

Scrapy是什么?
Python写的开源爬虫框架。
什么是爬虫?
就可以方便地从网上抓取你想要的内容。
- 优点:
功能强大。
哪里看出功能强大?
- 便捷地构建 request,request是异步调度和处理的
- 强大的 selector 解析response
- downloader是多线程的
- 性能,也就是抓取和解析的速度很快因为request异步和downloader多线程
- 内置的 log 日志模块
- 内置的 exception 异常处理模块
- 内置的 shell 模块 等模块
- 缺点:
scrapy是封装起来的框架,包含了下载器,解析器,日志及异常处理,基于多线程, twisted的方式处理,对于固定单个网站的爬取开发有优势,但多网站如爬取100个网站,并发及分布式处理方面,不够灵活不便调整与括展。
如何安装和使用的问题,请参考 官方网站 https://scrapy.org/
源码地址:https://github.com/scrapy/scrapy
Scrapy 有什么作用?
数据挖掘、监测和自动化测试。
资料:https://xie.infoq.cn/article/f3505fba11fe9f9615cacc6f6
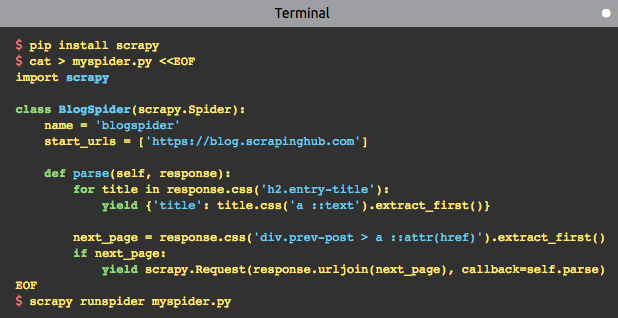
用 Scrapy 开发爬虫,只需4步:
- 使用 scrapy startproject 命令创建一个爬虫模板,或自己按模板编写爬虫代码
- 定义一个爬虫类,并继承 scrapy.Spider,重写 parse 方法
- parse 方法里编写网页解析逻辑,以及抓取路径
- 使用 scrapy runspider <spider_file.py> 运行这个爬虫
使用 Scrapy 编写简单的几行代码,就能采集到一个网站页面的数据,非常方便。
Scrapy是如何工作的?
01-架构概览
- 介绍 Scrapy 的整体架构
- 宏观上学习 Scrapy 的运行流程
架构
Scrapy 主要包含上面5大核心模块:
Engine:核心引擎,负责控制和调度各个组件,保证数据流转;Scheduler:负责管理任务、过滤任务、输出任务的调度器,存储、去重任务都在此控制;Downloader:下载器,负责在网络上下载数据,输入待下载的 URL,输出下载结果;Spiders:我们自己编写的爬虫逻辑,定义抓取意图;Item Pipeline:负责输出结构化数据,可自定义格式和输出的位置;
观察看还可以看到2个模块:
- Downloader middlewares:介于引擎和下载器之间,可以在网页在下载前、后进行逻辑处理;
- Spider middlewares:介于引擎和爬虫之间,在向爬虫输入下载结果前,和爬虫输出请求 / 数据后进行逻辑处理;
运行流程
Scrapy 内部采集流程是如何流转的?各个模块是如何交互协作,来完成整个抓取任务?
Scrapy 运行时的数据流转大概是这样的:
- 引擎从自定义爬虫中获取初始化请求(也叫种子 URL);
- 引擎把该请求放入调度器中,同时调度器向引擎获取待下载的请求;
- 调度器把待下载的请求发给引擎;
- 引擎发送请求给下载器,中间会经过一系列下载器中间件;
- 这个请求通过下载器下载完成后,生成一个响应对象,返回给引擎,这中间会再次经过一系列下载器中间件;
- 引擎接收到下载器返回的响应后,发送给爬虫,中间会经过一系列爬虫中间件,最后执行爬虫自定义的解析逻辑;
- 爬虫执行完自定义的解析逻辑后,生成结果对象或新的请求对象给引擎,再次经过一系列爬虫中间件;
- 引擎把爬虫返回的结果对象交由结果处理器处理,把新的请求通过引擎再交给调度器;
- 重复执行 1-8,直到调度器中没有新的请求处理,任务结束;
核心模块交互图:
(图中 Scrapyer 模块,也是 Scrapy 的一个核心模块,但官方的架构图没有展示出来。这个模块其实是处于 Engine、Spiders、Pipeline 之间,是连接这 3 个模块的桥梁)
核心类图
没有样式的黑色文字是类的核心属性;标有黄色样式的高亮文字是类的核心方法;
读源码的过程中,可以针对这些核心属性和方法重点关注。
Scrapy 涉及到的组件主要包括以下这些:
五大核心类: Engine、Scheduler、Downloader、Spiders、Item Pipeline;
四个中间件管理器类:DownloaderMiddlewareManager、SpiderMiddlewareManager、ItemPipelineMiddlewareManager、ExtensionManager;
其他辅助类:Request、Response、Selector;
02-Scrapy 是如何运行起来的?
https://xie.infoq.cn/article/ab683828a3bad9c931044776c
scrapy 命令从哪来?
当我们基于 Scrapy 写好一个爬虫后,想要把我们的爬虫运行起来,怎么做?非常简单,只需要执行以下命令就可以了。
scrapy crawl <spider_name>
从命令行到执行爬虫逻辑,这个过程中到底发生了什么?
装好 Scrapy 后,使用如下命令,就能找到这个命令文件:
$ which scrapy
/usr/local/bin/scrapy # 这个文件就是 Scrapy 的运行入口
打开这个文件会发现,它是一个 Python 脚本
import re
import sys
from scrapy.cmdline import execute
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw|\.exe)?$', '', sys.argv[0])
sys.exit(execute())
为什么入口点是这里呢?
答案在 Scrapy 的安装文件 setup.py 中:
from os.path import dirname, join
from setuptools import setup, find_packages
setup(
name='Scrapy',
version=version,
url='http://scrapy.org',
...
# 需要关注 ntry_points 配置,这就是调用 Scrapy 开始的地方
entry_points={ # 运行入口在这里:scrapy.cmdline:execute
'console_scripts': ['scrapy = scrapy.cmdline:execute']
},
classifiers=[
...
],
install_requires=[
...
],
)
在安装 Scrapy 的过程中,setuptools 这个包管理工具,会把上述代码生成好并放在可执行路径下,当我们使用 scrapy 命令时,就会调用 Scrapy 模块下的 cmdline.py 的 execute 方法。
同时也提一个小技巧:如何用 Python 编写一个可执行文件?
- 写一个带有 main 方法的 Python 模块(首行必须注明 Python 执行路径)
- 去掉.py后缀名
- 用(chmod +x 文件名)把这个文件权限变成可执行
- 最后通过 ./文件名 就可以执行这个 Python 文件,而不再需要通过 python <file.py> 方式执行
总结
这篇文章的代码量较多,也是 Scrapy 最为核心的抓取流程,如果你能把这块逻辑搞清楚了,那对 Scrapy 开发新的插件,或者在它的基础上进行二次开发也非常简单了。
总结一下整个抓取流程,还是用这两张图表示再清楚不过:
Scrapy 整体给我的感觉是,虽然它只是个单机版的爬虫框架,但我们可以非常方便地编写插件,或者自定义组件替换默认的功能,从而定制化我们自己的爬虫,最终可以实现一个功能强大的爬虫框架,例如分布式、代理调度、并发控制、可视化、监控等功能,它的灵活度非常高。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类