

shell 速查手册
说明1:nohup,该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思,不挂断地运行命令。
说明2:/dev/null代表linux的空设备文件,所往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台 /proc/self/fd/1 )
错误输出2:输出到屏幕(即控制台 /proc/self/fd/2)
后台运行不需要日志:nohup [命令] > /dev/null &
正确和错误日志写入一个文件:命令 >> 文件 2 >&1
正确和错误日志分别写入两个文件:命令 >> 文件名 2>>文件名
一、grep(过滤行):按照正则过滤
grep+参数+查找内容+源文件
-i 忽略大小写 -v 反向查找 -n 输出行号
grep -E 正则表达式 文件名
1.判断一个文件是否存在
[ -f /opt/module ]
echo $?
文件夹,返回1(false)
2.Shell脚本里如何检查一个文件是否存在?如果不存在该如何处理?
#!/bin/bash
if [ -f file.txt ]; then
echo "文件存在!"
else
echo "文件不存在!"
fi
3.统计正在连接的网络连接数量:netstat -an | grep "ESTABLISHED" | wc -l
4.rpm -qa | grep mysql | xargs sudo rpm -e xargs:将前面的结果作为后面的参数
二、cut(操作列):只能指定分隔符或者Tab分割
cut -d 符号 -f 列号 文件名

1.请用shell脚本写出查找当前文件夹(/home下所的文本文件内容中包含字符”shen”的文件名称
[atguigu@hadoop102 datas]
grep -r "shen" /home | cut -d ":" -f 1
/home/atguigu/datas/sed.txt
/home/atguigu/datas/cut.txt
三、sed:
处理文本:sed /行号/a增s换d删/个数 文件名
/^R.*/:R开头的行
/.*T$/:T结尾的行
^$:空行
*:匹配单个字符多次 zo*-->zoo-->zooo<-->zozo(反例)
.:匹配任意一个字符一次
.*:匹配任意字符串
-n:只输出处理的行
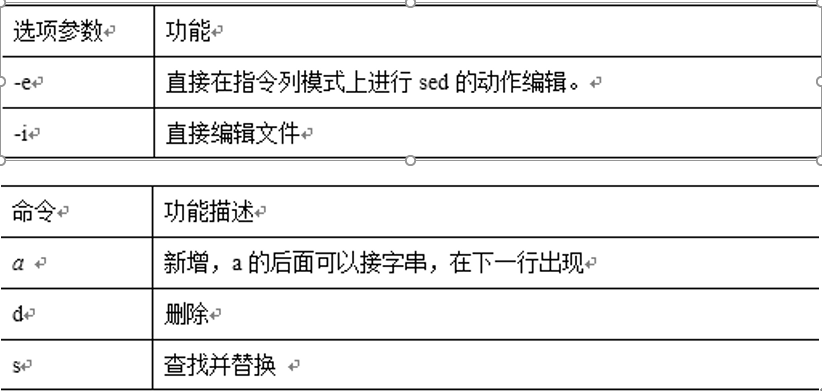
1.删除文件中的第二行到第四行
sed '2,4d' student.txt
2.
四、awk编程:支持任意分隔符
awk '条件1{动作1} 条件2{动作2}...' 文件名
awk -F :, 行切分规则 '/行匹配规则/操作 /行匹配规则/操作' 文件名
NF是每一行切割的列的个数,假设列是文件路径:
/opt/module/hadoop-2.7.2/share/hadoop/httpfs/tomcat/bin/bootstrap.jar
那么$NF就是最后一列的值,也就是文件名称
BEGIN{} END{}

1.使用Linux命令查询file1中空行所在的行号答案:
awk '/^$/{print NR}' file1.txt
2.文件chengji.txt内容如下:
张三 40
李四 50
王五 60
使用Linux命令计算第二列的和并输出
[atguigu@hadoop102 datas]$
cat chengji.txt | awk -F " " '{sum+=$2} END{print sum}'
150
3.shell脚本里统计一个目录下(包含子目录)有多少个java文件?如何取得每一个java文件的名称(不包含路径)
find /opt/module/hadoop/ -name *.jar | awk 'END{print NR}'
find /opt/module/hadoop/ -name *.jar | awk -F "/" '{print $NF}'
4.找到 根分区 占用的空间
df -h | grep "dev/sda3" | awk '{print $5}' | cut -d "%" -f 1
5.统计平均成绩 >=87 的人员姓名

grep -v "Name" student.txt | awk '$6 >= 86 {print $2}'
6.找到系统中的用户(不包含伪用户)
cat /etc/passwd | grep "/bin/bash" awk 'BEGIN{FS=":"} {print $1}'
五、sort:
sort-->-t 行切分规则-->-k 按第几列切分-->-n是否按照字母排序

1.用shell写一个脚本,对文本中无序的一列数字排序
sort -n test.txt|awk '{a+=$0;print $0}END{print "SUM="a}'
六、参考:
if [ $# -lt 1 ]
then
echo 参数不足!
exit
fi
$(( + )) 用于计算数值
'' 字符串
"" 执行引号中的代码
$() 引用系统命令
$ 调用变量的值
$? 最后一次执行的命令的返回状态
set或者env 显示系统变量

