正则表达式中:.*,.*?,.+?的理解与应用
1、 .* 贪婪模式
. 表示 匹配除换行符 \n 之外的任何单字符,*表示零次或多次。所以.*在一起就表示任意字符出现零次或多次。没有?表示贪婪模式。比如a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
比如模式src='.*', 它将会匹配最长的以 src='开始,以`结束的最长的字符串。用它来搜索 <img src='test.jpg' width='60px' height='80px'/> 时,将会返回 src='test.jpg' width='60px' height='80px'
2、 .*? 懒惰模式
?跟在*或者+后边用时,表示懒惰模式。也称非贪婪模式。就是匹配尽可能少的字符。就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
又比如模式 src=`.*?`,它将会匹配 src=` 开始,以 ` 结束的尽可能短的字符串。且开始和结束中间可以没有字符,因为*表示零到多个。用它来搜索 <img src=``test.jpg` width=`60px` height=`80px`/> 时,将会返回 src=``。
3、 .+? 懒惰模式
同上,?跟在*或者+后边用时,表示懒惰模式。也称非贪婪模式。就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。a.+?b匹配最短的,以a开始,以b结束的字符串,但a和b中间至少要有一个字符。如果把它应用于ababccaab的话,它会匹配abab(第一到第四个字符)和aab(第七到第九个字符)。注意此时匹配结果不是ab,ab和aab。因为a和b中间至少要有一个字符。
又比如模式 src=`.+?`,它将会匹配 src=` 开始,以 ` 结束的尽可能短的字符串。且开始和结束中间必须有字符,因为+表示1到多个。用它来搜索 <img src=``test.jpg` width=`60px` height=`80px`/> 时,将会返回 src=``test.jpg`。注意与.*?时的区别,此时不会匹配src=``,因为src=` 和 ` 之间至少有一个字符。
示例:
爬取源代码中的:影片名称、评分、图片等信息。
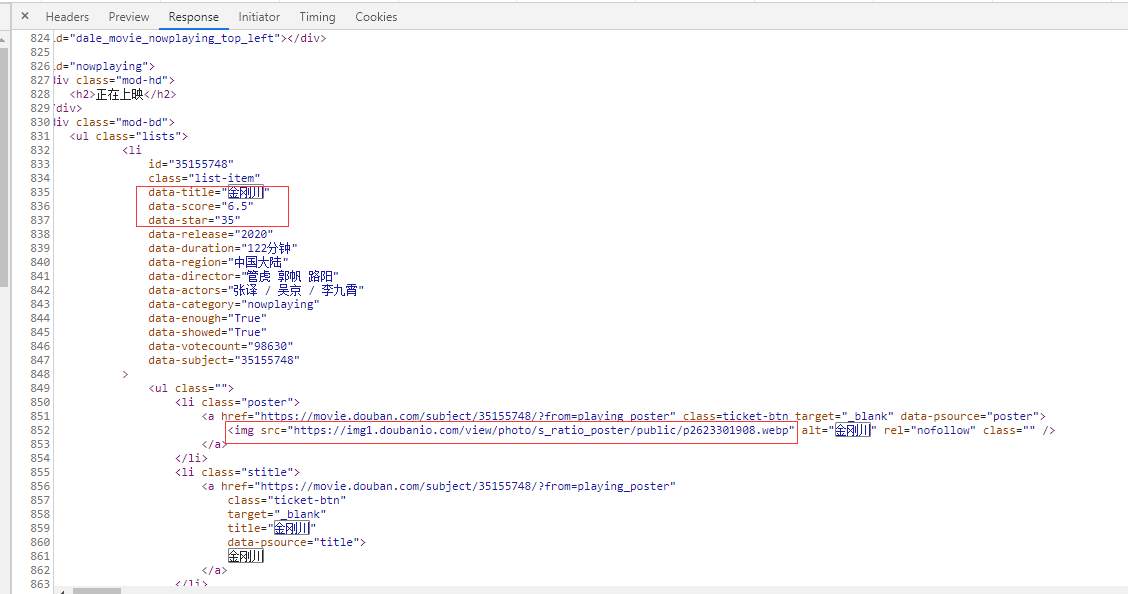
分析源码:
step1: 可以看到一部电影信息对应的源代码是一个 li 节点,我们用正则表达式来提取这里面的一些电影信息,首先我们需要提取它的电影名称信息,而它的电影名称信息是在 class 为 "list-item"的节点后,所以这里利用非贪婪匹配来提取data-title属性的信息,正则表达式写为:
<li.*?list-item.*?data-title="(.*?)".*?>
step2: 使用同样的的判断方面来提取dat-score属性的信息,正则表达式写为:
<li.*?list-item.*?data-title="(.*?)".*?data-score="(.*?)".*?>
step3: 随后我们需要提取电影的图片,可以看到在a节点内部有img节点,该节点下面有src属性是图片的链接,所以在这里提取img节点的src属性,所以正则可以改写如下:
<li.*?list-item.*?data-title="(.*?)".*?data-score="(.*?)".*?>.*?<img.*?src="(.*?)".*?/>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号