03----python入门----函数相关
一、前期知识储备
函数定义

你可以定义一个由自己想要功能的函数,以下是简单的规则:
-
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()
- 任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明
- 函数内容以冒号起始,并且缩进
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
函数调用与参数传递
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
-
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃
-
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
-
不可变类型:传值调,用如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。
-
可变类型:传地址调用,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说传值调用还是传地址调用,我们应该说传不可变对象和传可变对象。



# 可写函数说明 def changeme( mylist ): "修改传入的列表" mylist.append([1,2,3,4]) print ("函数内取值: ", mylist) return # 调用changeme函数 mylist = [10,20,30] changeme( mylist ) print ("函数外取值: ", mylist) ''' 函数内取值: [10, 20, 30, [1, 2, 3, 4]] 函数外取值: [10, 20, 30, [1, 2, 3, 4]] '''
参数
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
必需参数:必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
#可写函数说明 def printme( str ): "打印任何传入的字符串" print (str) return # 调用 printme 函数,不加参数会报错 printme() ''' Traceback (most recent call last): File "test.py", line 10, in <module> printme() TypeError: printme() missing 1 required positional argument: 'str' '''
关键字参数:关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
#可写函数说明 def printinfo( name, age ): "打印任何传入的字符串" print ("名字: ", name) print ("年龄: ", age) return #调用printinfo函数 printinfo( age=50, name="runoob" ) ''' 名字: runoob 年龄: 50 '''
默认参数:调用函数时,如果没有传递参数,则会使用默认参数。
#可写函数说明 def printinfo( name, age = 35 ): "打印任何传入的字符串" print ("名字: ", name) print ("年龄: ", age) return #调用printinfo函数 printinfo( age=50, name="runoob" ) print ("------------------------") printinfo( name="runoob" ) ''' 名字: runoob 年龄: 50 ------------------------ 名字: runoob 年龄: 35 '''
不定长参数:你可能需要一个函数能处理比当初声明时更多的参数。
这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名。
基本语法如下:
def functionname([formal_args,] *var_args_tuple ): "函数_文档字符串" function_suite return [expression]
一个*
加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。
def printinfo( arg1, *vartuple ): "打印任何传入的参数" print ("输出: ") print (arg1) print (vartuple) # 调用printinfo 函数 printinfo( 70, 60, 50 ) ''' 输出: 70 (60, 50) '''
如果在函数调用时没有指定参数,它就是一个空元组。我们也可以不向函数传递未命名的变量。
def printinfo( arg1, *vartuple ): "打印任何传入的参数" print ("输出: ") print (arg1) for var in vartuple: print (var) return # 调用printinfo 函数 printinfo( 10 ) printinfo( 70, 60, 50 ) ''' 输出: 10 输出: 70 60 50 '''
两个*
加了两个星号 ** 的参数会以字典的形式导入。
# 可写函数说明 def printinfo( arg1, **vardict ): "打印任何传入的参数" print ("输出: ") print (arg1) print (vardict) # 调用printinfo 函数 printinfo(1, a=2,b=3) ''' 输出: 1 {'a': 2, 'b': 3} '''
声明函数时,参数中星号 * 可以单独出现
如果单独出现星号 * 后的参数必须用关键字传入。
>>> def f(a,b,*,c): ... return a+b+c ... >>> f(1,2,3) # 报错 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: f() takes 2 positional arguments but 3 were given >>> f(1,2,c=3) # 正常 6 >>>
注意点
··· 过程就是没有return值的函数
··· 如果返回多个值,但是会以元组的形式返回,多个值存放在一个元组内
··· 实参可以是常量、变量、表达式、函数等
··· 形参只有在被调用时才被分配内存单元调用结束就会清空
··· 位置参数 必须一一对应,缺一不行;关键字参数,无需一一对应
··· 如果混搭:位置参数必须在关键字参数左边
··· 每个变量只能传一次,没有覆盖的说法
··· 默认参数,不传就用默认的,传了就用新的
··· 参数组 非固定长度的参数 便于后期函数的扩展


二、函数嵌套与作用域
嵌套
函数的嵌套调用
def max(x,y): return x if x > y else y def max4(a,b,c,d): res1=max(a,b) res2=max(res1,c) res3=max(res2,d) return res3 print(max4(1,2,3,4))
函数的嵌套定义
def f1(): def f2(): def f3(): print('from f3') f3() f2() f1() f3() #报错,为何?请看下一小节
名称空间
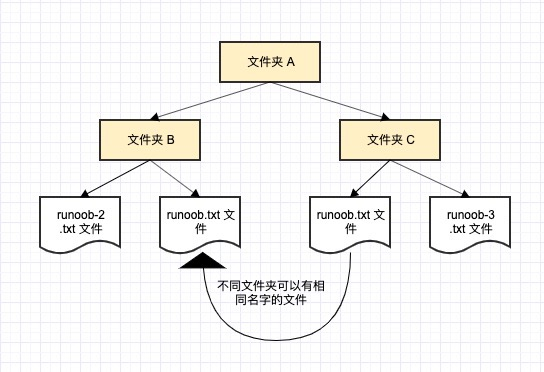
一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)

命名空间查找顺序:
假设我们要使用变量 runoob,则 Python 的查找顺序为:局部的命名空间去 -> 全局命名空间 -> 内置命名空间。
如果找不到变量 runoob,它将放弃查找并引发一个 NameError 异常
命名空间的生命周期:
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。
因此,我们无法从外部命名空间访问内部命名空间的对象。
作用域
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
有四种作用域:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等。,最后被搜索
规则顺序: L –> E –> G –> B。

g_count = 0 # 全局作用域 def outer(): o_count = 1 # 闭包函数外的函数中 def inner(): i_count = 2 # 局部作用域
需要注意的是:在全局无法查看局部的,在局部可以查看全局的
全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。
调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。
total = 0 # 这是一个全局变量 # 可写函数说明 def sum( arg1, arg2 ): #返回2个参数的和." total = arg1 + arg2 # total在这里是局部变量. print ("函数内是局部变量 : ", total) return total #调用sum函数 sum( 10, 20 ) print ("函数外是全局变量 : ", total) ''' 函数内是局部变量 : 30 函数外是全局变量 : 0 '''
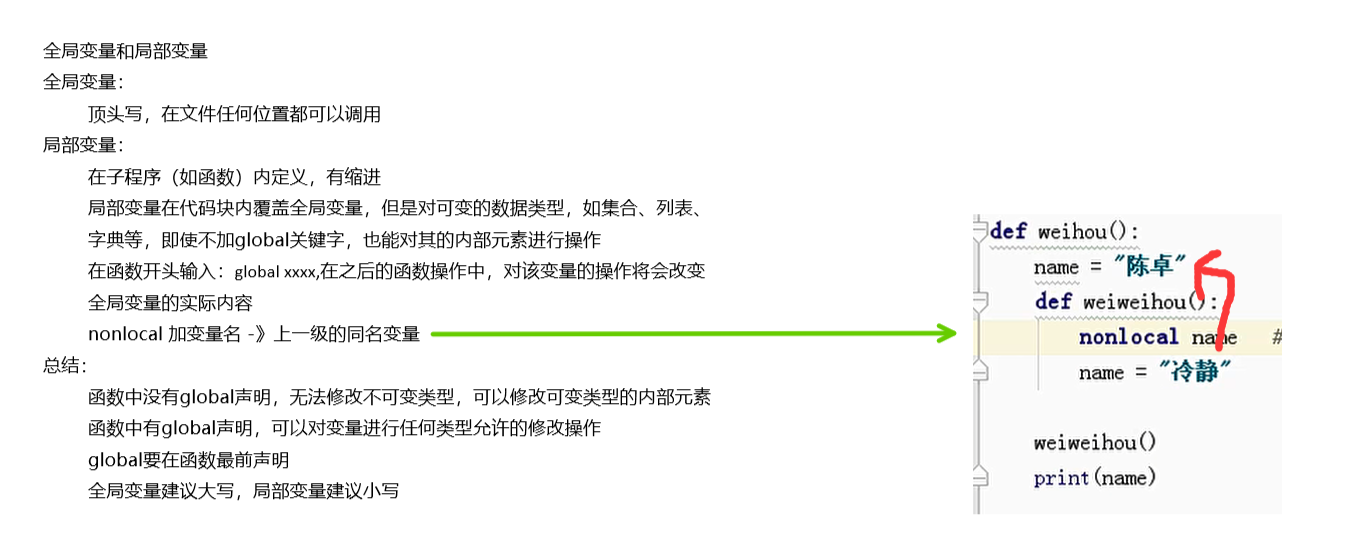
global 和 nonlocal关键字
当内部作用域想修改外部作用域的变量时,就要用到global和nonlocal关键字了。
num = 1 def fun1(): global num # 需要使用 global 关键字声明 print(num) num = 123 print(num) fun1() print(num) ''' 1 123 123 '''
如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了,如下实例:def outer():
num = 10 def inner(): nonlocal num # nonlocal关键字声明 num = 100 print(num) inner() print(num) outer() ''' 100 100
'''
注意,nonlocal调用的是上一层,如果它的外层函数没有该变量就报错
另外,最外层的函数不能用nonlocal,因为nonlocal只针对内部变量
三、函数式编程
函数式编程是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量
因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。
而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
匿名函数
python 使用 lambda 来创建匿名函数。
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
代码语法如下:
lambda [arg1 [,arg2,.....argn]]:expression
'''
( 函数名 = ) lambda 形参:返回值
通常不会单独用,应该和其他函数联合使用
lambda 返回多个值需要自己手动将所有返回值添加到一个元组或列表中
'''
map()函数
map是python内置函数,会根据提供的函数对指定的序列做映射。
map()函数的格式是:
map(func,seq,...)
第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列。
1、当seq只有一个时,将函数func作用于这个seq的每个元素上,并得到一个新的seq。
在新的可迭代对象中,每个元素对应的位置与原序列一致
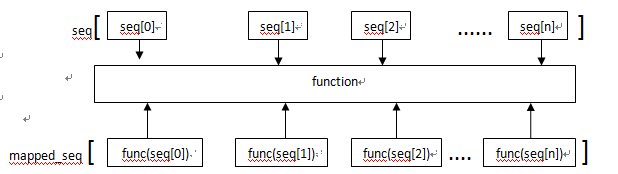
从上图可以看出,func函数会作用于seq中的每个元素,得到func(seq[n])组成的列表,最终结果需要用列表解析承接,或者for循环去取
并且每调用一次map函数,只能解析一次
2、当seq多于一个时,map可以并行(注意是并行)地对每个seq执行
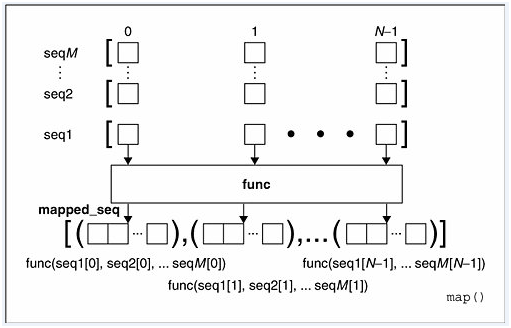
从图可以看出,每个seq的同一位置的元素同时传入一个多元的func函数之后,得到一个返回值,并将这个返回值存放在一个列表中。

注意:
map无法处理seq长度不一致、对应位置操作数类型不一致的情况
使用map()函数可以实现将其他类型的数转换成list
fliter()函数
filter()
def add(a): return a%2==0 print(list(filter(add,[1,2,3,4]))) [2, 4]
stu_score = {'xiaobai':50,'xiaohei':30,'xiaolan':80,'xiaojun':100,'xiaoming':60}
result=filter(lambda score:score>60,stu_score.values())
print(list(result))
[80, 100]
reduce()函数
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:
用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,
得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
格式
reduce(function, iterable[, initializer])
- function -- 函数,有两个参数
- iterable -- 可迭代对象
- initializer -- 可选,初始参数
需要调用 functools 模块
未初始化
from functools import reduce lst=[1,2,3,4] print(reduce(lambda x,y: x*y, lst))
'''
24
'''
已初始化
from functools import reduce lst=[1,2,3,4] print(reduce(lambda x,y: x+y, lst,5)) # 5是初始值,也可以理解为第三个参数 # 计算呢过程 -->5+1=6 -->6+2=8 -->8+3=11 -->11+4=15
zip()函数
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,
然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
语法
zip([iterable, ...])
- iterabl -- 一个或多个迭代器;
举例
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 返回一个对象
>>> zipped
<zip object at 0x103abc288>
>>> list(zipped) # list() 转换为列表
[(1, 4), (2, 5), (3, 6)]
>>> list(zip(a,c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
>>> list(a1)
[1, 2, 3]
>>> list(a2)
[4, 5, 6]
>>>x = [1, 2, 3] #多个列表处理
>>>y = [4, 5, 6]
>>>z = [7, 8, 9]
>>>xyz = zip(x, y, z)
>>>xyz
[(1, 4, 7),(2, 5, 8),(3, 6, 9)]
>>>x = {'age':18,'name':'dh','id':3306} #处理字典
>>>y = zip(x.values(),x.keys())
>>>list(y)
[(18, 'age'), ('dh', 'name'), (3306, 'id')]

max()函数 和 min()函数
函数函数功能为取传入的多个参数中的最大值,或者传入的可迭代对象元素中的最大值。
默认数值型参数,取数值大的;字符型参数,取字母表排序靠后者。
还可以传入命名参数key,其为一个函数,用来指定取最大值的方法。
default命名参数用来指定最大值不存在时返回的默认值。
语法:
max(iterable, *[, key, default])
- iterabl -- 一个或多个迭代器;
- key -- 函数
- default -- 默认返回值
处理数组时:
''' 如果有一组商品,其名称和价格都存在一个字典中,可以用下面的方法快速找到价格最贵的那组商品:
''' prices = { 'A':123, 'B':450.1, 'C':12, 'E':444, } # 在对字典进行数据操作的时候,默认只会处理key,而不是value
# 当字典中的value相同的时候,才会比较key # 先使用zip把字典的keys和values翻转过来,再用max取出值最大的那组数据 max_prices = max(zip(prices.values(), prices.keys())) print(max_prices) #这个时候key是值,value是之前的key # (450.1, 'B')
key参数的应用:
#以多个字典中的number作为对比依据。 >>> def sort(x): ... return x['number'] ... >>> max({'number': 18, 'price': 1.53}, {'number': 20, 'price': 0.53}, key = sort) {'number': 20, 'price': 0.53} >>> def sort(x): ... return x['price'] ... >>> max({'number': 18, 'price': 1.53}, {'number': 20, 'price': 0.53}, key = sort) {'number': 18, 'price': 1.53}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗