


Paper Reading(1)-VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement
VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement
来源:
https://doi.org/10.48550/arXiv.2211.10666
https://conferencedemos.github.io/icassp23/
主要贡献:
1)定义了一个新的任务,称为timbre-controlled video-to-audio generation,以解决无声视频生成具有所需真实音色的逼真声音效果的问题,2)提出了一种基于信息解耦和对抗训练的方法,具有有效的编码器-解码器结构来完成任务,3)实验结果与实际情况接近,证明了有效地完成了所提出的任务。
任务:
允许用户为无声视频生成具有他们期望音色的逼真声音效果,即在给定视频输入和参考音频样本的情况下生成具有特定音色的声音的(TCVSG)。
工作:
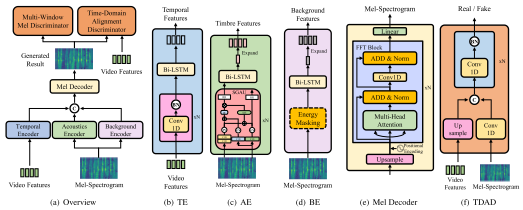
提出了VarietySound,一种用于生成高质量音频的video-to-sound模型,该音频与视频中的事件同步并且具有与参考音频相同的声学特性。
-
具体方法:采用了一种基于信息解耦的方法,先将音频的信息分解成三部分,然后再将这些信息重新组合起来重构音频。因此,我们可以改变音频中的任何部分信息,而不会影响其他部分。
-
(1)组件信息:
-
- a temporal encoder(时间编码器):信息由视频帧提供,即输入视频与原始音频相同的时间信息为输入。
-
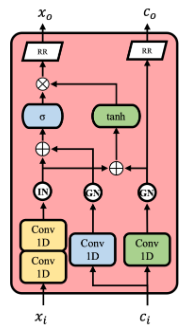
- an acoustic encoder(声学编码器):对音色信息进行编码,它将原始音频作为输入,并通过时间损坏操作(对输入的参考音频进行随机重采样变换)丢弃其时间信息;
-
- a background encoder(背景编码器):用于对与音色无关的其他声学信息进行编码,它使用原始音频的背景部分作为输入。采用能量掩蔽操作,沿时间维对能量大于整个梅尔谱图中值能量部分的梅尔谱图进行掩蔽,能量掩蔽操作丢弃了梅尔谱图的时间和音色相关信息,仅保留音频中的背景信息。在训练阶段,加入这些信息来匹配目标梅尔谱图;在推理阶段,该信息将被设置为空,以生成更清晰的音频。
-
- Mel解码器:三个编码器的输出联合送到Mel Decoder以获得最终重建的Mel频谱图,并使用真实的Mel频谱图计算生成损耗以指导生成器的训练。
-
(2)训练阶段:
-
- 生成器:使用来自相同样本的视频特征和Mel频谱图送到网络中,其中视频特征被送到时间编码器,Mel频谱图被送到声学和背景编码器。然后将三个编码器的输出联合送到Mel解码器,得到最终重构的Mel频谱图图,并利用真实Mel频谱图计算生成损失,指导生成器的训练。
-
- 判别器:对于时域对齐判别器,使用来自同一真实样本的视频特征和Mel频谱图作为输入来构造正样本,而使用真实视频特征和重建的梅尔谱图作为输入来构造负样本[为了在时间维度上与Mel频谱图保持一致]。对于多窗口Mel判别器,使用来自样品的真实Mel频谱图作为正样本,重建的Mel频谱图作为负样本输入[判别生成的Mel频谱图的质量]。
-
(3)推理阶段:
-
将视频特征送到时间编码器中,将参考音频的Mel频谱图送到声学编码器中,将无声音频的Mel频谱图送到背景编码器中,然后通过Mel解码器生成声音。参考音频的选择是任意的,具体取决于所需的目标音色。从理论上讲,推理阶段视频特征和参考音频输入的长度是任意的,但必须确保视频中存在相关事件,并且参考音频包含所需的音色,以获得正常生成的声音。
-
声学编码器结构:
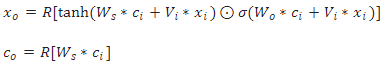
实验评价标准:
- 定义了一系列评估指标。
- (1)主观评价:使用平均意见得分(MOS)来评估生成的结果,具体在三个方面:生成的音频的质量,与视频的时间对齐,以及音色与参考音频的相似性。
- (2)客观评价,使用从第三方工具中提取的音色特征的余弦相似度作为音色相似度的客观评价。
