
:Java8中,hashmap的容量大小为什么必须是2的幂次方?
Java8中,hashmap的容量大小为什么必须是2的幂次方?
最近在复习基础知识,在复习到hashmap的时候,看到hashmap的容量大小必须是2的幂次方,我当时脑子想到的就是:为了使每一个桶发生哈希冲突的概率相同,从而避免某些桶大量发生哈希冲突,而某些桶不发生哈希冲突的情况,浪费资源
但是在沾沾自喜之后,我又想:为什么呢?为什么2的幂次方就能够保证每一个桶发送哈希冲突的概率相同? 于是我去了看源码,于是,有了这篇文章。
前提需知
我们知道,hashmap的默认大小是16,负载因子是0.75。
hashmap的扩容需要满足两个条件:
①当前数据存储的数量(即size())大小必须大于等于阈(yu)值(16*0.75=12);
②当前加入的数据是否发生了hash冲突。
关键源码
好了,以上就是看源码的前提了,接下来我们看源码,这里只贴最关键的两句
我们看一下这个获取hash值的算法
337 static final int hash(Object key) {
338 int h;
339 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
400 }
2032 int n=tab.length-1
2035 int index = (n - 1) & hash;
是不是特别简洁?我一直很反感解读源码的时候直接贴个几十行代码来让我们看,太难读了,所以我就跨越两千行,找出了关键代码,这里我特别贴了行数,各位可以自己去对应行去查看源码,。
源码解释
我来解释一下,一个对象要想找到对应的位置,大致分为三步:
①直接调用native方法hashcode获得hash值,源码中339行:h=key.hashCode()
②将获得的hash值h与h进行无符号右移的值进行‘异或’:源码中339行:h^(h>>>16)
③第②步的异或结果与数组长度减一进行‘与’操作,源码中2035行:(n-1)&hash
如此2035行中的index就是最终的位置了
大家再回过头来想一想,为什么一定要是2的幂次方倍呢?
源码2035行中,(n-1)&hash,是数组长度-1,
如果数组长度是16,减一后就是15,而15的二进制码是:1111
如果数组长度是32,减一后就是31,而31的二进制码是:11111
如果数组长度是64,减一后就是63,而63的二进制码是:111111
很容易可以看出来,所有的二进制码中,都是1,那么这些都是1的二进制码跟hash值进行
‘与’操作后,就可以确保每一个位置发生hash冲突的概率是相同的。
原理就是当两个数相‘与’,如果其中一个数的二进制码全部都是1,就可以确保每个位数中相‘与’的结果完全取决于另一个数。
举个例子
我知道很难理解,我举个例子,a=111111,b=101011:
111111
101011
———————
101011
结果是不是就取决于下面这个数是0还是1?
如果b的某个位数的值为1,那么相’与’的结果就是1,如果某个位数的值为0,那么相‘与’的结果就是0.
我们来设想一下,如果数组长度减一不是2的幂次方倍,假如是34,那么a=34-1= 33 = 100001,b=101010
100001
101010
______
100000
我们可以轻易得出一个结论,只要a的的某个位数的值为0,则无论hash值b对应位数的值是0还是1,相与的结果都是0,这就会导致数组中的某些永远不可能发生hash冲突。
还是不明白为什么相与结果永远都是0,就会导致某些位置永远不可能发生hash冲突?
我在这里写了一个测试方法,我们看
代码测试实例
这是没什么用的用于确保可以循环创建不同对象的测试类
/**
* 测试类,
*/
static class Good{
Integer m=null;
public Good(int i){
m=i;
}
}
}
这是测试方法,计算每个位置发生hash冲突的次数
package cn.ycl;
import java.util.HashMap;
/**
* @author ycl
* @time 2020/08/16
*/
public class TestDemo {
public static void main(String[] args) {
HashMap<Integer, Integer> map = new HashMap<>();
//循环创建100个不同的对象,调用hashCode()方法
for (int i = 0; i <100; i++) {
int h=0;
//创建不同的对象
Good key=new Good(i);
//源码中计算hash值的两步
int hash1=(h = key.hashCode()) ^ (h >>> 16);
int hash=(16-1)&hash1;
//map中如果存在这个key,则value+1,否则加入map,value为1
if(map.containsKey(hash)){
int m=map.get(hash)+1;
map.put(hash,m);
}else{
map.put(hash,1);
}
}
//遍历
map.forEach((m,n)-> System.out.println("key:"+m+"\t"+"value:"+n));
}
测试结果
嫌代码长,不想看没关系,直接看我下面的结果就行。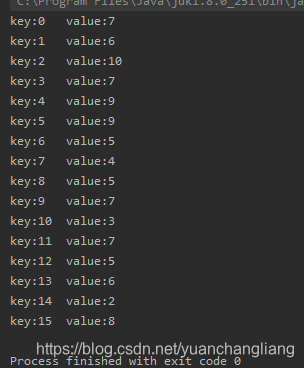
这是数组长度为16的默认长度,结果很友好,基本每一个位置都有值,概率是相同的。
如果我换成34这种非2的幂次方的长度呢?我修改一下测试代码

那么结果会如我们之前所猜测一样,部分位置永远不可能发生hash冲突吗?看结果

哇哦,居然只有第0,1,32,33号位置有值,其他位置连一个都没有,amzing!!!
一个结果没有说服力?我再来一个吧,数组长度换成17,也不是2的幂次方倍,我修改一下测试代码

我们看一下结果吧:

这次更逗,只有0和16号位置有值,这利用率太低了吧(就相当于有17个打饭窗口,所有人只去0号窗口和16号窗口打饭,这是赤裸裸的资源浪费)
结论:
只有数组长度是2的幂次方倍才能够确保数组中的每一个位置发生hash冲突的概率是相同的,数组长度减一的二进制码必须全部是1,否则会出现部分位置永远不会发生hash冲突而造成资源浪费
通过实例证明,Java开发组的智慧,我等凡夫俗子望尘莫及
我是“道祖且长”,一个在互联网苟且偷生的Java程序员


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~