Hadoop思想与原理
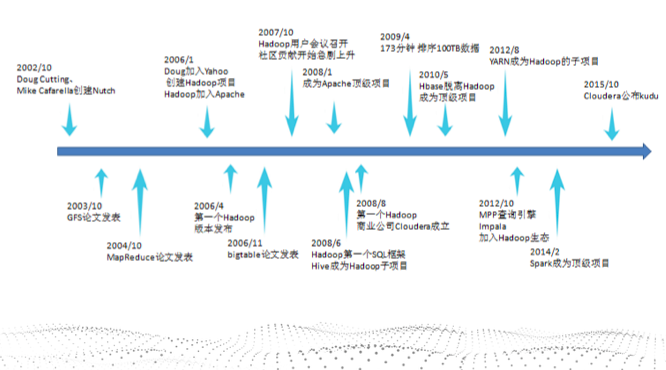
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
- 2003-2004年,Google公布了部分GFS和MapReduce思想的细节,
- 2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
- Hadoop的成长过程
- Lucene–>Nutch—>Hadoop
- GFS—->HDFS
- Google MapReduce—->Hadoop MapReduce
- BigTable—->HBase
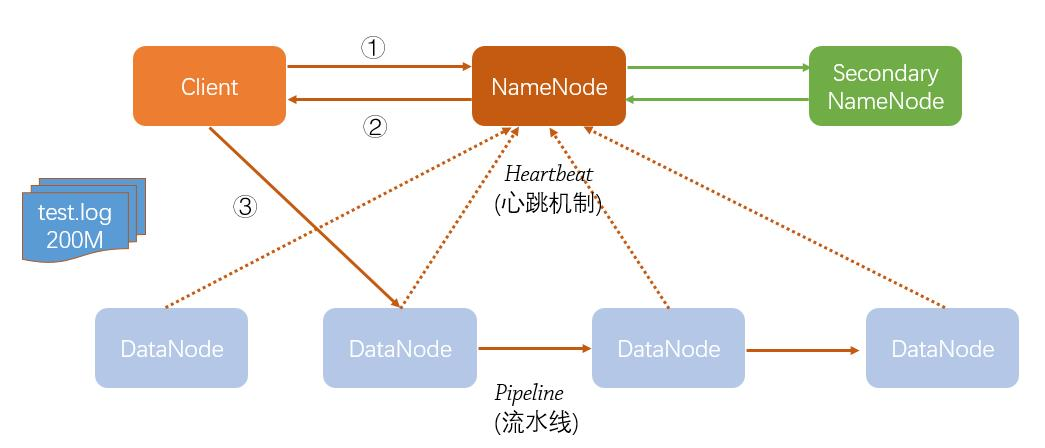
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
1.Namenode:主要负责:
- 接收用户的请求;
- 维护文件系统的目录结构;
- 管理文件与Block之间的练习;
2.Datanode:主要负责:
- 存放数据;
- 文件被分割以Block的形式被存储在磁盘上;
3.Secondarynode:主要负责:
1.将namenode image(fsimage)和Edit log合并
2.是周期性将元数据节点的命名空间镜像文件和修改日志进行合并,以防日志文件过大。
各个节点的联系:
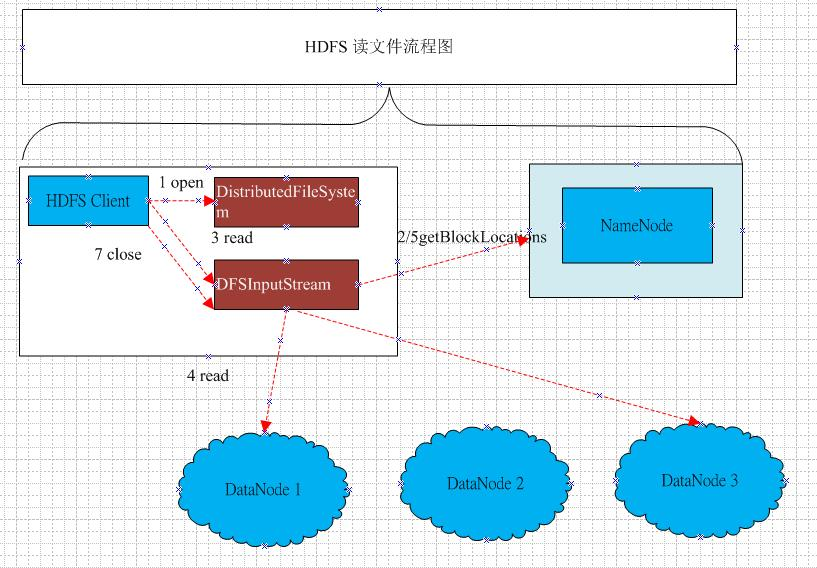
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
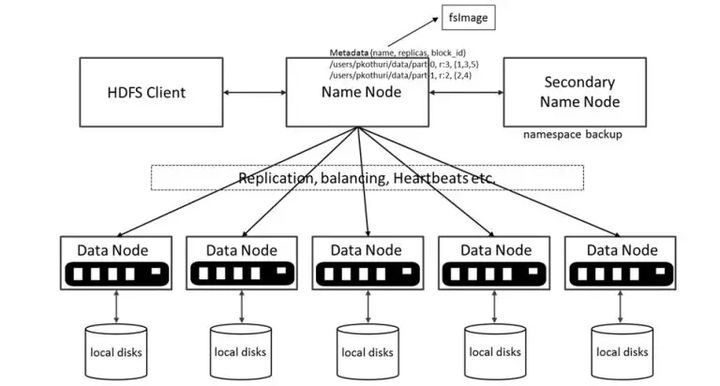
- 数据冗余
- 数据存取策略
- 数据错误与恢复
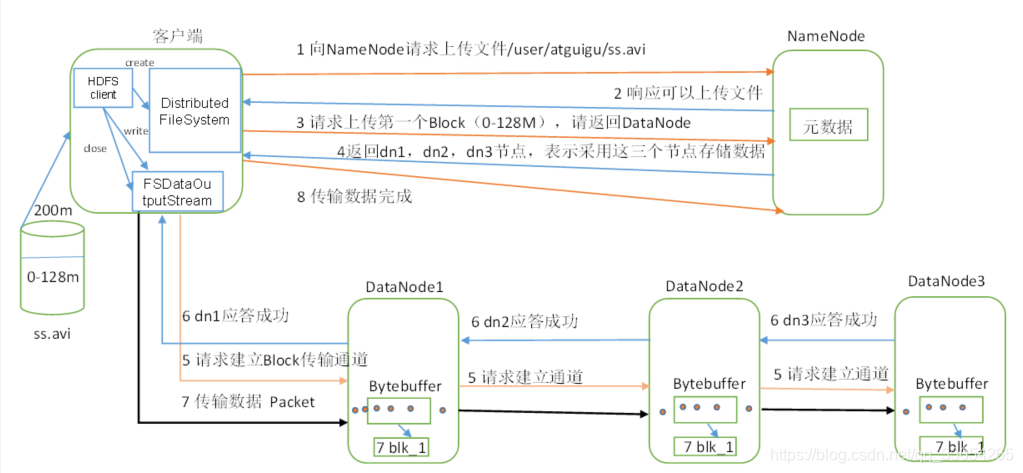
①服务端启动HDFS中的NN和DN进程
②客户端创建一个分布式文件系统客户端,由客户端向NN发送请求,请求上传文件
③NN处理请求,检查客户端是否有权限上传,路径是否合法等
④检查通过,NN响应客户端可以上传
⑤客户端根据自己设置的块大小,开始上传第一个块,默认0-128M,NN根据客户端上传文件的副本数(默认为3),根据机架感知策略选取指定数量的DN节点返回
⑥客户端根据返回的DN节点,请求建立传输通道客户端向最近(网络举例最近)的DN节点发起通道建立请求,由这个DN节点依次向通道中的(距离当前DN距离最近)下一个节点发送建立通道请求,各个节点发送响应 ,通道建立成功
⑦客户端每读取64K的数据,封装为一个packet(数据包,传输的基本单位),将packet发送到通道的下一个节点通道中的节点收到packet之后,落盘(检验)存储,将packet发送到通道的下一个节点!每个节点在收到packet后,向客户端发送ack确认消息!
⑧一个块的数据传输完成之后,通道关闭,DN向NN上报消息,已经收到某个块
⑨第一个块传输完成,第二块开始传输,依次重复⑤-⑧,直到最后一个块传输完成,NN向客户端响应传输完成!
客户端关闭输出流
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
HMaster在功能上主要负责Table表和HRegion的管理工作,具体包括:
1、管理用户对Table表的增、删、改、查操作;
2、管理HRegion服务器的负载均衡,调整HRegion分布;
3、在HRegion分裂后,负责新HRegion的分配;
4、在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移。
- Region服务器的功能

- Zookeeper协同的功能
1.Zookeeper加强集群稳定性
2.Zookeeper加强集群持续性
3.Zookeeper保证集群有序性
4.Zookeeper保证集群高效
- Client客户端的请求流程
1. 客户发起情况到服务器网卡;
2. 服务器网卡接受到请求后转交给内核处理;
3. 内核根据请求对应的套接字,将请求交给工作在用户空间的Web服务器进程
4. Web服务器进程根据用户请求,向内核进行系统调用,申请获取相应资源(如index.html)
5. 内核发现web服务器进程请求的是一个存放在硬盘上的资源,因此通过驱动程序连接磁盘
6. 内核调度磁盘,获取需要的资源
7. 内核将资源存放在自己的缓冲区中,并通知Web服务器进程
8. Web服务器进程通过系统调用取得资源,并将其复制到进程自己的缓冲区中
9. Web服务器进程形成响应,通过系统调用再次发给内核以响应用户请求
10. 内核将响应发送至网卡
11. 网卡发送响应给用户
- 四者之间的相系关系
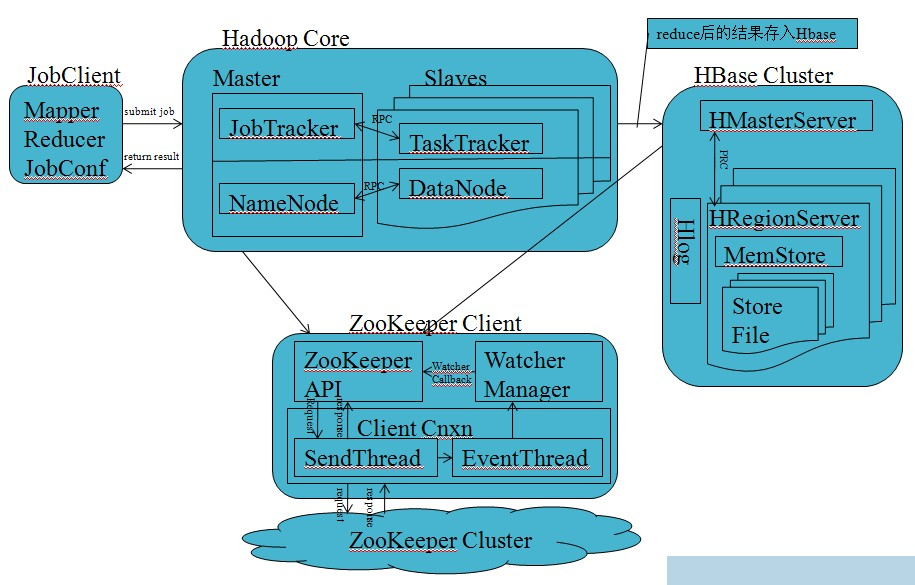
- 与HDFS的关联
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
HDFS是一个分布式文件系统:引入存放文件元数据信息的服务器Namenode和实际存放数据的服务器Datanode,对数据进行分布式储存和读取。
MapReduce是一个分布式计算框架:MapReduce的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map计算/Reduce计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
5.理解并描述Hbase表与Region与HDFS的关系。
Region是HBase数据存储和管理的基本单位
Region由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile 组成。memStore存储在内存中, StoreFile存储在HDFS上。HBase通过将region切分在许多机器上实现分布式
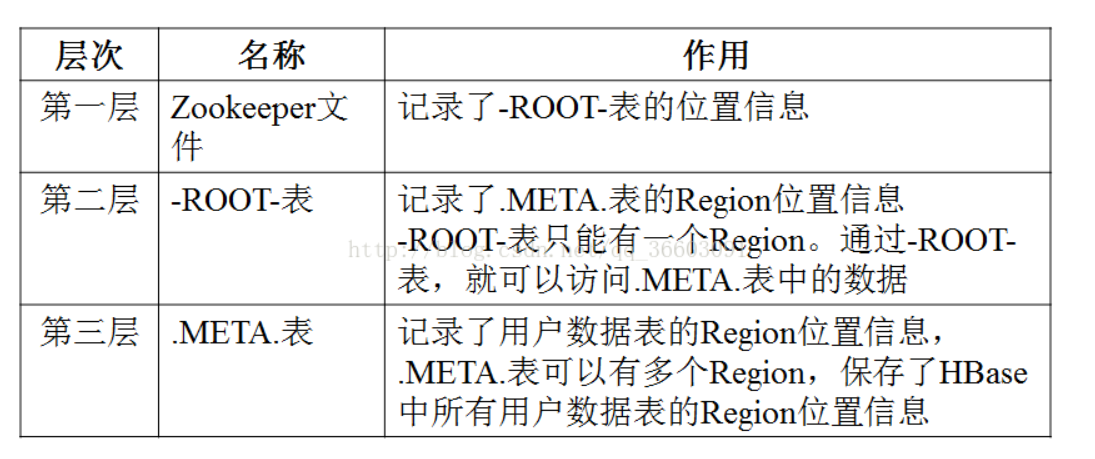
6.理解并描述Hbase的三级寻址。
(1) -ROOT-表:存储元数据表,即.MEAT.表的信息。它被“写死”在ZooKeeper文件中,是唯一的、不能再分裂的
(2) .META.表:存储用户数据具体存储在哪些Region服务器上。它会随存储数据的增多而分裂成更多个。
(3) 用户数据表:具体存储用户数据。它是最底层的、可分裂的
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
(2G/1K)x(2G/1k)=242 即2ZB
所以上Hbase的数据表最大有2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号