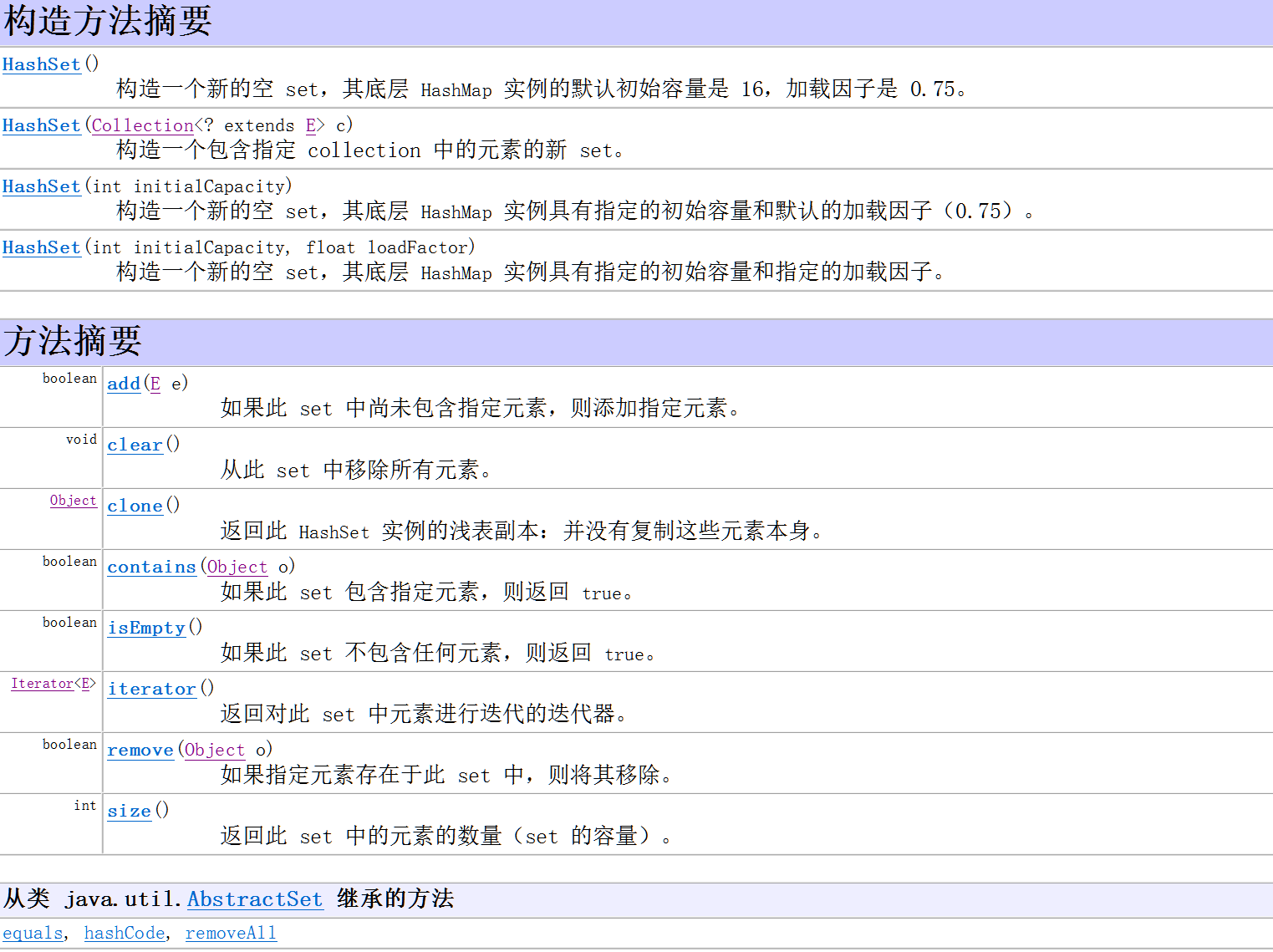



public String toString() { Iterator<E> it = iterator(); if (! it.hasNext()) return "[]"; StringBuilder sb = new StringBuilder(); sb.append('['); for (;;) { E e = it.next(); sb.append(e == this ? "(this Collection)" : e); if (! it.hasNext()) return sb.append(']').toString(); sb.append(',').append(' '); } }
package com.heima.set; import java.util.HashSet; import com.heima.bean.Person; public class Demo1_HashSet { public static void main(String[] args) { // demo1(); } public static void demo1() { HashSet<String> hsHashSet = new HashSet<String>(); // 创建HashSet对象 boolean b1 = hsHashSet.add("a"); boolean b2 = hsHashSet.add("a"); // 当向set集合中存储重复元素时返回false hsHashSet.add("b"); hsHashSet.add("c"); hsHashSet.add("d"); hsHashSet.add("e"); System.out.println(hsHashSet); // HashSet的继承体系中有重写toString方法 System.out.println(b1); // true System.out.println(b2); // false for (String string : hsHashSet) { // 只要能用迭代器迭代的,就可以使用增强for循环遍历 System.out.println(string); } } }
HashSet存储自定义对象保证元素的唯一性
* A:案例演示
* 存储自定义对象,并保证元素的唯一性
HashSet<Person> hs = new HashSet<Person>(); hs.add(new Person("张三", 23));jinke hs.add(new Person("张三", 23)); hs.add(new Person("张三", 23)); hs.add(new Person("李四", 24)); hs.add(new Person("李四", 24)); hs.add(new Person("张三", 23));
* 重写hashCode() 和 equals() 方法
* hashCode() 的重写应尽可能少调用equals() 方法
@Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; }
@Override public boolean equals(Object obj) { if (this == obj) // 调用的和传入的是同一个对象 return true; if (obj == null) // 传入的对象为null,调用的不可能为null return false; if (getClass() != obj.getClass()) // getClass方法返回 字节码文件 return false; Person other = (Person) obj; // 向下转型,保证不会出现强转异常 if (age != other.age) return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; }
package com.heima.set; import java.util.HashSet; import com.heima.bean.Person; public class Demo1_HashSet { public static void main(String[] args) { demo2(); } public static void demo2() { HashSet<Person> hs = new HashSet<Person>(); hs.add(new Person("张三", 23)); hs.add(new Person("张三", 23)); hs.add(new Person("张三", 23)); hs.add(new Person("李四", 24)); hs.add(new Person("李四", 24)); hs.add(new Person("张三", 23)); System.out.println(hs.size()); // 只有两个元素 System.out.println(hs); } }
HashSet存储自定义对象保证元素唯一性图解及代码优化
* A:画图演示
* 画图说明比较过程
* B:代码优化
* 为了减少比较,优化hashCode() 代码的写法
* 最终版就是自动生成即可

HashSet保证元素唯一性的原理
* A:HashSet原理
* 我们使用Set集合都是需要去掉重复元素的,如果在存储的时候逐个调用 equals方法比较效率较低
* 哈希算法提高了去重复的效率,降低了使用equals() 方法的次数
* 当 HashSet 调用add() 方法存储对象的时候,就会先调用对象的 hashCode()方法得到一个哈希值,然后再集合中查找是否有哈希值相同的对象
* 如果没用哈希值相同的对象就直接存入集合
* 如果有哈希值相同的对象,就和哈希值相同的对象逐个进行 equals() 比较,比较结果为 false就存入,为 true就不存
* B:将自定义的对象存入HashSet去重复
* 类中必须重写hashCode() 和 equals() 方法
* hashCode() :属性相同的对象返回值就必须相同,属性不同的对象返回值尽量不同(提高效率)
* equals() :属性相同的返回 true,属性不同的返回 false,返回 false的时候存储
@Override public int hashCode() { final int prime = 31; // 选31的原因:质数可降低冲突率;大小合适;可以被 JVM 优化 -> 31 * i = (i << 5) - i int result = 1; result = prime * result + age; result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; }
@Override public boolean equals(Object obj) { if (this == obj) // 如果调用的和传入的是同一个对象,自己和自己比较 return true; // 直接返回true if (obj == null) // 传入的对象为null,调用的不可能为null,不然不可能调用方法 return false; // 直接返回false if (getClass() != obj.getClass()) // 判断字节码文件是否相同,getClass方法返回 字节码文件 return false; Person other = (Person) obj; // 向下转型,之前的判断可以保证不会出现类型转换异常 if (age != other.age) // 具体判断属性是否相等 return false; if (name == null) { if (other.name != null) return false; } else if (!name.equals(other.name)) return false; return true; }
LinkedHashSet的概述和使用
* A:LinkedHashSet的特点
* B:案例演示
* LinkedHashSet的特点
* 可以保证怎么存就怎么取
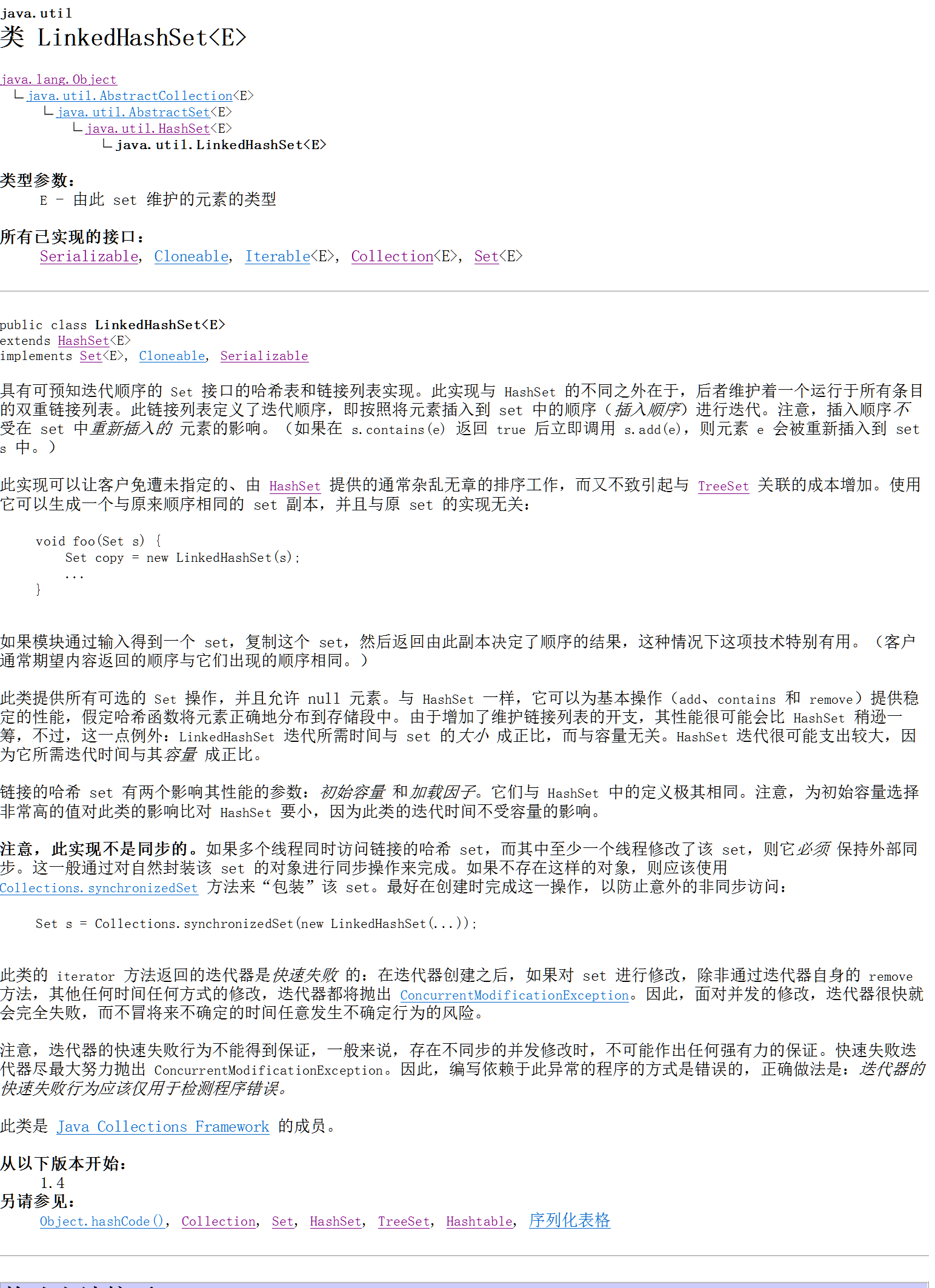
package com.heima.set; import java.util.LinkedHashSet; public class Demo2_LinkedHashSet { /* * LinkedHashSet * 底层是链表实现的,是set集合中唯一一个能保证怎么存就怎么取的集合对象 * 因为是HashSet的子类,所以也是保证元素唯一的,与HashSet的原理一样 */ public static void main(String[] args) { LinkedHashSet<String> lhs = new LinkedHashSet<String>(); // 创建LinkedHashSet对象 lhs.add("a"); // 向LinkedHashSet内存储元素 lhs.add("b"); lhs.add("c"); lhs.add("d"); lhs.add("d"); lhs.add("d"); System.out.println(lhs); } }
产生10个1-20之间的随机数要求随机数不重复
* A:案例演示
* 需求:编写一个程序,获取10个1至20的随机数,要求随机数不能重复。并把最终的随机数输出到控制台
package com.heima.test; import java.util.HashSet; import java.util.Random; public class Test1 { /* * 分析: * 1、有Random类创建随机数对象 * 2、元素不能重复,用HashSet存储 * 3、如果HashSet的size是小于10,就不断地存储 * 4、通过Random类中的nextInt(n)方法获取1到20之间的随机数 * 5、遍历集合,打印元素 */ public static void main(String[] args) { Random r = new Random(); // 创建Random对象 HashSet<Integer> hs = new HashSet<Integer>(); // 创建泛型为Integer的HashSet集合 while (hs.size() < 10) { int num = r.nextInt(20) + 1; // 生成1到20的随机数 hs.add(num); } for (Integer integer : hs) { // 遍历集合 System.out.println(integer); // 打印每一个元素 } } }
键盘读入一行字符串,去重后打印
* 使用Scanner 从键盘读取一行输入,去掉其中重复的字符,打印出不同的那些字符
package com.heima.test; import java.util.LinkedHashSet; import java.util.Scanner; public class Test2 { /* * 分析: * 1、创建Scanner对象 * 2、创建LinkedHashSet对象,保证怎么存怎么取 * 3、将字符串转换为数组,获取每一个字符,存储再集合中,自动去除重复 * 4、遍历集合,打印每个字符 */ public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 创建Scanner对象 LinkedHashSet<Character> lhs = new LinkedHashSet<Character>(); // 创建泛型为CHaracter的LinkedHashSet集合 System.out.println("请输入一行字符串"); String str = sc.nextLine(); // 键盘录入字符串 for (int i = 0; i < str.length(); i++) { // 遍历字符串 char c = str.charAt(i); // 转换为字符 lhs.add(c); // 将字符存入到集合中 } System.out.println(lhs); // 打印集合 } }
去除集合中的重复元素
* A:案例演示
* 去除集合中的重复元素
package com.heima.test; import java.util.ArrayList; import java.util.LinkedHashSet; import java.util.List; public class Test3 { /* * 分析: * 1、创建List集合存储若干个重复元素 * 2、单独定义一个方法去除重复 * 3、打印List集合 */ public static void main(String[] args) { ArrayList<String> list = new ArrayList<String>(); // 创建泛型为String的ArrayList集合 list.add("a"); // 存储若干个元素 list.add("a"); list.add("b"); list.add("b"); list.add("b"); list.add("b"); list.add("c"); list.add("c"); list.add("c"); list.add("c"); list.add("c"); list.add("c"); list.add("c"); list.add("a"); getSingle(list); // 单独定义方法去重 System.out.println(list); // 打印集合 } /* * 分析: * 1、创建LinkedHashSet * 2、将List集合中的所有元素添加到LinkedHashSet中 * 3、清空List集合 * 4、将LinkedHashSet中的元素添加回List中 */ public static void getSingle(List<String> list) { LinkedHashSet<String> lhs = new LinkedHashSet<String>(); // 创建泛型为String的LinkedHashSet集合 lhs.addAll(list); // 将List集合中的所有元素都添加到LinkedHashSet中 list.clear(); // 清空List list.addAll(lhs); // 将LinkedHashSet中的元素添加到List中 } }
TreeSet存储元素并遍历
* A:案例演示
* TreeSet存储 Integer类型的元素并遍历
* TreeSet存储 Person对象

@Override public int compareTo(Person o) { int num = this.name.compareTo(o.name); // 名字是主要条件 return num == 0 ? this.age - o.age : num; } @Override public int compareTo(Person o) { int num = this.age - o.age; // 年龄是比较的主要条件 return num == 0 ? this.name.compareTo(o.name) : num; // 名字是次要条件 } } public int compareTo(Person o) { int length = this.name.length() - o.name.length(); // 比较长度为主要条件 int num = length == 0 ? this.name.compareTo(o.name) : length; // 比较长度为次要条件 return num == 0 ? this.age - o.age : num; // 比较年龄为再次条件 }
package com.heima.set; import java.util.Comparator; import java.util.TreeSet; import com.heima.bean.Person; public class Demo3_TreeSet { /* * TreeSet集合可以对对象元素进行排序,同时也能保证元素的唯一 * 当compareTo方法返回0时,集合中只有一个元素 * 当compareTo方法返回正数的时候,集合会怎么存怎么取 * 当compareTo方法返回符数的时候,集合会倒序存储 */ public static void main(String[] args) { // demo1(); // demo2(); // demo3(); // demo4(); // demo5(); } public static void demo5() { TreeSet<String> ts = new TreeSet<String>(new CompareByLen()); ts.add("aaa"); ts.add("z"); ts.add("wc"); ts.add("a"); System.out.println(ts); } public static void demo4() { TreeSet<Person> pts = new TreeSet<Person>(); pts.add(new Person("zhangsan", 23)); pts.add(new Person("lisi", 13)); pts.add(new Person("wangwu", 43)); pts.add(new Person("zhaoliu", 33)); System.out.println(pts); } public static void demo3() { TreeSet<Person> pts = new TreeSet<Person>(); pts.add(new Person("张三", 23)); pts.add(new Person("李四", 13)); pts.add(new Person("王五", 43)); pts.add(new Person("赵六", 33)); System.out.println(pts); } public static void demo2() { TreeSet<Person> pts = new TreeSet<Person>(); pts.add(new Person("张三", 23)); pts.add(new Person("张三", 23)); pts.add(new Person("李四", 24)); pts.add(new Person("李四", 24)); pts.add(new Person("李四", 24)); pts.add(new Person("李四", 24)); pts.add(new Person("张三", 23)); pts.add(new Person("张三", 23)); pts.add(new Person("王五", 25)); pts.add(new Person("王五", 25)); pts.add(new Person("王五", 25)); pts.add(new Person("赵六", 26)); pts.add(new Person("赵六", 26)); pts.add(new Person("王五", 25)); System.out.println(pts); } public static void demo1() { TreeSet<Integer> ts = new TreeSet<Integer>(); // TreeSet是用来对元素进行排序的 ts.add(1); ts.add(1); ts.add(1); ts.add(2); ts.add(2); ts.add(1); ts.add(3); ts.add(3); ts.add(3); ts.add(3); System.out.println(ts); } } class CompareByLen implements Comparator<String> { @Override public int compare(String o1, String o2) { int num = o1.length() - o2.length(); return num == 0 ? o1.compareTo(o2) : num; } }
TreeSet保证元素唯一和自然排序的原理和图解
* A:画图演示
* TreeSet保证元素是唯一的 和 自然排序的原理和图解

@Override public int compareTo(Person o) { int num = this.age - o.age; // 年龄是比较的主要条件 return num == 0 ? this.name.compareTo(o.name) : num; // 名字是次要条件 } }
TreeSet存储自定义对象并遍历练习1
* A:案例演示
* TreeSet存储自定义对象并遍历(按照姓名排序)
@Override public int compareTo(Person o) { int num = this.name.compareTo(o.name); // 按照姓名排序 return num == 0 ? this.age - o.age : num; }
public int compareTo(String anotherString) { byte v1[] = value; byte v2[] = anotherString.value; byte coder = coder(); if (coder == anotherString.coder()) { return coder == LATIN1 ? StringLatin1.compareTo(v1, v2) : StringUTF16.compareTo(v1, v2); } return coder == LATIN1 ? StringLatin1.compareToUTF16(v1, v2) : StringUTF16.compareToLatin1(v1, v2); }
TreeSet存储自定义对象并遍历练习2
* A:案例演示
* TreeSet存储自定义对象并遍历练习2(按照姓名的长度排序)
@Override public int compareTo(Person o) { int length = this.name.length() - o.name.length(); // 比较长度为主要条件 int num = length == 0 ? this.name.compareTo(o.name) : length; // 比较长度为次要条件,如果length为0,再比较姓名 return num == 0 ? this.age - o.age : num; // 比较年龄为再次要的条件,如果num为=,再比较年龄 }
TreeSet保证元素唯一和比较器排序的原理
* A:案例演示
* TreeSet保证元素唯一和比较器排序的原理及代码实现


package com.heima.set; import java.util.Comparator; import java.util.TreeSet; import com.heima.bean.Person; public class Demo3_TreeSet { public static void main(String[] args) { // demo5(); } public static void demo5() { // 需求:将字符串按照长度排序 TreeSet<String> ts = new TreeSet<String>(new CompareByLen()); ts.add("aaa"); ts.add("z"); ts.add("wc"); ts.add("a"); System.out.println(ts); } } class CompareByLen implements Comparator<String> { @Override public int compare(String o1, String o2) { int num = o1.length() - o2.length(); // 以字符串长度比较为主要条件 return num == 0 ? o1.compareTo(o2) : num; } }
TreeSet原理详解
* A:特点
* TreeSet 是用来排序的,可以指定一个顺序,对象存入之后会按照指定的顺序排列
* B:使用方法
* a:自然顺序(Comparable)
* TreeSet 类的 add() 方法中会把存入的对象提升为 Comparable 类型
* 调用对象的 compareTo() 方法和集合中的其他元素进行比较
* 根据 compareTo() 方法返回的结果进行存储
* b:比较器顺序:
* 创建 TreeSet 时可以指定一个 Comparator
* 如果传入了 Comparator 的子类对象,那么TreeSet就会按照比较器中的顺序排序
* add() 方法内部会自动调用Comparator 接口中的 compare() 方法排序
* c:两种方式的区别:
* TreeSet 构造函数什么都不传,默认按照类中的 Comparable 的顺序(没有就报错 ClassCastException)
* TreeSet 如果传入 Comparator,就优先按照 Comparator
练习1
* 在一个集合中存储了无序且重复的字符串,定义一个方法,让其有序(字典顺序),而且还不能去除重复
* 难点在于compare方法的重写上
package com.heima.test; import java.util.ArrayList; import java.util.Comparator; import java.util.TreeSet; public class Test4 { /* * 分析: * 1、定义一个List集合,并存储重复且无序的字符串 * 2、定义方法,对其排序并且保留重复 * 3、打印List集合 */ public static void main(String[] args) { ArrayList<String> alist = new ArrayList<String>(); // 定义泛型为String的ArrayList alist.add("aaa"); // 向集合内存储数据 alist.add("aaa"); alist.add("ccc"); alist.add("ccc"); alist.add("ddd"); alist.add("ddd"); alist.add("ddd"); alist.add("ddd"); alist.add("eeeeeee"); alist.add("eeeeeee"); alist.add("eeeeeee"); alist.add("cly"); alist.add("cly"); alist.add("aaa"); sort(alist); // 定义方法对其排序保留重复 System.out.println(alist); } /* * 分析: * 1、创建TreeSet集合对象,因为String本身就具备比较功能,但是重复不会保留,所以我们用比较器 * 2、将list集合中的所有元素添加到TreeSet集合中,对其排序,但保留重复 * 3、清空list * 4、将TreeSet中的元素添加到list中 */ private static void sort(ArrayList<String> alist) { TreeSet<String> ts = new TreeSet<String>(new Comparator<String>() { // 创建泛型为String的TreeSet集合,构造方法中传入匿名内部类 @Override public int compare(String s1, String s2) { // 重写compare方法 int num = s1.compareTo(s2); return num == 0 ? 1 : num; // 如果字符串相同就返回1或是其他任意非零数字,使其保留;如果不相同,就按照字符串的compareTo()方法 } }); ts.addAll(alist); // 将list中的元素添加到TreeSet中 alist.clear(); // 清空list alist.addAll(ts); // 将TreeSet中的元素添加到list中 } }
练习2
* 从键盘接收一个字符串,程序对其中所有字符进行排序,例如键盘输入:helloitcast 程序打印:acehillostt
package com.heima.test; import java.util.Comparator; import java.util.Scanner; import java.util.TreeSet; public class Test5 { /* * 分析: * 1、键盘录入字符串,新建Scanner对象 * 2、将字符串转换为字符数组 * 3、定义TreeSet集合,传入比较器并对字符进行排序且保留重复 * 4、遍历字符数组,将每个字符存储在TreeSet中 * 5、遍历TreeSet集合,打印字符 */ public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 创建键盘录入对象 System.out.println("请输入一行字符串"); String str = sc.nextLine(); // 录入字符串 char[] arr = str.toCharArray(); // 将字符串转换为字符数组 TreeSet<Character> ts = new TreeSet<Character>(new Comparator<Character>() { // 创建泛型为Character的TreeSet集合,并且传入一个比较器的匿名对象 @Override public int compare(Character o1, Character o2) { int num = o1.compareTo(o2); return num == 0 ? 1 : num; // 如果两个字符相等,返回非零数;如果不同,按照字典顺序排序 } }); for (Character character : arr) { // 遍历数组,手动装箱 ts.add(character); // 将每一个字符存储到TreeSet中 } for (Character character : ts) { // 遍历TreeSet System.out.print(character); // 打印字符 } } }
练习3
* 程序启动后,从键盘接收多个整数,知道输入quit时结束,把所有的整数倒叙排列打印
package com.heima.test; import java.util.Comparator; import java.util.Scanner; import java.util.TreeSet; public class Test6 { /* * 分析: * 1、创建Scanner对象,键盘录入 * 2、创建TreeSet集合对象,传入比较器对象 * 2、定义无限循环,遇到quit时退出 */ public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 创建键盘录入对象 TreeSet<Integer> ts = new TreeSet<Integer>(new Comparator<Integer>() { // 创建泛型为Integer的TreeSet集合,并传入Comparator的匿名内部类 @Override public int compare(Integer o1, Integer o2) { int num = o2.compareTo(o1); // 实现倒序 return num == 0 ? 1 : num; } }); while (true) { // 定义无限循环 String str = sc.nextLine(); // 键盘录入字符串 if ("quit".equals(str)) { // 判断是否为quit break; } try { Integer integer = Integer.parseInt(str); // 将字符串型数字转换为数字型数字 ts.add(integer); // 将数字添加到TreeSet中 } catch (Exception e) { System.out.println("录入错误,请重写录入"); } } for (Integer integer : ts) { // 遍历集合 System.out.print(integer + " "); // 打印元素 } } }
练习4
* 键盘录入5个学生信息(姓名,语文成绩,数学成绩,英语成绩),按照总分从高到低输出到控制台
package com.heima.test; import java.util.Comparator; import java.util.Scanner; import java.util.TreeSet; import com.heima.bean.Student; public class Test7 { /* * 分析: * 1、定义学生类 * 成员变量:姓名,语文成绩,数学成绩,英语成绩,总成绩(通过三门成绩算出来) * 成员方法:空参,有参构造,有参构造的参数分别时:姓名,语文成绩,数学成绩,英语成绩 * toString() 方法 * 2、创建键盘录入对象,Scanner * 3、创建TreeSet集合,按照总分排序 * 4、录入五个学生,所以以集合中的学生个数为判断条件,如果size小于5,就存储 * 5、将录入的字符串切割,用逗号切割,返回一个字符串数组,将字符串数组中的第二个元素开始转换成int数 * 6、将转换后的结果封装成Student对象,将Student对象添加到TreeSet集合中 * 7、遍历TreeSet集合,打印元素 */ public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 创建Scanner对象 TreeSet<Student> ts = new TreeSet<Student>(new Comparator<Student>() { // 创建泛型为Student的TreeSet集合,并传入比较器的匿名内部类 @Override public int compare(Student o1, Student o2) { // 重写方法 int num = o2.getSum() - o1.getSum(); return num == 0 ? 1 : num; // 依据总分排序 } }); System.out.println("请输入学生成绩格式是:姓名,语文成绩,数学成绩,英语成绩"); // 提示输入 while (ts.size() < 5) { String line = sc.nextLine(); // 键盘录入 String[] arr = line.split(","); // 切割字符串 int chinese = Integer.parseInt(arr[1]); // 将数字字符串转换为数字 int math = Integer.parseInt(arr[2]); int english = Integer.parseInt(arr[3]); ts.add(new Student(arr[0], chinese, math, english)); // 通过有参构造创建Student对象并存入TreeSet中 } for (Student student : ts) { // 遍历TreeSet System.out.println(student); // 打印元素 } } }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗