

运行入口(execute.py)
我们已经知道了 Scrapy 的运行入口是 scrapy/cmdline.py 的 execute 方法
def execute(argv=None, settings=None):
"""
主要工作包括配置初始化、命令解析、爬虫类加载、运行爬虫
"""
if argv is None:
argv = sys.argv
"""兼容低版本scrapy.conf.settings的配置(代码已删),写代码方式借鉴
if settings is None and 'scrapy.conf' in sys.modules:
from scrapy import conf
if hasattr(conf, 'settings'):
settings = conf.settings
兼容低版本scrapy.conf.settings的配置
import warnings
from scrapy.exceptions import ScrapyDeprecationWarning
with warnings.catch_warnings():
warnings.simplefilter("ignore", ScrapyDeprecationWarning)
from scrapy import conf
# 校验弃用的配置项
check_deprecated_settings(settings)
parser = optparse.OptionParser(formatter=optparse.TitledHelpFormatter(), conflict_handler='resolve')
"""
# 初始化环境、获取项目配置参数 返回settings对象
if settings is None:
settings = get_project_settings()
try:
editor = os.environ["EDITOR"]
except KeyError:
pass
else:
settings["EDITOR"] = editor
# 执行环境是否在项目中 主要检查scrapy.cfg配置文件是否存在
inproject = inside_project()
# 读取commands文件夹 把所有的命令类转换为{cmd_name: cmd_instance}的字典
cmds = _get_commands_dict(settings, inproject)
# 从命令行解析出执行的是哪个命令
cmdname = _pop_command_name(argv)
if not cmdname:
_print_commands(settings, inproject)
sys.exit(0)
elif cmdname not in cmds:
_print_unknown_command(settings, cmdname, inproject)
sys.exit(2)
# 根据命令名称找到对应的命令实例
cmd = cmds[cmdname]
parser = ScrapyArgumentParser(
formatter_class=ScrapyHelpFormatter,
usage=f"scrapy {cmdname} {cmd.syntax()}",
conflict_handler="resolve",
description=cmd.long_desc(),
)
# 设置项目配置和级别为command
settings.setdict(cmd.default_settings, priority='command')
cmd.settings = settings
# 添加解析规则
cmd.add_options(parser)
# 解析命令参数,并交由Scrapy命令实例处理
opts, args = parser.parse_args(args=argv[1:])
_run_print_help(parser, cmd.process_options, args, opts)
# 初始化CrawlerProcess实例 并给命令实例添加crawler_process属性
cmd.crawler_process = CrawlerProcess(settings)
# 执行命令实例的run方法
_run_print_help(parser, _run_command, cmd, args, opts)
sys.exit(cmd.exitcode)
整个流程总结成了思维导图:
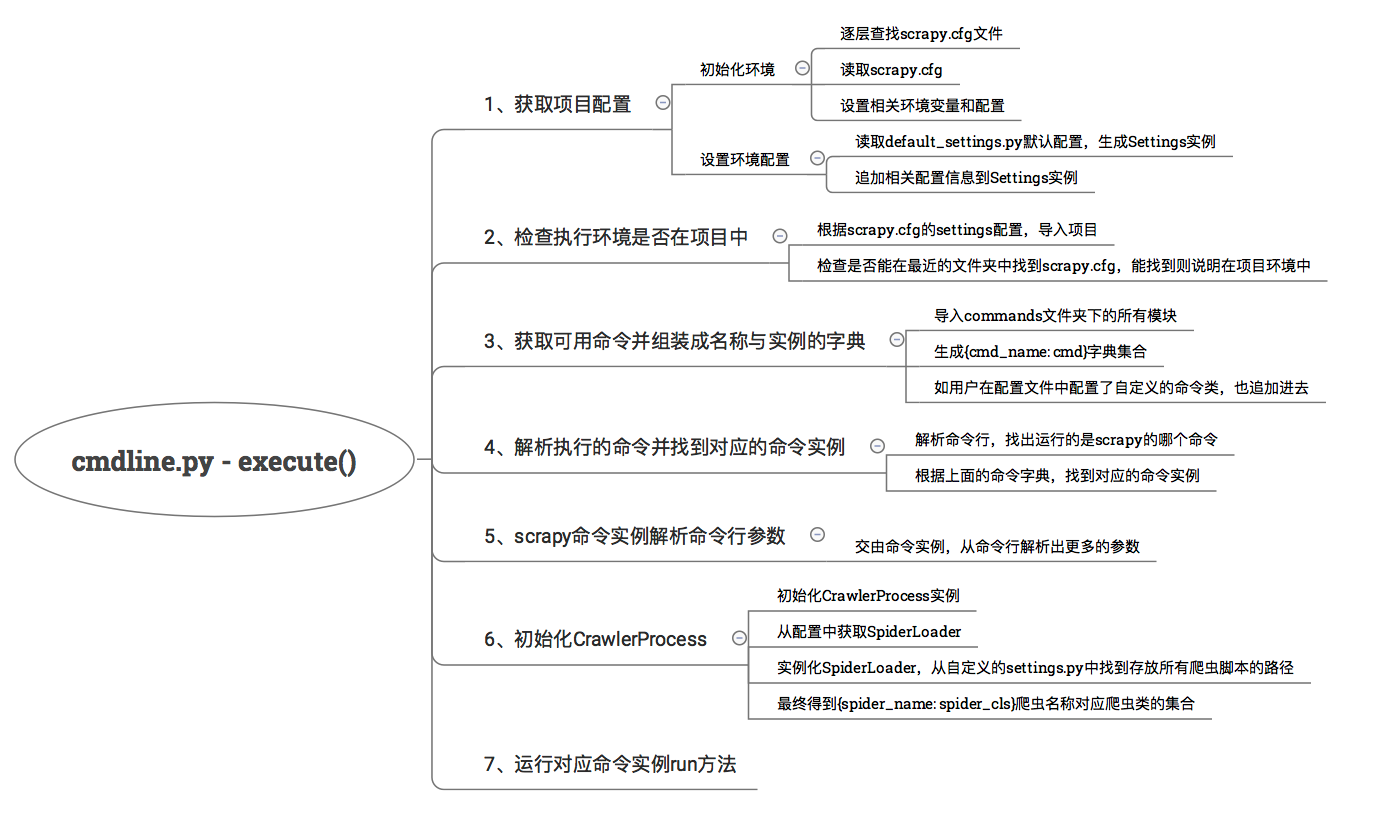
1、初始化项目配置
首先第一步,根据环境初始化配置,在这里有一些兼容低版本 Scrapy 配置的代码,我们忽略就好。我们重点来看配置是如何初始化的。这主要和环境变量和 scrapy.cfg 有关,通过调用 get_project_settings 方法,最终生成一个 Settings 实例。
def get_project_settings() -> Settings:
# 环境变量中是否有SCRAPY_SETTINGS_MODULE配置
if ENVVAR not in os.environ:
project = os.environ.get('SCRAPY_PROJECT', 'default')
# 初始化环境 找到用户配置文件settings.py 设置到环境变量SCRAPY_SETTINGS_MODULE中
init_env(project)
# 加载默认配置文件default_settings.py 生成settings实例
settings = Settings()
# 取得用户配置文件
settings_module_path = os.environ.get(ENVVAR)
# 如果有用户配置 则覆盖默认配置
if settings_module_path:
settings.setmodule(settings_module_path, priority='project')
# 如果环境变量中有其他scrapy相关配置也覆盖
pickled_settings = os.environ.get("SCRAPY_PICKLED_SETTINGS_TO_OVERRIDE")
if pickled_settings:
settings.setdict(pickle.loads(pickled_settings), priority='project')
env_overrides = {k[7:]: v for k, v in os.environ.items() if
k.startswith('SCRAPY_')}
if env_overrides:
settings.setdict(env_overrides, priority='project')
return settings
在初始配置时,会加载默认的配置文件 default_settings.py,主要逻辑在 Settings 类中。
class Settings(BaseSettings):
def __init__(self, values=None, priority='project'):
# 调用父类构造初始化
super(Settings, self).__init__()
# 把default_settings.py的所有配置set到settings实例中
self.setmodule(default_settings, 'default')
# 把attributes属性也set到settings实例中
for name, val in six.iteritems(self):
if isinstance(val, dict):
self.set(name, BaseSettings(val, 'default'), 'default')
self.update(values, priority)
可以看到,首先把默认配置文件 default_settings.py 中的所有配置项设置到 Settings 中,而且这个配置是有优先级的。
这个默认配置文件 default_settings.py 是非常重要的,我们读源码时有必要重点关注一下里面的内容,这里包含了所有组件的默认配置,以及每个组件的类模块,例如调度器类、爬虫中间件类、下载器中间件类、下载处理器类等等。
# 下载器类
DOWNLOADER = 'scrapy.core.downloader.Downloader'
# 调度器类
CHEDULER = 'scrapy.core.scheduler.Scheduler'
# 调度队列类
SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleLifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.LifoMemoryQueue'
SCHEDULER_PRIORITY_QUEUE = 'scrapy.pqueues.ScrapyPriorityQueue'
有没有感觉比较奇怪,默认配置中配置了这么多类模块,这是为什么?
这其实是 Scrapy 特性之一,它这么做的好处是:任何模块都是可替换的。
什么意思呢?例如,你觉得默认的调度器功能不够用,那么你就可以按照它定义的接口标准,自己实现一个调度器,然后在自己的配置文件中,注册自己的调度器类,那么 Scrapy 运行时就会加载你的调度器执行了,这极大地提高了我们的灵活性!
所以,只要在默认配置文件中配置的模块类,都是可替换的。
2、检查运行环境是否在项目中
初始化完配置之后,下面一步是检查运行环境是否在爬虫项目中。我们知道,scrapy 命令有的是依赖项目运行的,有的命令则是全局的。这里主要通过就近查找 scrapy.cfg 文件来确定是否在项目环境中,主要逻辑在 inside_project 方法中。
def inside_project():
# 检查此环境变量是否存在(上面已设置)
scrapy_module = os.environ.get('SCRAPY_SETTINGS_MODULE')
if scrapy_module is not None:
try:
import_module(scrapy_module)
except ImportError as exc:
warnings.warn("Cannot import scrapy settings module %s: %s" % (scrapy_module, exc))
else:
return True
# 如果环境变量没有 就近查找scrapy.cfg 找得到就认为是在项目环境中
return bool(closest_scrapy_cfg())
运行环境是否在爬虫项目中的依据就是能否找到 scrapy.cfg 文件,如果能找到,则说明是在爬虫项目中,否则就认为是执行的全局命令
3、获取组装命令实例集合
再向下看,就到了加载命令的逻辑了。我们知道 scrapy 包括很多命令,例如 scrapy crawl 、 scrapy fetch 等等,那这些命令是从哪来的?答案就在 getcommands_dict 方法中。
def _get_commands_dict(settings, inproject):
# 导入commands文件夹下的所有模块 生成{cmd_name: cmd}的字典集合
cmds = _get_commands_from_module('scrapy.commands', inproject)
cmds.update(_get_commands_from_entry_points(inproject))
# 如果用户自定义配置文件中有COMMANDS_MODULE配置 则加载自定义的命令类
cmds_module = settings['COMMANDS_MODULE']
if cmds_module:
cmds.update(_get_commands_from_module(cmds_module, inproject))
return cmds
def _get_commands_from_module(module, inproject):
d = {}
# 找到这个模块下所有的命令类(ScrapyCommand子类)
for cmd in _iter_command_classes(module):
if inproject or not cmd.requires_project:
# 生成{cmd_name: cmd}字典
cmdname = cmd.__module__.split('.')[-1]
d[cmdname] = cmd()
return d
def _iter_command_classes(module_name):
# 迭代这个包下的所有模块 找到ScrapyCommand的子类
for module in walk_modules(module_name):
for obj in vars(module).values():
if inspect.isclass(obj) and \
issubclass(obj, ScrapyCommand) and \
obj.__module__ == module.__name__:
yield obj
这个过程主要是,导入 commands 文件夹下的所有模块,最终生成一个 {cmd_name: cmd} 字典集合,如果用户在配置文件中也配置了自定义的命令类,也会追加进去。也就是说,我们自己也可以编写自己的命令类,然后追加到配置文件中,之后就可以使用自己定义的命令了。
4、解析命令
加载好命令类后,就开始解析我们具体执行的哪个命令了,解析逻辑比较简单:
5、解析命令行参数
6、初始化 CrawlerProcess
一切准备就绪,最后初始化 CrawlerProcess 实例,然后运行对应命令实例的 run 方法。
cmd.crawler_process = CrawlerProcess(settings)
_run_print_help(parser, _run_command, cmd, args, opts)
我们开始运行一个爬虫一般使用的是 scrapy crawl <spider_name>,也就是说最终调用的是 commands/crawl.py 的 run 方法:
def run(self, args, opts):
if len(args) < 1:
raise UsageError()
elif len(args) > 1:
raise UsageError("running 'scrapy crawl' with more than one spider is no longer supported")
spname = args[0]
self.crawler_process.crawl(spname, **opts.spargs)
self.crawler_process.start()
run 方法中调用了 CrawlerProcess 实例的 crawl 和 start 方法,就这样整个爬虫程序就会运行起来了。
我们先来看CrawlerProcess初始化:
class CrawlerProcess(CrawlerRunner):
def __init__(self, settings=None):
# 调用父类初始化
super(CrawlerProcess, self).__init__(settings)
# 信号和log初始化
install_shutdown_handlers(self._signal_shutdown)
configure_logging(self.settings)
log_scrapy_info(self.settings)
其中,构造方法中调用了父类 CrawlerRunner 的构造方法:
class CrawlerRunner(object):
def __init__(self, settings=None):
if isinstance(settings, dict) or settings is None:
settings = Settings(settings)
self.settings = settings
# 获取爬虫加载器
self.spider_loader = _get_spider_loader(settings)
self._crawlers = set()
self._active = set()
初始化时,调用了 _get_spider_loader方法:
def _get_spider_loader(settings):
# 读取配置文件中的SPIDER_MANAGER_CLASS配置项
if settings.get('SPIDER_MANAGER_CLASS'):
warnings.warn(
'SPIDER_MANAGER_CLASS option is deprecated. '
'Please use SPIDER_LOADER_CLASS.',
category=ScrapyDeprecationWarning, stacklevel=2
)
cls_path = settings.get('SPIDER_MANAGER_CLASS',
settings.get('SPIDER_LOADER_CLASS'))
loader_cls = load_object(cls_path)
try:
verifyClass(ISpiderLoader, loader_cls)
except DoesNotImplement:
warnings.warn(
'SPIDER_LOADER_CLASS (previously named SPIDER_MANAGER_CLASS) does '
'not fully implement scrapy.interfaces.ISpiderLoader interface. '
'Please add all missing methods to avoid unexpected runtime errors.',
category=ScrapyDeprecationWarning, stacklevel=2
)
return loader_cls.from_settings(settings.frozencopy())
这里会读取默认配置文件中的 spider_loader项,默认配置是 spiderloader.SpiderLoader类,从名字我们也能看出来,这个类是用来加载我们编写好的爬虫类的,下面看一下这个类的具体实现。
@implementer(ISpiderLoader)
class SpiderLoader(object):
def __init__(self, settings):
# 配置文件获取存放爬虫脚本的路径
self.spider_modules = settings.getlist('SPIDER_MODULES')
self._spiders = {}
# 加载所有爬虫
self._load_all_spiders()
def _load_spiders(self, module):
# 组装成{spider_name: spider_cls}的字典
for spcls in iter_spider_classes(module):
self._spiders[spcls.name] = spcls
def _load_all_spiders(self):
for name in self.spider_modules:
for module in walk_modules(name):
self._load_spiders(module)
7、运行爬虫
CrawlerProcess 初始化完之后,调用它的 crawl 方法:
def crawl(self, crawler_or_spidercls, *args, **kwargs):
# 创建crawler
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
def _crawl(self, crawler, *args, **kwargs):
self.crawlers.add(crawler)
# 调用Crawler的crawl方法
d = crawler.crawl(*args, **kwargs)
self._active.add(d)
def _done(result):
self.crawlers.discard(crawler)
self._active.discard(d)
return result
return d.addBoth(_done)
def create_crawler(self, crawler_or_spidercls):
if isinstance(crawler_or_spidercls, Crawler):
return crawler_or_spidercls
return self._create_crawler(crawler_or_spidercls)
def _create_crawler(self, spidercls):
# 如果是字符串 则从spider_loader中加载这个爬虫类
if isinstance(spidercls, six.string_types):
spidercls = self.spider_loader.load(spidercls)
# 否则创建Crawler
return Crawler(spidercls, self.settings)
这个过程会创建 Cralwer 实例,然后调用它的 crawl 方法:
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 到现在 才是实例化一个爬虫实例
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用爬虫类的start_requests方法
start_requests = iter(self.spider.start_requests())
# 执行引擎的open_spider 并传入爬虫实例和初始请求
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
if six.PY2:
exc_info = sys.exc_info()
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise
def _create_spider(self, *args, **kwargs):
return self.spidercls.from_crawler(self, *args, **kwargs)
到这里,才会对我们的爬虫类创建一个实例对象,然后创建引擎,之后调用爬虫类的 start_requests 方法获取种子 URL,最后交给引擎执行。
最后来看 Cralwer 是如何开始运行的额,也就是它的 start 方法:
def start(self, stop_after_crawl=True):
if stop_after_crawl:
d = self.join()
if d.called:
return
d.addBoth(self._stop_reactor)
reactor.installResolver(self._get_dns_resolver())
# 配置reactor的池子大小(可修改REACTOR_THREADPOOL_MAXSIZE调整)
tp = reactor.getThreadPool()
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
# 开始执行
reactor.run(installSignalHandlers=False)
在这里有一个叫做 reactor 的模块。reactor 是个什么东西呢?它是 Twisted 模块的事件管理器,我们只要把需要执行的事件注册到 reactor 中,然后调用它的 run 方法,它就会帮我们执行注册好的事件,如果遇到网络 IO 等待,它会自动帮切换到可执行的事件上,非常高效。
在这里我们不用深究 reactor 是如何工作的,你可以把它想象成一个线程池,只是采用注册回调的方式来执行事件。
到这里,Scrapy 运行的入口就分析完了,之后爬虫的调度逻辑就交由引擎 ExecuteEngine 处理了,引擎会协调多个组件,相互配合完成整个任务的执行。
总结
总结一下,Scrapy 在真正运行前,需要做的工作包括配置环境初始化、命令类的加载、爬虫模块的加载,以及命令类和参数解析,之后运行我们的爬虫类,最终,这个爬虫类的调度交给引擎处理。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律