

多线程消费方式
方式1:一个线程对应一个消费者
消费者数量不大于分区数,最好也能对等起来
方式2:多线程消费同一个分区
位移提交和顺序控制的处理非常复杂,不推荐
方式1:消费者<=分区数
int threadNum = 4;
for (int i = 0; i < threadNum; i++) {
new KafkaConsumer(config,"tcp_link").start();
}
public KafkaConsumerThread(Properties config, String topic) {
this.kafkaConsumer = new KafkaConsumer(config);
this.kafkaConsumer.subscribe(Collections.singleton(topic));
}
每个线程可以顺序消费各个分区中的消息,但也有个问题,每个
这里有个问题,每个线程都要维护一个独立的TCP连接,如果分区数和线程数很大,系统开销是大大的!
Flink里也在用的模型
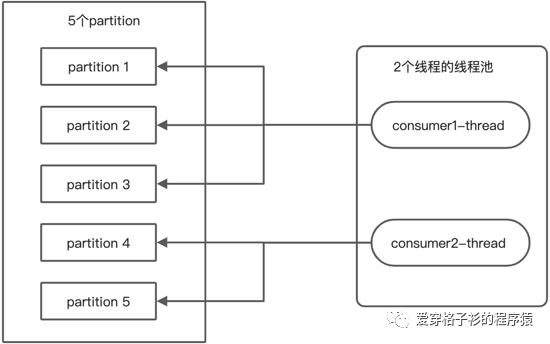
利用Kafka的topic分多个partition的机制来实现并行:每个线程都有自己的consumer实例,负责消费若干个partition。各个线程之间是完全独立的,不涉及任何线程同步和通信,像Flink里面用的就是这种模型。
先确定线程数,然后将分区数平均分给这些线程
final String topic = "test";
int partitionNum = getPartitionNum(topic);
final int threadNum = 4;
int partitionNumPerThread = (partitionNum <= threadNum) ? 1 : partitionNum / threadNum + 1;
ExecutorService threadPool = Executors.newFixedThreadPool(partitionNum);
List<TopicPartition> topicPartitions = new ArrayList<>(partitionNumPerThread);
for (int i = 0; i < partitionNum; i++) {
topicPartitions.add(new TopicPartition(topic, i));
if ((i + 1) % partitionNumPerThread == 0) {
threadPool.submit(new Task(new ArrayList<>(topicPartitions), config));
topicPartitions.clear();
}
}
if (!topicPartitions.isEmpty()) {
threadPool.submit(new Task(new ArrayList<>(topicPartitions), config));
}
threadPool.shutdown();
threadPool.awaitTermination(Integer.MAX_VALUE, TimeUnit.SECONDS);
}
static class Task implements Runnable {
private final List<TopicPartition> topicPartitions;
private final Properties config;
public Task(List<TopicPartition> topicPartitions, Properties config) {
this.topicPartitions = topicPartitions;
this.config = config;
}
@Override
public void run() {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(config);
consumer.assign(topicPartitions);
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10_000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
这种模型最大的优点是简单,但并非完美。在这种模型里面,获取数据、处理数据都是在一个线程里面的,如果在处理流程需要耗费很长时间,甚至是不可控的时候就会产生问题。
Kafka有一个参数 max.poll.interval.ms ,它表示的是两次poll调用的最大时间间隔。如果超过这个时间间隔,kafka就会认为这个consumer已经挂了,就会触发consumer group rebalance。 这个参数默认值是5分钟,也就是如果某次处理超过5分钟,那就可能导致rebalance。
Rebalance有什么问题呢?问题很大,对于Rebalance以后再介绍,这里先简单概括一下:
1、引发Consumer Group Rebalance操作主要有3种情况:(1)consumer数量发生变化(2)consumer订阅的主题发生变化(2)主题的分区数发生变化
2、Rebalance是一个比较重的操作,它需要consumer group的所有活着的consumer参与,当consumer比较多的时候,rebalance会很耗时(比如若干小时);而且在没有完成之前,大家都是干不了活的,体现在业务上就是停止处理了。
3、Rebalance其实就是重新划分partition,如果是自己提交offset的话,处理不好,就可能产生重复数据,后面再说。
总之,Rebalance操作能避免应该尽可能避免,特别是因为编码不合理产生的应该坚决改掉。
调整以下参数也能一定程度上解决问题:
max.poll.records
max.poll.interval.ms
如果这个过程中GES挂掉 也是解决不了的。
方式3:Multi-Thread Consumer Model
poll与处理消息模块拆分,处理消息模块用多线程
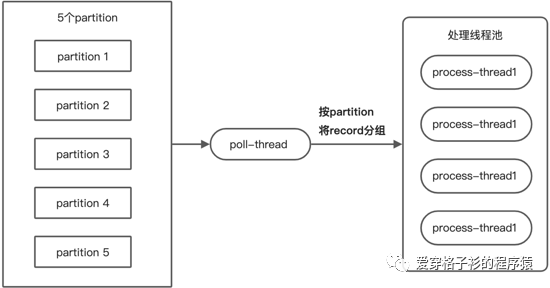
演示一下,这只是其中一种
流程为:poll线程专门负责拉取数据,然后将数据按partition分组,交给处理线程池,每个线程一次只处理一个分区的数据。数据交给处理线程后,poll继续拉取数据。现在有2个问题:
1、如何像Thread-Per-Consumer那样,保证一个分区里面的数据有序
2、如何提交offset
数据有序性
要保证partition内数据有序,只要避免多个线程并行处理同一个partition的数据即可。在poll线程给线程池分发数据的时候,已经按partition做了分组,也就是保证了一次拉取的数据中同一个partition的数据只会分配给一个线程。现在只要保证分区数据处理完成之前不再拉取该分区的数据,就可以保证数据的有序了。 KafkaConsumer 类提供了一个 pause 和 resume 方法,参数都是分区信息的集合:
public void pause(Collection<TopicPartition> partitions)
public void resume(Collection<TopicPartition> partitions)
调用 pause 方法后,后续 poll 的时候,这些被 pause 的分区不会再返回任何数据,直到被 resume 。所以,可以在本次partition的数据处理完成之前,pause该partition。
Offset提交
很显然,poll线程和处理线程解耦异步以后,就不能使用自动提交offset了,必须手动提交,否则可能offset提交了,但数据其实还没有处理。提交是poll线程做的,而offset的值则是处理线程才知道的,两者之前需要一个信息传递机制。代码实现的时候需要考虑。
这里插一个关于offset提交的话题。我们知道有2种方式提交offset:
自动提交 :将 enable.auto.commit 设置为 true 即可;每次poll的时候会自动提交上一次的offset。
手动提交 :分为同步提交 commitSync 和异步提交 commitAsync 。同步就是阻塞式提交,异步就是非阻塞式。而且二者都支持指定具体partition的offset,也就是可以精细化的自定义offset。
这里不展开介绍具体细节,只讨论一个问题:offset提交和消息传递语义(Message Delivery Semantics)的关系。Kafka提供了3种消息传递保证:
at most once :最多一次,即不会产生重复数据,但可能会丢数据
at least once :至少一次,即可能会产生重复数据,但不会丢数据
exactly once :准确的一次,不多也不少
首先 自动提交offset提供的是at least once的保证 ,因为他是在poll的时候提交上次数据的offset,也就是如果处理本次poll拉取的数据的时候异常了,导致没有执行到下次poll,那这次这些数据的offset就无法提交了,但数据可能已经处理了一部分了。要实现最多一次也很简单,每次poll完数据,先提交offset,提交成功之后再开始处理即可。而要实现exactly once很难,而且这里的exactly once其实仅指消费,但我们一般想要的是全系统数据链上的exactly once。这个问题比较复杂,要实现真正的端到端exactly once,可以去查查flink、dataflow的设计,需要有很多假设和权衡,这里就不展开了。
重点说明一种情况,考虑这样一个流程:poll数据,处理数据,手动同步提交offset,然后再poll。当然也可能会有变种,就是边处理数据,边提交offset,但实质一样。这种情况会不会产生数据重复?答案是:会。其实不管你用同步提交,还是异步提交,都可能产生数据重复。因为系统随时可能因为其它原因产生Rebalance。所以要真正避免重复数据,正确的方式应该是实现 ConsumerRebalanceListener 接口,监听Rebalance的发生。当监听到发生Rebalance导致当前consumer的partition发生变化时,同步提交offset。但即使这样,其实也不能严格避免,因为系统还可能在任意阶段挂掉。因此这种流程实际提供的也是at least once的保证。 所以这里想要表达的意思是,如果你的系统不能容忍有重复数据(在不丢数据的前提下),光靠kafka是做不到的,这里通过一些编码优化只能减少发生的概率,无法杜绝。终极方案应该是在应用层解决。 比如幂等设计、使用数据的时候去重等。
书上的代码
public class KafkaConsumerBase {
public final Properties configs;
public KafkaConsumerBase() {
this.configs = buildConfig();
}
public Properties buildConfig() {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:8080");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "group.demo");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return properties;
}
public void Scheduled(String[] args) {
List<String> topics = Arrays.asList("tcp_link", "agent");
KafkaConsumerThread kafkaConsumerThread = new KafkaConsumerThread(this.configs,
topics, Runtime.getRuntime().availableProcessors());
}
public static
class KafkaConsumerThread extends Thread {
private KafkaConsumer kafkaConsumer;
private ThreadPoolExecutor executor;
private Map<TopicPartition, OffsetAndMetadata> offsets;
public KafkaConsumerThread(Properties configs, List<String> topics, int threadNum) {
this.kafkaConsumer = new KafkaConsumer<>(configs);
kafkaConsumer.subscribe(topics);
executor = new ThreadPoolExecutor(threadNum, threadNum, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy());
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(10));
Iterable<ConsumerRecord<String, String>> recordIterable = records.records("tcp_link");
recordIterable.forEach(record -> {
record.partition();
record.value();
});
if (!records.isEmpty()) {
executor.submit(new MetricParser(records, offsets));
synchronized (offsets) {
if (!offsets.isEmpty()) {
kafkaConsumer.commitSync();
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
}
public class MetricParser extends Thread {
public final ConsumerRecords<String, String> records;
public Map<TopicPartition, OffsetAndMetadata> offsets;
public MetricParser(ConsumerRecords<String, String> records, Map<TopicPartition, OffsetAndMetadata> offsets) {
this.records = records;
this.offsets = offsets;
}
@Override
public void run() {
for (TopicPartition tp : records.partitions()) {
List<ConsumerRecord<String, String>> tpRecords = records.records(tp);
long lastOffset = tpRecords.get(tpRecords.size() - 1).offset();
synchronized (offsets) {
if (!offsets.containsKey(tp)) {
offsets.put(tp, new OffsetAndMetadata(lastOffset + 1));
} else {
long currOffset = offsets.get(tp).offset();
if (currOffset < lastOffset + 1) {
offsets.put(tp, new OffsetAndMetadata(lastOffset + 1));
}
}
}
}
}
}
网友代码
@Override
public void run() {
try {
// 主流程
while (!stopped.get()) {
// 消费数据
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10_000));
// 按partition分组,分发数据给处理线程池
handleFetchedRecords(records);
// 检查正在处理的线程
checkActiveTasks();
// 提交offset
commitOffsets();
}
} catch (WakeupException we) {
if (!stopped.get()) {
throw we;
}
} finally {
consumer.close();
}
}
@Slf4j
public class ProcessThread implements Runnable {
private final List<ConsumerRecord<String, String>> records;
private final AtomicLong currentOffset = new AtomicLong();
private volatile boolean stopped = false;
private volatile boolean started = false;
private volatile boolean finished = false;
private final CompletableFuture<Long> completion = new CompletableFuture<>();
private final ReentrantLock startStopLock = new ReentrantLock();
public ProcessThread(List<ConsumerRecord<String, String>> records) {
this.records = records;
}
@Override
public void run() {
startStopLock.lock();
try {
if (stopped) {
return;
}
started = true;
} finally {
startStopLock.unlock();
}
for (ConsumerRecord<String, String> record : records) {
if (stopped) {
break;
}
// process record here and make sure you catch all exceptions;
currentOffset.set(record.offset() + 1);
}
finished = true;
completion.complete(currentOffset.get());
}
public long getCurrentOffset() {
return currentOffset.get();
}
public void stop() {
startStopLock.lock();
try {
this.stopped = true;
if (!started) {
finished = true;
completion.complete(currentOffset.get());
}
} finally {
startStopLock.unlock();
}
}
public long waitForCompletion() {
try {
return completion.get();
} catch (InterruptedException | ExecutionException e) {
return -1;
}
}
public boolean isFinished() {
return finished;
}
}
private void handleFetchedRecords(ConsumerRecords<String, String> records) {
if (records.count() > 0) {
List<TopicPartition> partitionsToPause = new ArrayList<>();
// 按partition分组
records.partitions().forEach(partition -> {
List<ConsumerRecord<String, String>> consumerRecords = records.records(partition);
// 提交一个分区的数据给处理线程池
ProcessThread processThread = new ProcessThread(consumerRecords);
processThreadPool.submit(processThread);
// 记录分区与处理线程的关系,方便后面查询处理状态
activeTasks.put(partition, processThread);
});
// pause已经在处理的分区,避免同个分区的数据被多个线程同时消费,从而保证分区内数据有序处理
consumer.pause(partitionsToPause);
}
}
@Slf4j
public class ProcessThread implements Runnable {
private final List<ConsumerRecord<String, String>> records;
private final AtomicLong currentOffset = new AtomicLong();
private volatile boolean stopped = false;
private volatile boolean started = false;
private volatile boolean finished = false;
private final CompletableFuture<Long> completion = new CompletableFuture<>();
private final ReentrantLock startStopLock = new ReentrantLock();
public ProcessThread(List<ConsumerRecord<String, String>> records) {
this.records = records;
}
@Override
public void run() {
startStopLock.lock();
try {
if (stopped) {
return;
}
started = true;
} finally {
startStopLock.unlock();
}
for (ConsumerRecord<String, String> record : records) {
if (stopped) {
break;
}
// process record here and make sure you catch all exceptions;
currentOffset.set(record.offset() + 1);
}
finished = true;
completion.complete(currentOffset.get());
}
public long getCurrentOffset() {
return currentOffset.get();
}
public void stop() {
startStopLock.lock();
try {
this.stopped = true;
if (!started) {
finished = true;
completion.complete(currentOffset.get());
}
} finally {
startStopLock.unlock();
}
}
public long waitForCompletion() {
try {
return completion.get();
} catch (InterruptedException | ExecutionException e) {
return -1;
}
}
public boolean isFinished() {
return finished;
}
}
很多设计都是在实现“ 如何优雅停止处理线程 ”的情况,这里简单说明一下。不考虑进程停止这种情况的话,其实需要停止处理线程的一个主要原因就是可能发生了rebalance,这个分区给其它consumer了。这个时候当前consumer处理线程优雅的停止方式就是完成目前正在处理的那个record,然后提交offset,然后停止。注意是完成当前正在处理的record,而不是完成本次分给该线程的所有records,因为处理完所有的records可能需要的时间会比较长。前面在offset提交的时候已经提到过,手动提交offset的时候,要想处理好rebalance这种情况,需要实现 ConsumerRebalanceListener 接口。
@Slf4j
public class PollThread implements Runnable, ConsumerRebalanceListener {
private final KafkaConsumer<String, String> consumer;
private final Map<TopicPartition, ProcessThread> activeTasks = new HashMap<>();
private final Map<TopicPartition, OffsetAndMetadata> offsetsToCommit = new HashMap<>();
// 省略其它代码
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// 1. stop all tasks handling records from revoked partitions
Map<TopicPartition, ProcessThread> stoppedTask = new HashMap<>();
for (TopicPartition partition : partitions) {
ProcessThread processThread = activeTasks.remove(partition);
if (processThread != null) {
processThread.stop();
stoppedTask.put(partition, processThread);
}
}
// 2. wait for stopped task to complete processing of current record
stoppedTask.forEach((partition, processThread) -> {
long offset = processThread.waitForCompletion();
if (offset > 0) {
offsetsToCommit.put(partition, new OffsetAndMetadata(offset));
}
});
// 3. collect offsets for revoked partitions
Map<TopicPartition, OffsetAndMetadata> revokedPartitionOffsets = new HashMap<>();
for (TopicPartition partition : partitions) {
OffsetAndMetadata offsetAndMetadata = offsetsToCommit.remove(partition);
if (offsetAndMetadata != null) {
revokedPartitionOffsets.put(partition, offsetAndMetadata);
}
}
// 4. commit offsets for revoked partitions
try {
consumer.commitSync(revokedPartitionOffsets);
} catch (Exception e) {
log.warn("Failed to commit offsets for revoked partitions!", e);
}
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
// 如果分区之前没有pause过,那执行resume就不会有什么效果
consumer.resume(partitions);
}
}
- 当检测到有分区分配给当前consumer的时候,就会尝试resume这个分区,因为这个分区可能之前被其它consumer pause过。
- 当检测到有分区要被回收时,执行了下面几个操作:
查看 activeTasks ,看是否有线程正在处理这些分区的数据,有的话调用 ProcessThread的 stop 方法将这些处理线程的 stopped 标志位设置成true。同时记录找到的这些线程。
在 ProcessThread 的 run 方法里面每次循环处理record的时候都会检测上一步置位的这个 stopped 标志位,从而实现完成当前处理的record后就停止的逻辑。然后这一步就是等待这些线程处理结束,拿到处理的offset值,放到待提交offset队列 offsetsToCommit 里面。
从待提交队列里面找到要被回收的分区的offset,放到 revokedPartitionOffsets 里面。
提交 revokedPartitionOffsets 里面的offset。
当收到有某些partition要从当前consumer回收的消息的时候,就从处理线程里面找到正在处理这些分区的线程,然后通知它们处理完正在处理的那一个record之后就退出吧。当然退出的时候需要返回已处理数据的offset,然后PollThread线程提交这些分区的offset。
https://mp.weixin.qq.com/s/PnPPD1OkWmfG0kdjHte-Cg
总体而言,两种模型各有利弊,但如果Thread-Per-Consumer模型能满足需求的话,肯定是应该优先使用的,简单明了。毕竟在软件世界,在满足需求的前提下,系统越简单越好。如无必要,勿增实体。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类