kafka基础
认识Kafaka
最初的定义:消息队列系统
0.10.0版本的定义:分布式流处理平台,发布-订阅消息队列,存储功能、流处理框架
3.x后的定义:分布式流平台,数据管道/集成、流分析
kafka的优势
- 吞吐量高、性能好
- 伸缩性好
- 高容错、高可靠
- 与大数据生态精密结合
kafka的作用
- 高并发环境下的缓冲、消峰
- 解耦:支持不同的数据来源和不同的目的地
- 异步通信:避免同步时的等待时间
两种模式
- 点对点:消费者主动拉取数据,并在消费后删除
- 发布-订阅(常用):同时有多个Topic、多个消费者,独立并行消费,不删除数据
Kafka基础架构
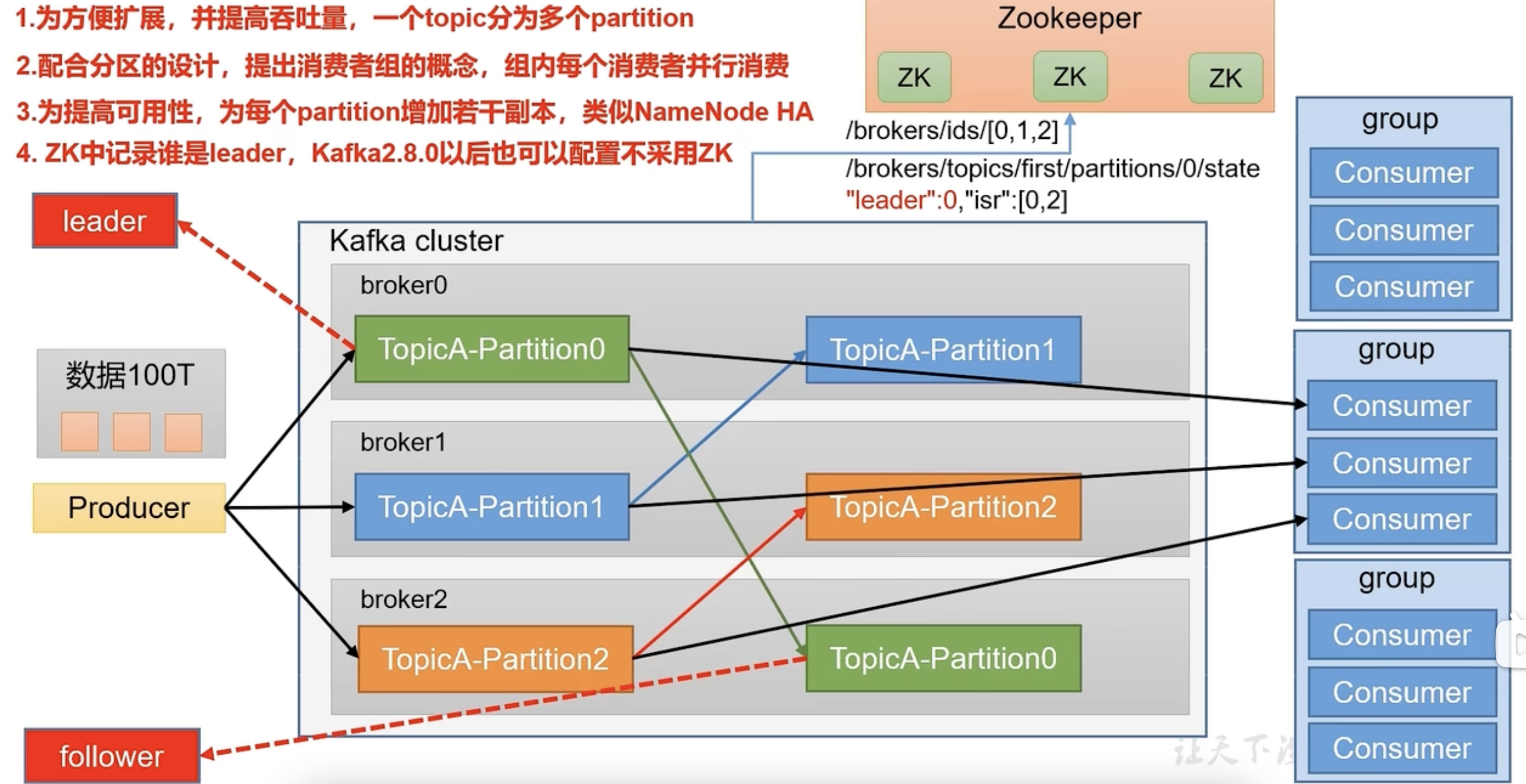
生产者:
Topic:
一个Topic可分为多个Partition分区,便于存储海量数据。为了保证可用性,每个分区又有若干个副本,副本分为leader和follower。生产和消费的处理对象只针对leader,若leader挂掉了,follower有条件成为新的leader
消费者:对应Topic的设计,消费端也有消费者组,组内每个消费者并行消费,每个分区只能由一个消费者消费
Zookeeper:存储kafka中的集群上下线,包括记录每个分区下谁是leader副本(kafka2.8.0后可不用zk)
搭建Kafka
官网下载链接:https://kafka.apache.org/downloads ,这里用的教程一样的3.0.0版本,下载后调整配置
# config/server.properties
broker.id=0 #每个分区的brokerID都需要不同
log.dirs=/home/csop/kafka/logs # 默认的日志保存在临时目录中,有清除的风险
zookeeper.connect=CentOS-001:2181,CentOS-002:2181,CentOS-003:2181/kafka # 在zk里添加一个kafka子目录,便于管理
# ~/.bash_profile环境变量配置
export KAFKA_HOME=/home/csop/kafka
export PATH=$PATH:$KAFKA_HOME/bin
启动kafka之前需要先启动zookeeper,而zk的启动环境需要jdk,因此首先需要下载好环境问题。
先启动zookeeper,再启动 kafka,但启动kafka时需要用到config中的参数文件:
zk.sh # -deamon表示以守护进程启动
bin/kafka-server-start -demon ../config/server.properties
单节点启动
创建一个 test Topic,拥有一个分区和一个副本
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
分别用2个终端开启一个生产者和消费者,进行消息的发送与接收
# 生产者:执行完成后,可从标准输入中获取输入
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
>hello!
>你好
# 消费者
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
>hello!
>你好
单节点启停脚本
#启动zk、kafka脚本
#!/bin/bash
ip=`ifconfig -a|grep inet|grep -v 127.0.0.1|grep -v inet6|awk '{print $2}'|tr -d "addr:"`
echo '##########开始启动 ${ip} 节点》...#########'
~/apache-zookeeper-3.8.3-bin/bin/zkServer.sh start
ZkProc=$(ps -ef |grep -w zookeeper|wc -l)
if [ ${ZkProc} -gt 1 ];then
echo '#############启动Zookeeper成功!##############'
else
echo '#############启动Zookeeper失败!##############'
fi
sleep 3
~/kafka_2.11-1.0.0/bin/kafka-server-start.sh -daemon ~/kafka_2.11-1.0.0/config/server.properties
KafkaProc=$(ps -ef |grep -w kafka|wc -l)
if [ ${KafkaProc} -gt 1 ];then
echo '#############启动Kafka成功!##############'
else
echo '#############启动Kafka失败!##############'
fi
#关闭zk、kafka脚本
#!/bin/bash
echo '#################开始关闭节点...###############'
~/kafka_2.11-1.0.0/bin/kafka-server-stop.sh
~/kafka_2.11-1.0.0/bin/zookeeper-server-stop.sh
sleep 3
kafkaProc=$(ps -ef |grep -w kafka|wc -l)
if [ ${kafkaProc} -le 1 ];then
echo '#############关闭Kafka成功!##############'
else
echo '#############关闭Kafka失败!##############'
fi
ZkProc=$(ps -ef |grep -w zookeeper|wc -l)
if [ ${ZkProc} -le 1 ];then
echo '#############关闭Zookeeper成功!##############'
else
echo '#############关闭Zookeeper失败!##############'
fi
kafka默认stop脚本有概率无法关闭,需手动将kafka-server-stop.sh中部分代码更新:
PIDS=$(jps -lm | grep -i 'kafka.Kafka' | awk '{print $1}')
kill -s KILL $PIDS
06,启动还没有复现
本文来自博客园,作者:我永远喜欢石原里美,转载请注明原文链接:https://www.cnblogs.com/yuan-zhou/p/17710259.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号