

labu一直强调要先刷二叉树!先刷二叉树!先刷二叉树!那现在就开始把。
二叉树的遍历
效果:从最简单的问题中提炼出所有二叉树题目的共性,将二叉树中蕴含的思维进行升华,反手用到 动态规划,回溯算法,分治算法,图论算法 中去。
1、二叉树的前中后序遍历是什么?只是三个顺序不同的 List 吗?
2、请分析,后序遍历有什么特殊之处?
3、请分析,为什么多叉树没有中序遍历?
二叉树的前序、中序、后序遍历框架
void traverse(TreeNode root) {
if (root == null) return;
// 前序位置
traverse(root.left);
// 中序位置
traverse(root.right);
// 后序位置
}
看traverse 函数,它在做什么事?
其实就是一个能够遍历二叉树所有节点的函数,和遍历数组或者链表本质上没有区别。
/* 迭代遍历数组 */
void traverse(int[] arr) {
for (int i = 0; i < arr.length; i++) {
}
}
/* 递归遍历数组 */
void traverse(int[] arr, int i) {
if (i == arr.length) {
return;
}
// 前序位置
traverse(arr, i + 1);
// 后序位置
}
/* 迭代遍历单链表 */
void traverse(ListNode head) {
for (ListNode p = head; p != null; p = p.next) {
}
}
/* 递归遍历单链表 */
void traverse(ListNode head) {
if (head == null) {
return;
}
// 前序位置
traverse(head.next);
// 后序位置
}
单链表和数组的遍历可以是迭代的,也可以是递归的。二叉树其实就是二叉链表,没法简单改写成迭代形式,一般都用递归。
只要是递归形式的遍历,都可以有前序位置和后序位置,分别在递归之前和递归之后。
什么是前序位置?
就是刚进入一个节点(元素)的时候
什么是后序位置?
就是即将离开一个节点(元素)的时候
如果倒序打印一条单链表上所有节点的值,怎么搞?
其实就是用递归的后序位置来实现!
二叉树前序、中序、后序位置
- 前序位置代码在刚进入二叉树节点时执行;
- 后序位置代码在将离开二叉树节点时执行;
- 中序位置代码在左子树遍历完,即将开始遍历右子树的时候执行。
来看题目——124. 二叉树中的最大路径和
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
思路:
1、为什么是在后序位置?
因为要对比左右子树的路径,你肯定要都遍历完才能取到值,不然怎么遍历。
2、最大值如何动态变化?
把每一个节点的左右子树最大值+当前节点值 与res比较出最大
3、递归函数返回什么?
题目是计算最大路径和,所以递归要返回当前节点的最大路径和,所以这里是动态规划思路,返回上一步最大+本步即可
class Solution {
int res = Integer.MIN_VALUE;
public int maxPathSum(TreeNode root) {
oneSideMax(root);
return res;
}
int oneSideMax(TreeNode root) {
if (root == null) return 0;
int left = Math.max(0, oneSideMax(root.left));
int right = Math.max(0, oneSideMax(root.right));
// 后序位置
res = Math.max(res, left + right + root.val);
return Math.max(left, right) + root.val;
}
}
BFS模板
先说下二叉树的 BFS 遍历
void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> q = new LinkedList<>();
// 1、首节点入队列,其实栈也可以 选合适的数据结构就行
q.offer(root);
// 表示当前层级
int depth = 1;
// 2. while遍历深度,往下遍历
while (!q.isEmpty()) {
int sz = q.size();
// 3.for遍历广度,从左到右遍历
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
// 将下一层节点放入队列,为while遍历深度
if (cur.left != null) q.offer(cur.left);
if (cur.right != null) q.offer(cur.right);
}
depth++;
}
}
Dijkstra算法(迪杰斯特拉) 的基础就是BFS
先说下二叉树的 BFS 遍历
void levelTraverse(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int depth = 1;
// 从上到下遍历二叉树的每一层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每一层的每个节点
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
printf("节点 %s 在第 %s 层", cur, depth);
// 将下一层节点放入队列
if (cur.left != null) {
q.offer(cur.left);
}
if (cur.right != null) {
q.offer(cur.right);
}
}
depth++;
}
}
原理,为什么whiel里会有个for循环?
因为while 循环控制一层一层往下走,for 循环利用 sz 变量控制从左到右遍历每一层二叉树节点。
基于二叉树的遍历框架,我们又可以扩展出多叉树的层序遍历框架:
void levelTraverse(TreeNode root) {
if (root == null) return;
Queue<TreeNode> q = new LinkedList<>();
q.offer(root);
int depth = 1;
// 从上到下遍历多叉树的每一层
while (!q.isEmpty()) {
int sz = q.size();
// 从左到右遍历每一层的每个节点
for (int i = 0; i < sz; i++) {
TreeNode cur = q.poll();
printf("节点 %s 在第 %s 层", cur, depth);
// 这里就不是左右了,而是用for循环,有多少children 都遍历完
for (TreeNode child : cur.children) {
q.offer(child);
}
}
depth++;
}
}
由多叉树遍历框架,进化出 BFS算法框架:
int BFS(Node start) {
Queue<Node> q = new LinkedList<>(); // 核心数据结构
Set<Node> visited= new HashSet<>(); // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录搜索的步数
while (!q.isEmpty()) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散一步 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
printf("从 %s 到 %s 的最短距离是 %s", start, cur, step);
// cur.adj() 泛指 cur 相邻的节点
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
step++;
}
}
BFS 算法框架 也是 while 循环嵌套 for 循环的形式,也用了一个 step 变量记录 for 循环执行的次数。
多用了一个 visited 集合记录走过的节点,防止走回头路。
练习题:
- 111.二叉树的最小深度:https://leetcode.cn/problems/minimum-depth-of-binary-tree/description/
- 752.打开转盘锁:https://leetcode.cn/problems/open-the-lock/description/
然后进一步进化:来到了「加权图」的场景,事情就没那么简单了。
想解决「加权图」中的最短路径问题,「步数」已经没有参考意义了,「路径的权重之和」才有意义,所以
1、BFS中的for循环可以被去掉。
2、如果想同时维护 depth 变量,让每个节点 cur 知道自己在第几层,可以想其他办法,比如新建一个 State 类,记录每个节点所在的层数。
接下来就到了:
Dijkstra 算法框架
// 输入 图 和 起点 start,计算 start 到其他节点的最短距离
int[] dijkstra(int start, List<Integer>[] graph);
比如 经过节点5 三次,每次路径和值 distFromStart 值都不一样,那取 distFromStart 最小的那次,不就是从起点 start 到节点 5 的最短路径权重了么?
Dijkstra的要素:
- Node类:2个参数+构造函数,记录当前节点id、从start到当前节点距离
Dijkstra 可以理解成一个带 dp table(或者说备忘录)的 BFS 算法:
int weight(int from, int to);// 节点 from 到节点 to 之间的边的权重
List<Integer> adj(int s); // 输入节点 s 返回 s 的相邻节点
int[] dijkstra(int start, List<Integer>[] graph) {
int V = graph.length;// 图中节点的个数
int[] distTo = new int[V];// 记录最短路径的权重,distTo[i]=节点 start 到达节点 i 的最短路径权重
Arrays.fill(distTo, Integer.MAX_VALUE);//求最小值,所以 dp table 初始化为正无穷
distTo[start] = 0;// base case,start 到 start 的最短距离就是 0
Queue<State> pq = new PriorityQueue<>((a, b) -> {// 优先级队列,distFromStart 较小的排在前面
return a.distFromStart - b.distFromStart;
});
pq.offer(new State(start, 0));// 从起点 start 开始进行 BFS
while (!pq.isEmpty()) {
State curState = pq.poll();
int curNodeID = curState.id;
int curDistFromStart = curState.distFromStart;
if (curDistFromStart > distTo[curNodeID]) {
continue;// 已存在最短路径
}
for (int nextNodeID : adj(curNodeID)) {// 将 curNode 的相邻节点装入队列
// 看看从 curNode 达到 nextNode 的距离是否会更短
int distToNextNode = distTo[curNodeID] + weight(curNodeID, nextNodeID);
if (distTo[nextNodeID] > distToNextNode) {
// 更新 dp table
distTo[nextNodeID] = distToNextNode;
// 将这个节点以及距离放入队列
pq.offer(new State(nextNodeID, distToNextNode));
}
}
}
return distTo;
}
class State {
int id;// 节点 id
int distFromStart;// 从 start 节点到当前节点的距离
State(int id, int distFromStart) {
this.id = id;
this.distFromStart = distFromStart;
}
}
练习题:
743. 网络延迟时间
有 n 个网络节点,标记为 1 到 n。
给你一个列表 times,表示信号经过有向边的传递时间。 times[i] = (ui, vi, wi),其中 ui 是源节点,vi 是目标节点, wi 是时间。现在,从某个节点 K 发出一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 -1 。
// times 记录边和权重,n 为节点个数(从 1 开始),k 为起点
// 计算从 k 发出的信号至少需要多久传遍整幅图
int networkDelayTime(int[][] times, int n, int k)
示例 1:
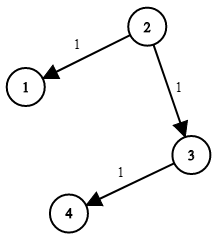
输入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
输出:2
提示:
- 1 <= k <= n <= 100,1 <= times.length <= 6000,times[i].length == 3
- 1 <= ui, vi <= n,ui != vi,0 <= wi <= 100
- 所有 (ui, vi) 对都 互不相同(即,不含重复边)
让你求所有节点都收到信号的时间,如果把时间看做举例,实际上是问「从节点 k 到其他所有节点的最短路径中,最长的那条最短路径距离是多少」,其实也就是让你算 从节点 k 出发到其他所有节点的最短路径,这样偶问题就成了标准的 Dijkstra 算法。(别忘了前提:加权有向图,没有负权重)。
所以题解的练习要拆解成3步:
1、先写出Dijkstra的标准解法
2、二维数组转图结构
3、其余逻辑
class Solution {
public int networkDelayTime(int[][] ts, int n, int k) { // 总共有n个点,k是源点
// 1.先把二维数组转化成图数据结构,用邻接表()
// 用一个数组List, graph[index] 表示从节点index可到达的next节点List,List里存next节点id和权重
List<int[]>[] graph = new LinkedList[n+1];//编号是1开始的,邻接表有n+1
// 初始化数据结构,不然操作报空指针
for (int i = 1; i < n+1; i++) graph[i] = new LinkedList<>();
// 初始化图数据 —— 邻接表
for (int[] time : ts) {
int from = time[0];
int to = time[1];
int weight = time[2];
graph[from].add(new int[]{to, weight});
}
// 2.dijkstra算法有啥作用? 计算节点K到其他节点的最短路径
int[] distTo = dijkstra(k, graph);
// 3.算出了从节点k触发到所有节点的最短距离,找最大的那个
int result = 0;
for (int i = 1; i < distTo.length; i++) {
if (distTo[i] == Integer.MAX_VALUE) return -1;// 有节点不可达,返回 -1
result = Math.max(result, distTo[i]);
}
return result;
}
// 写 dijkstra 算法
int[] dijkstra(int start, List<int[]>[] graph) {
// 声明最短距离数组,并初始化
int[] distTo = new int[graph.length];
Arrays.fill(distTo, Integer.MAX_VALUE);
distTo[start] = 0;
// BFS数据结构
// 优先级队列(堆排序),小排在前,优化效率。用普通列表也可以
Queue<Node> queue = new PriorityQueue<>((a, b) -> {
return a.distFromStart - b.distFromStart;
});
queue.offer(new Node(start, 0));
while (!queue.isEmpty()) {
Node currNode = queue.poll();
int currNodeId = currNode.id;
int curDistFromStart = currNode.distFromStart;
// 剪枝:贪心算法理念,当前路线距离和 大于存的路径,不是最短那条路,换个
if (curDistFromStart > distTo[currNodeId]) continue;
// 当前节点可以到达的节点
for (int[] nextArray: graph[curNodeId]) {
// 计算最短距离
int nextNodeId = nextArray[0];
int distToNextNode = distTo[curNodeId] + nextArray[1];
// 最短路径数组的下节点距离 大于 当前路径最小和 更新
if (distTo[nextNodeId] > distToNextNode) {
distTo[nextNodeId] = distToNextNode;
queue.offer(new Node(nextNodeId, distToNextNode));
}
}
}
return distTo;
}
}
class Node {
int id;// 当前节点id
int distFromStart;// 从 start 节点到当前节点的距离
Node(int id, int distFromStart) {
this.id = id;
this.distFromStart = distFromStart;
}
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类