python基础之模块
一、模块概述
-
定义:
-
一个py文件称为一个模块(module);
-
含一个或多个py文件的文件夹,称为包(package)。
【注意】在包(文件夹)中有一个默认内容为空的__init__.py的文件,一般用于描述当前包的信息(在导入他下面的模块时,也会自动加载执行)。
- py2必须有,如果没有导入包就会失败。
- py3可有可无。
【注意】pycharm中创建包可以使用new- python package,而不是以前使用的创建文件夹功能。
-
-
分类:
- 自定义模块(包):自己编写
- 第三方模块:别人编写好的,拿来就能用
- 内置模块:python定义好的,拿来就能用
-
应用场景:
在开发简单的程序时,使用一个py文件就可以搞定,如果程序比较庞大,需要10w行代码,此时为了代码结构清晰,将功能按照某种规则拆分到不同的py文件中,使用时再去导入即可。另外,当其他项目也需要此项目的某些模块时,也可以直接把模块拿过去使用,增加重用性。
二、导入模块或包
-
定义:导入,其实就是将模块或包加载的内存中,以后再去内存中去拿来使用。其实本质上,当从一个模块导入一个函数时,python解释器实际上是将整个模块中的所有函数都加载到了内存中,如果后续又导入了这个模块的其他函数,python解释器并不会再把该模块重新加载一遍,而是直接在内存中找到该函数。当定义好一个模块或包之后,如果想要使用其中定义的功能,必须要先导入,然后再能使用。
-
导入时的路径:在Python内部默认设置了一些路径,导入模块或包时,都会按照指定顺序逐一去特定的路径查找。
想要导入任意的模块和包,都必须写在如下路径下,才能被找到,也可以手动添加搜索目录:import sys print(sys.path) # 执行结果:sys.path: [ '当前执行脚本所在的目录', /Users/wupeiqi/PycharmProjects/luffyCourse/day14/bin /Users/wupeiqi/PycharmProjects/luffyCourse/day14 '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_display', '/Library/Frameworks/Python.framework/Versions/3.9/lib/python39.zip', '/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9', '/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/lib-dynload', '/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages', '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_matplotlib_backend' ] sys.path.append('路径A') # 手动添加路径A import xxxxx # 导入路径A下的一个xxxxx模块 -
注意:
- 自定义模块名称不能与内置和第三方同名,不然可能导入内置或第三方模块失败;
- python解释器会自动把当前模块的所在目录添加到sys.path中;
- 如果执行文件嵌套在内层目录,就需要自己手动在sys.path中添加路径;
- pycharm中默认会将项目目录加入到sys.path中,因此pycharm会自动做这个添加操作,因此在pycharm中可以正常运行,但是脱离了pycharm,程序运行可能会出错。
三、模块导入方式
3.1 第一类:import xxxx (开发中,一般多用于导入sys.path目录下的一个py文件,可导入一个包或模块)
- 导入模块
- import 模块名
- import 包名.模块名
- 导入包
- import 包名
- import 包名.子包名
3.2 第二类:from xxx import yyy (常用,一般适用于多层嵌套和导入包中某个模块或模块中某个成员的情况。)
- 导入函数
- from 模块名 import 函数名
- from 模块名 import *
- from 包名.模块名 import 函数名
- 导入模块(至少一个嵌套)
- from 包名 import 模块名
- from 包名.子包名 import 模块名
- 导入包(至少一个嵌套)
- from 包名 import 子包名
3.3 应用场景
- import应用场景:项目根目录的包模块级别的导入。
- from import应用场景:成员、嵌套的包和模块。
- 两种都支持as别名,名称更短,减少输入;另外,防止重名,譬如两个模块种有相同名字的函数,同时导入的情况下,如果不as起不同的名字,后导入的函数会覆盖先导入的函数。
from xxx.xxx import xx as xo
import x1.x2 as pg
除此之外,有了as的存在,让 import xx.xxx.xxxx.xxx 在调用执行时,会更加简单(不常用,了解即可)。
-
原来
import commons.page v1 = commons.page.pagination() -
现在
import commons.page as pg v1 = pg.pagination()
3.4 相对导入 . / ..(不推荐使用)
from .wechat import send_wechat # 从同级wechat中导入
from ..page import pagination # 从上级模块page中导入
【切记】相对导入只能用在包中的py文件中(即:嵌套在文件中的py文件才可以使用,项目根目录下无法使用)。
3.5 主文件
-
主文件,其实就是在程序执行的入口文件。我们通常是执行 run.py 去运行程序,其他的py文件都是一些功能代码。当我们去执行一个文件时,文件内部的 __name__变量的值为 main。
-
执行一个py文件时
__name__ = "__main__" -
导入一个py文件时
__name__ = "模块名"
【总结】当测试一个模块都功能时,也会加入if name == 'main': 以便测试代码可用性,测试完毕后可能忘记删除,当遇到根目录下面有多个文件中有这样的主文件判断时,去看里面具体都代码,主文件执行都逻辑一般比较复杂,而辅助文件一般逻辑简单,只是测试功能而已。
另外,主文件都执行代码块也不建议写太多代码,可以将执行代码块也编写成一个函数,在判断语句后面直接执行这个函数即可,这就是开发的规范。
四、第三方模块
Python内部提供的模块有限,所以在平时在开发的过程中,经常会使用第三方模块。而第三方模块必须要先安装才能可以使用,使用第三方模块的行为就是去用别人写好并开源出来的py代码,这样自己拿来就用,不必重复造轮子了。
4.1 三种安装方式
4.1.1 pip (最常用)
这是Python中最最最常用的安装第三方模块的方式。
pip其实是一个第三方模块包管理工具,默认安装Python解释器时自动会安装,默认目录:
MAC系统,即:Python安装路径的bin目录下
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3.9
Windows系统,即:Python安装路径的scripts目录下
C:\Python39\Scripts\pip3.exe
C:\Python39\Scripts\pip3.9.exe
提示:为了方便在终端运行pip管理工具,我们也会把它所在的路径添加到系统环境变量中。
pip3 install 模块名称
如果你的电脑上某个写情况没有找到pip,也可以自己手动安装:
-
下载
get-pip.py文件,到任意目录地址:https://bootstrap.pypa.io/get-pip.py -
打开终端进入目录,用Python解释器去运行已下载的
get-pip.py文件即刻安装成功。
使用pip去安装第三方模块也非常简单,只需要在自己终端执行:pip install 模块名称 即可。
默认安装的是最新的版本,如果想要指定版本:
pip3 install 模块名称==版本
例如:
pip3 install django==2.2
pip更新:
如果想要升级为最新的版本,可以在终端执行他提示的命令:
/Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 -m pip install --upgrade pip
pip默认是去 https://pypi.org 去下载第三方模块(本质上就是别人写好的py代码),国外的网站速度会比较慢,为了加速可以使用国内的豆瓣源。
-
一次性使用
pip3.9 install 模块名称 -i https://pypi.doubanio.com/simple/ -
永久使用
-
配置
# 在终端执行如下命令 pip3.9 config set global.index-url https://pypi.doubanio.com/simple/ # 执行完成后,提示在我的本地文件中写入了豆瓣源,以后再通过pip去安装第三方模块时,就会默认使用豆瓣源了。 # 自己以后也可以打开文件直接修改源地址。 Writing to /Users/wupeiqi/.config/pip/pip.conf -
使用
pip3.9 install 模块名称
-
写在最后,也还有其他的源可供选择(豆瓣应用广泛)。
国内常用源镜像地址(注意末尾的/,有些源没有/)
清华 https://pypi.tuna.tsinghua.edu.cn/simple
阿里云 http://mirrors.aliyun.com/pypi/simple/
豆瓣(douban) https://pypi.doubanio.com/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn
华中理工大学 http://pypi.hustunique.com/
山东理工大学 http://pypi.sdutlinux.org/
4.1.2 源码安装
如果要安装的模块在pypi.org中不存在 或 因特殊原因无法通过pip install 安装时,可以直接下载源码,然后基于源码安装,例如:
-
下载requests源码(压缩包zip、tar、tar.gz)并解压。
下载地址:https://pypi.org/project/requests/#files -
进入目录
-
执行编译和安装命令
python3 setup.py build python3 setup.py install
【总结】下载都源码包内一定会有 setup.py 文件,然后通过上述命令安装即可。本质上跟pip的安装过程一直,几乎不用这种方式。
【怎么确定开发过程中适合使用哪个第三方包呢?】答案:搜索。例如:百度搜索,python操作mp4,一般能搜到使用哪个包。知道用哪个包后,可以去http://pypi.org 网站搜索这个包都介绍和使用方法等等。另外,参考官方文档、做各种比较,选出最合适的第三方包使用即可。
4.1.3 wheel 安装
wheel是Python的第三方模块包的文件格式的一种,我们也可以基于wheel去安装一些第三方模块。
-
安装wheel格式支持,这样pip再安装第三方模块时,就可以处理wheel格式的文件了。
pip3.9 install wheel -
下载第三方的包(wheel格式),例如:https://pypi.org/project/requests/#files
-
进入下载目录,在终端基于pip直接安装
pip install requests-2.25.1-py2.py3-none-any.whl
无论通过什么形式去安装第三方模块,默认模块的安装路径在:
Mac系统:
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages
Windows系统:
C:\Python39\Lib\site-packages\
提醒:这个目录在sys.path中,所以我们直接在代码中直接导入下载的第三方包是没问题的。
五、内置模块
5.1 os
import os
# 1. 获取当前脚本绝对路径
"""
abs_path = os.path.abspath(__file__)
print(abs_path)
"""
# 2. 获取当前文件的上级目录
"""
base_path = os.path.dirname( os.path.dirname(路径) )
print(base_path)
"""
# 3. 路径拼接
"""
p1 = os.path.join(base_path, 'xx')
print(p1)
p2 = os.path.join(base_path, 'xx', 'oo', 'a1.png')
print(p2)
"""
# 4. 判断路径是否存在
"""
exists = os.path.exists(p1)
print(exists)
"""
# 5. 创建文件夹
"""
os.makedirs(路径)
"""
"""
path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
if not os.path.exists(path):
os.makedirs(path)
"""
# 6. 是否是文件夹
"""
file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu.png')
is_dir = os.path.isdir(file_path)
print(is_dir) # False
folder_path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
is_dir = os.path.isdir(folder_path)
print(is_dir) # True
"""
# 7. 删除文件或文件夹
"""
os.remove("文件路径")
"""
"""
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
"""
- listdir,查看目录下所有的文件
- walk,查看目录下所有的文件(含子孙文件)
import os
"""
data = os.listdir("/Users/wupeiqi/PycharmProjects/luffyCourse/day14/commons")
print(data)
# ['convert.py', '__init__.py', 'page.py', '__pycache__', 'utils.py', 'tencent']
"""
"""
要遍历一个文件夹下的所有文件,例如:遍历文件夹下的所有mp4文件
"""
data = os.walk("/Users/wupeiqi/Documents/视频教程/路飞Python/mp4")
for path, folder_list, file_list in data:
for file_name in file_list:
file_abs_path = os.path.join(path, file_name)
ext = file_abs_path.rsplit(".",1)[-1]
if ext == "mp4":
print(file_abs_path)
【补充】
方法 说明
os.path.abspath(path) 返回绝对路径
os.path.basename(path) 返回文件名
os.path.commonprefix(list) 返回list(多个路径)中,所有path共有的最长的路径
os.path.dirname(path) 返回文件路径
os.path.exists(path) 路径存在则返回True,路径损坏返回False
os.path.lexists 路径存在则返回True,路径损坏也返回True
os.path.expanduser(path) 把path中包含的"~"和"~user"转换成用户目录
os.path.expandvars(path) 根据环境变量的值替换path中包含的"$name"和"${name}"
os.path.getatime(path) 返回最近访问时间(浮点型秒数)
os.path.getmtime(path) 返回最近文件修改时间
os.path.getctime(path) 返回文件 path 创建时间
os.path.getsize(path) 返回文件大小,如果文件不存在就返回错误
os.path.isabs(path) 判断是否为绝对路径
os.path.isfile(path) 判断路径是否为文件
os.path.isdir(path) 判断路径是否为目录
os.path.islink(path) 判断路径是否为链接
os.path.ismount(path) 判断路径是否为挂载点
os.path.join(path1[, path2[, ...]]) 把目录和文件名合成一个路径
os.path.normcase(path) 转换path的大小写和斜杠
os.path.normpath(path) 规范path字符串形式
os.path.realpath(path) 返回path的真实路径
os.path.relpath(path[, start]) 从start开始计算相对路径
os.path.samefile(path1, path2) 判断目录或文件是否相同
os.path.sameopenfile(fp1, fp2) 判断fp1和fp2是否指向同一文件
os.path.samestat(stat1, stat2) 判断stat tuple stat1和stat2是否指向同一个文件
os.path.split(path) 把路径分割成 dirname 和 basename,返回一个元组
os.path.splitdrive(path) 一般用在 windows 下,返回驱动器名和路径组成的元组
os.path.splitext(path) 分割路径中的文件名与拓展名
os.path.splitunc(path) 把路径分割为加载点与文件
os.path.walk(path, visit, arg) 遍历path,进入每个目录都调用visit函数,visit函数必须有3个参数(arg, dirname, names),dirname表示当前目录的目录名,names代表当前目录下的所有文件名,args则为walk的第三个参数
os.path.supports_unicode_filenames 设置是否支持unicode路径名
5.2 shutil
import shutil
# 1. 删除文件夹
"""
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
"""
# 2. 拷贝文件夹
"""
shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/","/Users/wupeiqi/PycharmProjects/CodeRepository/files")
"""
# 3.拷贝文件
"""
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/")
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/x.png")
"""
# 4.文件或文件夹重命名
"""
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png")
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/files","/Users/wupeiqi/PycharmProjects/CodeRepository/images")
"""
# 5. 压缩文件
"""
# base_name,压缩后的压缩包文件
# format,压缩的格式,例如:"zip", "tar", "gztar", "bztar", or "xztar".
# root_dir,要压缩的文件夹路径
"""
# shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files')
# 6. 解压文件
"""
# filename,要解压的压缩包文件
# extract_dir,解压的路径
# format,压缩文件格式
"""
# shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')
5.3 sys
import sys
# 1. 获取解释器版本
"""
print(sys.version)
print(sys.version_info)
print(sys.version_info.major, sys.version_info.minor, sys.version_info.micro)
"""
# 2. 导入模块路径
"""
print(sys.path)
"""
- argv,执行脚本时,python解释器后面传入的参数
import sys
print(sys.argv)
# [
# '/Users/wupeiqi/PycharmProjects/luffyCourse/day14/2.接受执行脚本的参数.py'
# ]
# [
# "2.接受执行脚本的参数.py"
# ]
# ['2.接受执行脚本的参数.py', '127', '999', '666', 'wupeiqi']
# 例如,请实现下载图片的一个工具。
def download_image(url):
print("下载图片", url)
def run():
# 接受用户传入的参数
url_list = sys.argv[1:]
for url in url_list:
download_image(url)
if __name__ == '__main__':
run()
5.4 random
import random
# 1. 获取范围内的随机整数
v = random.randint(10, 20)
print(v)
# 2. 获取范围内的随机小数
v = random.uniform(1, 10)
print(v)
# 3. 随机抽取一个元素
v = random.choice([11, 22, 33, 44, 55])
print(v)
# 4. 随机抽取多个元素
v = random.sample([11, 22, 33, 44, 55], 3)
print(v)
# 5. 打乱顺序
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
random.shuffle(data)
print(data)
5.5 hashlib
import hashlib
hash_object = hashlib.md5()
hash_object.update("武沛齐".encode('utf-8'))
result = hash_object.hexdigest()
print(result)
import hashlib
hash_object = hashlib.md5("iajfsdunjaksdjfasdfasdf".encode('utf-8'))
hash_object.update("武沛齐".encode('utf-8'))
result = hash_object.hexdigest()
print(result)
【MD5 解密】http://cmd5.com,通过撞库解密
5.6 json
json模块,是python内部的一个模块,可以将python的数据格式 转换为json格式的数据,也可以将json格式的数据转换为python的数据格式。
json格式,是一个数据格式(本质上就是个字符串,常用语网络数据传输)
# Python中的数据类型的格式
data = [
{"id": 1, "name": "武沛齐", "age": 18},
{"id": 2, "name": "alex", "age": 18},
('wupeiqi',123),
]
# JSON格式
value = '[{"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18},["wupeiqi",123]]'
5.6.1 核心功能
json格式的作用?
跨语言数据传输,例如:
A系统用Python开发,有列表类型和字典类型等。
B系统用Java开发,有数组、map等的类型。
语言不同,基础数据类型格式都不同。
为了方便数据传输,大家约定一个格式:json格式,每种语言都是将自己数据类型转换为json格式,也可以将json格式的数据转换为自己的数据类型。
Python数据类型与json格式的相互转换:
-
数据类型 -> json ,一般称为:序列化
import json data = [ {"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ] res = json.dumps(data) print(res) # '[{"id": 1, "name": "\u6b66\u6c9b\u9f50", "age": 18}, {"id": 2, "name": "alex", "age": 18}]' res = json.dumps(data, ensure_ascii=False) print(res) # '[{"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}]' -
json格式 -> 数据类型,一般称为:反序列化
import json data_string = '[{"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}]' data_list = json.loads(data_string) print(data_list)
5.6.2 类型要求
python的数据类型转换为 json 格式,对数据类型是有要求的,默认只支持:
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
data = [
{"id": 1, "name": "武沛齐", "age": 18},
{"id": 2, "name": "alex", "age": 18},
]
其他类型如果想要支持,需要自定义JSONEncoder 才能实现【目前只需要了解大概意思即可,以后项目开发中用到了还会讲解。】,例如:
import json
from decimal import Decimal
from datetime import datetime
data = [
{"id": 1, "name": "武沛齐", "age": 18, 'size': Decimal("18.99"), 'ctime': datetime.now()},
{"id": 2, "name": "alex", "age": 18, 'size': Decimal("9.99"), 'ctime': datetime.now()},
]
class MyJSONEncoder(json.JSONEncoder):
def default(self, o):
if type(o) == Decimal:
return str(o)
elif type(o) == datetime:
return o.strftime("%Y-%M-%d")
return super().default(o)
res = json.dumps(data, cls=MyJSONEncoder)
print(res)
5.6.3 其他功能
json模块中常用的是:
-
json.dumps,序列化生成一个字符串。 -
json.loads,发序列化生成python数据类型。 -
json.dump,将数据序列化并写入文件(不常用)import json data = [ {"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ] file_object = open('xxx.json', mode='w', encoding='utf-8') json.dump(data, file_object) file_object.close() -
json.load,读取文件中的数据并反序列化为python的数据类型(不常用)import json file_object = open('xxx.json', mode='r', encoding='utf-8') data = json.load(file_object) print(data) file_object.close()
5.7 时间处理
-
UTC/GMT:世界时间
-
本地时间:本地时区的时间。
Python中关于时间处理的模块有两个,分别是time和datetime。
1.2.1 time
import time
# 获取当前时间戳(自1970-1-1 00:00)
v1 = time.time()
print(v1)
# 时区
v2 = time.timezone
# 停止n秒,再执行后续的代码。
time.sleep(5)
1.2.2 datetime
在平时开发过程中的时间一般是以为如下三种格式存在:
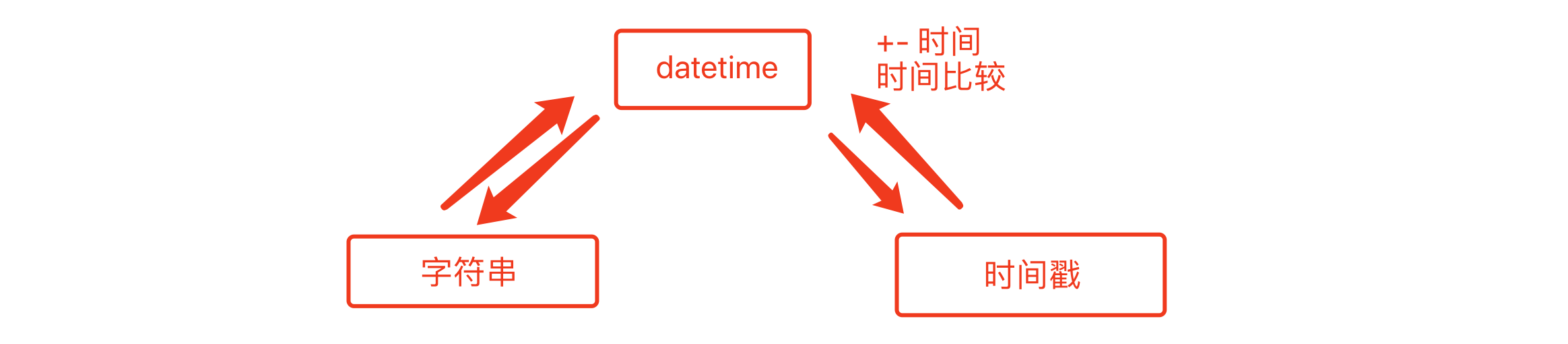
-
datetime
from datetime import datetime, timezone, timedelta v1 = datetime.now() # 当前本地时间 print(v1) tz = timezone(timedelta(hours=7)) # 当前东7区时间 v2 = datetime.now(tz) print(v2) v3 = datetime.utcnow() # 当前UTC时间 print(v3)from datetime import datetime, timedelta v1 = datetime.now() print(v1) # 时间的加减 v2 = v1 + timedelta(days=140, minutes=5) print(v2) # datetime类型 + timedelta类型from datetime import datetime, timezone, timedelta v1 = datetime.now() print(v1) v2 = datetime.utcnow() # 当前UTC时间 print(v2) # datetime之间相减,计算间隔时间(不能相加) data = v1 - v2 print(data.days, data.seconds / 60 / 60, data.microseconds) # datetime类型 - datetime类型 # datetime类型 比较 datetime类型 -
字符串
# 字符串格式的时间 ---> 转换为datetime格式时间 text = "2021-11-11" v1 = datetime.strptime(text,'%Y-%m-%d') # %Y 年,%m,月份,%d,天。 print(v1)# datetime格式 ----> 转换为字符串格式 v1 = datetime.now() val = v1.strftime("%Y-%m-%d %H:%M:%S") print(val) -
时间戳
# 时间戳格式 --> 转换为datetime格式 ctime = time.time() # 11213245345.123 v1 = datetime.fromtimestamp(ctime) print(v1)# datetime格式 ---> 转换为时间戳格式 v1 = datetime.now() val = v1.timestamp() print(val)
5.8 正则表达式
当给你一大堆文本信息,让你提取其中的指定数据时,可以使用正则来实现。例如:提取文本中的邮箱和手机号
import re
text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀"
phone_list = re.findall("1[3|5|8|9]\d{9}", text)
print(phone_list)
5.8.1 正则表达式
1. 字符相关
【1】元字符(Metacharacters)
元字符是具有特殊含义的字符。
| 元字符 | 描述 |
|---|---|
| [] | 匹配一个中括号中出现的任意一个原子 |
| [^原子] | 匹配一个没有在中括号出现的任意一个原子 |
| \ | 转义字符,可以把原子转换特殊元字符,也可以把特殊元字符转成原子。 |
| ^ | 叫开始边界符或开始锚点符,匹配一行的开头位置 |
| $ | 叫结束边界符或结束锚点符,匹配一行的结束位置 |
| . | 叫通配符、万能通配符或通配元字符,匹配1个除了换行符\n以外任何原子 |
| * | 叫星号贪婪符,指定左边原子出现0次或多次 |
| ? | 叫非贪婪符,指定左边原子出现0次或1次 |
| + | 叫加号贪婪符,指定左边原子出现1次或多次 |
| {n,m} | 叫数量范围贪婪符,指定左边原子的数量范围,有{n},{n, }, {,m}, {n,m}四种写法,其中n与m必须是非负整数。 |
| | | 指定原子或正则模式进行二选一或多选一 |
| () | 对原子或正则模式进行捕获提取和分组划分整体操作, |
-
wupeiqi匹配文本中的wupeiqiimport re text = "你好wupeiqi,阿斯顿发wupeiqasd 阿士大夫能接受的wupeiqiff" data_list = re.findall("wupeiqi", text) print(data_list) # ['wupeiqi', 'wupeiqi'] 可用于计算字符串中某个字符出现的次数 -
[abc]匹配a或b或c 字符。import re text = "你2b好wupeiqi,阿斯顿发awupeiqasd 阿士大夫a能接受的wffbbupqaceiqiff" data_list = re.findall("[abc]", text) print(data_list) # ['b', 'a', 'a', 'a', 'b', 'b', 'c']import re text = "你2b好wupeiqi,阿斯顿发awupeiqasd 阿士大夫a能接受的wffbbupqcceiqiff" data_list = re.findall("q[abc]", text) print(data_list) # ['qa', 'qc'] -
[^abc]匹配除了abc意外的其他字符。import re text = "你wffbbupceiqiff" data_list = re.findall("[^abc]", text) print(data_list) # ['你', 'w', 'f', 'f', 'u', 'p', 'e', 'i', 'q', 'i', 'f', 'f'] -
[a-z]匹配a~z的任意字符( [0-9]也可以 )。import re text = "alexrootrootadmin" data_list = re.findall("t[a-z]", text) print(data_list) # ['tr', 'ta'] -
.代指除换行符以外的任意字符。import re text = "alexraotrootadmin" data_list = re.findall("r.o", text) print(data_list) # ['rao', 'roo']import re text = "alexraotrootadmin" data_list = re.findall("r.+o", text) # 贪婪匹配 print(data_list) # ['raotroo']import re text = "alexraotrootadmin" data_list = re.findall("r.+?o", text) # 非贪婪匹配 print(data_list) # ['rao'] -
\w代指字母或数字或下划线(汉字)。import re text = "北京武沛alex齐北 京武沛alex齐" data_list = re.findall("武\w+x", text) print(data_list) # ['武沛alex', '武沛alex'] -
\d代指数字import re text = "root-ad32min-add3-admd1in" data_list = re.findall("d\d", text) print(data_list) # ['d3', 'd3', 'd1']import re text = "root-ad32min-add3-admd1in" data_list = re.findall("d\d+", text) print(data_list) # ['d32', 'd3', 'd1'] -
\s代指任意的空白符,包括空格、制表符等。import re text = "root admin add admin" data_list = re.findall("a\w+\s\w+", text) print(data_list) # ['admin add']
2. 数量相关
-
*重复0次或更多次import re text = "他是大B个,确实是个大2B。" data_list = re.findall("大2*B", text) print(data_list) # ['大B', '大2B'] -
+重复1次或更多次import re text = "他是大B个,确实是个大2B,大3B,大66666B。" data_list = re.findall("大\d+B", text) print(data_list) # ['大2B', '大3B', '大66666B'] -
?重复0次或1次import re text = "他是大B个,确实是个大2B,大3B,大66666B。" data_list = re.findall("大\d?B", text) print(data_list) # ['大B', '大2B', '大3B']
【问号特殊用法】放在重复元字符后门表示取消贪婪匹配
ret2 = re.findall("\w+?", "apple,banana,orange,melon") # 取消贪婪匹配
输出:['a', 'p', 'p', 'l', 'e', 'b', 'a', 'n', 'a', 'n', 'a', 'o', 'r', 'a', 'n', 'g', 'e', 'm', 'e', 'l', 'o', 'n']
-
{n}重复n次import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("151312\d{5}", text) print(data_list) # ['15131255789'] -
{n,}重复n次或更多次import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("\d{9,}", text) print(data_list) # ['442662578', '15131255789'] -
{n,m}重复n到m次import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("\d{10,15}", text) print(data_list) # ['15131255789']
3. 括号(分组)
- 提取数据区域
| 指定原子或正则模式进行二选一或多选一
() 具备模式捕获的能力,也就是优先提取数据的能力,通过(?: ) 可以取消模式捕获,可以简单理解为不再只取括号中的分组数据,而是取整个表达式的匹配数据
ret4 = re.findall(",\w{5},", ",apple,banana,peach,orange,melon,") # 筛选出5个字符的单词
ret4 = re.findall(",(\w{5}),", ",apple,banana,peach,orange,melon,") # 筛选出5个字符的单词
ret4 = re.findall("\w+@\w+\.com", "123abc@163.com,....234xyz@qq.com,....") # 筛选出5个字符的单词
ret4 = re.findall("(\w+)@qq\.com", "123abc@163.com,....234xyz@qq.com,....") # 筛选出5个字符的单词
ret4 = re.findall("(?:\w+)@(?:qq|163)\.com", "123abc@163.com,....234xyz@qq.com,....") # 筛选出5个字符的单词
print(ret4)
import re
text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀"
data_list = re.findall("15131(2\d{5})", text)
print(data_list) # ['255789']
import re
text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来15131266666呀"
data_list = re.findall("15(13)1(2\d{5})", text)
print(data_list) # [ ('13', '255789') ]
import re
text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀"
data_list = re.findall("(15131(2\d{5}))", text)
print(data_list) # [('15131255789', '255789')]
-
获取指定区域 + 或条件
import re text = "楼主15131root太牛15131alex逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("15131(2\d{5}|r\w+太)", text) print(data_list) # ['root太', '255789']import re text = "楼主15131root太牛15131alex逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("(15131(2\d{5}|r\w+太))", text) print(data_list) # [('15131root太', 'root太'), ('15131255789', '255789')]
4. 起始和结束
上述示例中都是去一段文本中提取数据,只要文本中存在即可。
但,如果要求用户输入的内容必须是指定的内容开头和结尾,比就需要用到如下两个字符。
^开始$结束
import re
text = "啊442662578@qq.com我靠"
email_list = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
print(email_list) # []
import re
text = "442662578@qq.com"
email_list = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
print(email_list) # ['442662578@qq.com']
这种一般用于对用户输入数据格式的校验比较多,例如:
import re
text = input("请输入邮箱:")
email = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
if not email:
print("邮箱格式错误")
else:
print(email)
5. 特殊字符
转义元字符是\开头的元字符,由于某些正则模式会在开发中反复被用到,所以正则语法预定义了一些特殊正则模式以方便我们简写。
| 元字符 | 描述 | 示例 |
|---|---|---|
| \d | 匹配一个数字原子,等价于[0-9]。 |
\d |
| \D | 匹配一个非数字原子。等价于[^0-9]或[^\d]。 |
"\D" |
| \b | 匹配一个单词边界原子,也就是指单词和空格间的位置。 | er\b |
| \B | 匹配一个非单词边界原子,等价于 [^\b] |
r"\Bain"r"ain\B" |
| \n | 匹配一个换行符 | |
| \t | 匹配一个制表符,tab键 | |
| \s | 匹配一个任何空白字符原子,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
"\s" |
| \S | 匹配一个任何非空白字符原子。等价于[^ \f\n\r\t\v]或 [^\s]。 |
"\S" |
| \w | 匹配一个包括下划线的单词原子。等价于[A-Za-z0-9_]。 |
"\w" |
| \W | 匹配任何非单词字符。等价于[^A-Za-z0-9_] 或 [^\w]。 |
"\W" |
由于正则表达式中 * . \ { } ( ) 等都具有特殊的含义,所以如果想要在正则中匹配这种指定的字符,需要转义,例如:
转义符-> \d \D \w \W \n \s \S \b \B
""" \b 1个单词边界原子 """
txt = "my name is nana. nihao,nana"
ret = re.findall(r"na", txt)
ret = re.findall(r"\bna", txt)
ret = re.findall(r"\bna\w{2}", txt)
print(ret) # ['na', 'na', 'na']
import re
text = "我是你{5}爸爸"
data = re.findall("你{5}爸", text)
print(data) # []
import re
text = "我是你{5}爸爸"
data = re.findall("你\{5\}爸", text)
print(data)
【2】常用正则表达式
工作中,正则一般用于验证数据、校验用户输入的信息、爬虫、运维日志分析等。其中如果是验证用户输入的数据:
| 场景 | 正则表达式 |
| :-------------------- | ------------------------------------------------------------ |
| 用户名 | ^[a-z0-9_-]{3,16}$ |
| 密码 | ^[a-z0-9_-]{6,18}$ |
| 手机号码 | ^(?:\+86)?1[3-9]\d{9}$ |
| 颜色的十六进制值 | ^#?([a-f0-9]{6}|[a-f0-9]{3})$ |
| 电子邮箱 | ^[a-z\d]+(\.[a-z\d]+)*@([\da-z](-[\da-z])?)+\.[a-z]+$ |
| URL | ^(?:https:\/\/|http:\/\/)?([\da-z\.-]+)\.([a-z\.]+).\w+$ |
| IP 地址 | ((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?) |
| **HTML 标签** | ^<([a-z]+)([^<]+)*(?:>(.*)<\/\1> |
| utf-8编码下的汉字范围 | ^[\u2E80-\u9FFF]+$ |

5.8.2 re模块
python中提供了re模块,可以处理正则表达式并对文本进行处理。
注意:python本身没有内置正则处理的,python中的正则就是一段字符串,我们需要使用python模块中提供的函数把字符串发送给正则引擎,正则引擎会把字符串转换成真正的正则表达式来处理文本内容。
re模块提供了一组正则处理函数,使我们可以在字符串中搜索匹配项:
| 函数 | 描述 |
|---|---|
| findall | 按指定的正则模式查找文本中所有符合正则模式的匹配项,以列表格式返回结果。 |
| search | 在字符串中任何位置查找首个符合正则模式的匹配项,存在则返回re.Match对象,不存在返回None |
| match | 判定字符串开始位置是否匹配正则模式的规则,匹配则返回re.Match对象,不匹配返回None |
| split | 按指定的正则模式来分割字符串,返回一个分割后的列表 |
| sub | 把字符串按指定的正则模式来查找符合正则模式的匹配项,并可以替换一个或多个匹配项成其他内容。 |
-
findall,函数返回包含所有匹配项的列表,如果找不到匹配项,则返回一个空列表。
import re text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.findall("(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)", text) print(data_list) # [('130429', '1919', '12', '01', '521', '9'), ('130429', '1959', '12', '19', '521', 'X')] -
match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
import re text = "大小逗2B最逗3B欢乐" data = re.match("逗\dB", text) print(data) # Noneimport re text = "逗2B最逗3B欢乐" data = re.match("逗\dB", text) if data: content = data.group() # "逗2B" print(content) -
search,函数搜索匹配的字符串,如果匹配上则返回匹配对象re.Match。如果有多个匹配项,则仅返回匹配项的第一个匹配项,如果找不到匹配项,则返回值为None。.span()方法返回找到的字符串的起始和结束位置编号的元组;.group()方法返回找到的字符串。
import re text = "大小逗2B最逗3B欢乐" data = re.search("逗\dB", text) if data: print(data.group()) # "逗2B"# 有名分组 import re ret = re.search("1[3-9]\d{9}", "我的手机号码是13928835900,我女朋友的手机号是 15100363326") print(ret) print(ret.start(), ret.end(), ret.span()) print(ret.group()) ret = re.search("(?P<tel>1[3-9]\d{9}).*?(?P<email>\d+@qq.com)", "我的手机号码是 13928835900,我的邮箱是123@qq.com") print(ret) print(ret.group("tel")) print(ret.group("email")) -
sub,替换匹配成功的位置, subn 返回替换的结果和次数
import re text = "逗2B最逗3B欢乐" data = re.sub("\dB", "沙雕", text) print(data) # 逗沙雕最逗沙雕欢乐import re text = "逗2B最逗3B欢乐" data = re.sub("\dB", "沙雕", text, 1) # 最后一个参数替换的次数 print(data) # 逗沙雕最逗3B欢乐 -
split,根据匹配成功的位置分割,返回一个列表。
import re text = "逗2B最逗3B欢乐" data = re.split("\dB", text) print(data) # ['逗', '最逗', '欢乐']import re text = "逗2B最逗3B欢乐" data = re.split("\dB", text, 1) print(data) # ['逗', '最逗3B欢乐'] -
compile:如果一个正则表达式要使用几千遍,每一次都会编译,出于效率的考虑进行正则表达式的编译,就不需要每次都编译了,节省了编译的时间,从而提升效率
import re
re_email = re.compile(r"(?:\+86)?1[3-9]\d{9}")
ret = re_email.findall("15100649928,123@qq.com,13653287791,666@163.com")
print(ret)
-
finditer
import re text = "逗2B最逗3B欢乐" data = re.finditer("\dB", text) for item in data: print(item.group())import re text = "逗2B最逗3B欢乐" data = re.finditer("(?P<xx>\dB)", text) # 命名分组 for item in data: print(item.groupdict())text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.finditer("\d{6}(?P<year>\d{4})(?P<month>\d{2})(?P<day>\d{2})\d{3}[\d|X]", text) for item in data_list: info_dict = item.groupdict() print(info_dict)
贪婪匹配和非贪婪匹配
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
贪婪模式下字符串查找会直接走到字符串结尾去匹配,如果不相等就向前寻找,这一过程称为回溯。

import re
str1='<table><td><th>贪婪</th><th>贪婪</th><th>贪婪</th></td></table>贪婪'
str2=re.findall(r'<.*>',str1)
print(str2)
>>>['<table><td><th>贪婪</th><th>贪婪</th><th>贪婪</th></td></table>']
非贪婪模式下会自左向右查找,一个一个匹配不会出现回溯的情况。

import re
str1='<table><td><th>贪婪</th><th>贪婪</th><th>贪婪</th></td></table>贪婪'
str2=re.findall(r'<.*?>',str1)
print(str2)
>>>['<table>', '<td>', '<th>', '</th>', '<th>', '</th>', '<th>', '</th>', '</td>', '</table>']
【4】正则进阶
.*? 非贪婪模式,最小匹配
import re
text = '<12> <xyz> <!@#$%> <1a!#e2> <>'
ret = re.findall("<\d+>", text)
ret = re.findall("<\w+>", text)
ret = re.findall("<.+>", text)
ret = re.findall("<.+?>", text)
ret = re.findall("<.*?>", text)
print(ret)
模式修正符
模式修正符,也叫正则修饰符,模式修正符就是给正则模式增强或增加功能的。
| 修正符 | re模块提供的变量 | 描述 |
|---|---|---|
| i | re.I | 使模式对大小写不敏感,也就是不区分大小写 |
| m | re.M | 使模式在多行文本中可以多个行头和行位,影响 ^ 和 $ |
| s | re.S | 让通配符. 可以代码所有的任意原子(包括换行符\n在内) |
import re
text = """
<12
>
<x
yz>
<!@#$%>
<1a!#
e2>
<>
"""
ret = re.findall("<.*?>", text)
ret = re.findall("<.*?>", text, re.S)
print(ret)
【补充】raw-string:原生字符串
result = re.findall(r'\b\t', 'abcd\bhello\tworld')
# 这里加r前缀,是告诉python解释器,后面的字符串不要处理,原封不动的交给re正则引擎处理,这样就不会跟python解释器的转义字符冲突,导致处理结果异常。
【补充】 项目开发规范
现阶段,我们在开发一些程序时(终端运行),应该遵循一些结构的规范,让你的系统更加专业。
2.1 单文件应用
当基于python开发简单应用时(一个py文件就能搞定),需要注意如下几点。
"""
文件注释
"""
import re
import random
import requests
from openpyxl import load_workbook
DB = "XXX"
def do_something():
""" 函数注释 """
# TODO 待完成时,下一期实现xxx功能
for i in range(10):
pass
def run():
""" 函数注释 """
# 对功能代码进行注释
text = input(">>>")
print(text)
if __name__ == '__main__':
run()

2.2 单可执行文件
新创建一个项目,假设名字叫 【crm】,可以创建如下文件和文件夹来存放代码和数据。
crm
├── app.py 文件,程序的主文件(尽量精简)
├── config.py 文件,配置文件(放相关配置信息,代码中读取配置信息,如果想要修改配置,即可以在此修改,不用再去代码中逐一修改了)
├── db 文件夹,存放数据
├── files 文件夹,存放文件
├── src 包,业务处理的代码
└── utils 包,公共功能
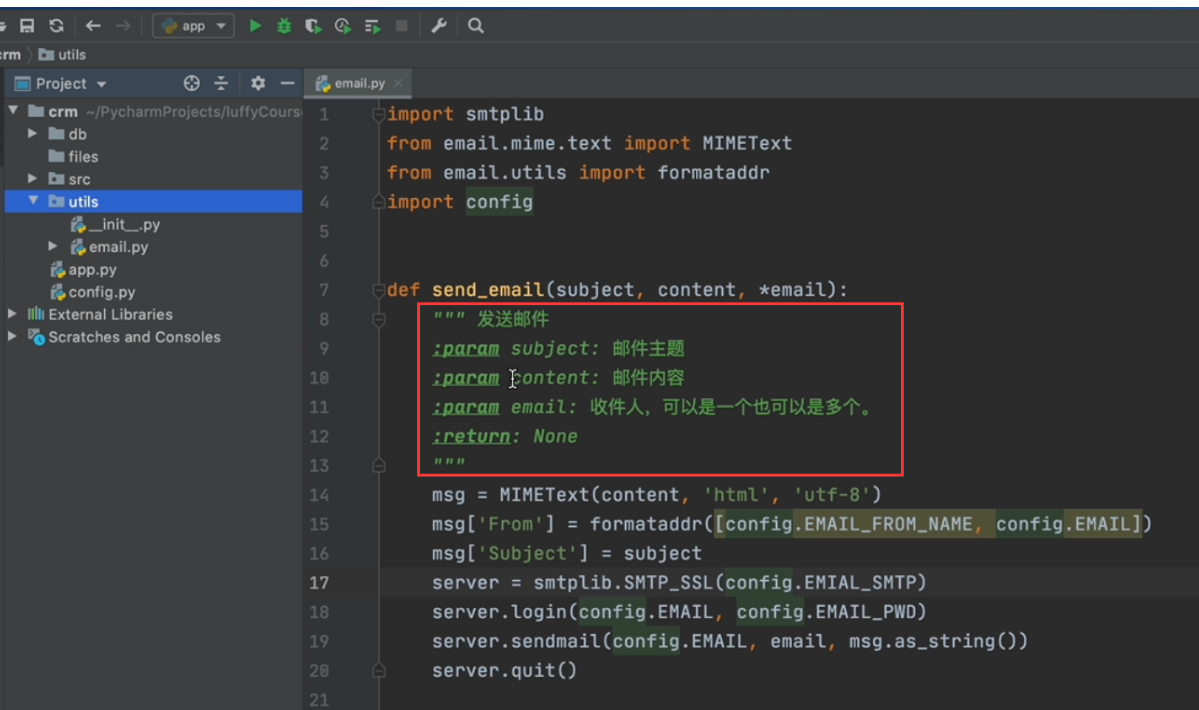
上述格式的函数注释,在pycharm中可以在函数名下一行输入三个引号后,回车就会自动生成这样的参数的形式,再手动填充注释即可。
2.3 多可执行文件
新创建项目,假设名称叫【killer】,可以创建如下文件和文件夹来存放代码和数据。
killer
├── bin 文件夹,存放多个主文件(可运行)
│ ├── app1.py
│ └── app2.py
├── config 包,配置文件
│ ├── __init__.py
│ └── settings.py
├── db 文件夹,存放数据
├── files 文件夹,存放文件
├── src 包,业务代码
│ └── __init__.py
└── utils 包,公共功能
└── __init__.py
本文来自博客园,作者:#缘起,转载请注明原文链接:https://www.cnblogs.com/yuan-qi/p/15075787.html
