
20201307梁辰鱼第12章学习总结
第12章 块设备I/O和缓冲区管理
一、知识点总结
12.1 块设备和I/O缓冲区
由于与内存访问相比,磁盘I/O速度较慢,所以不希望再每次执行读写文件操作时都执行磁盘I/O。因此,大多数文件系统使用I/O缓冲来减少存储设备的物理I/O数量。合理设计的I/O缓方案可显著提高文件I/O缓冲方案可显著提高文件I/O效率并增加系统吞吐量。
I/O缓冲的基本原理非常简单。文件系统使用一系列I/O缓冲区作为块设备的缓存内存。当进程试图读取(dev,blk)标识的磁盘块时,它首先在缓冲区缓存中搜索分配给磁盘块的缓冲区。如果该缓冲区存在并且包含有效数据,那么它只需从缓冲区中读取数据,而无须再次从磁盘中读取数据块。如果该缓冲区不存在,它会为磁盘块分配一个缓冲区,将数据从磁盘读入缓冲区,然后从缓冲区读取数据。当某个块被读入时,该缓冲区将被保存在缓冲区缓存中。以供任意进程对同一个块的下一次读/写请求使用。同样,当进程写入磁盘块时,它首先会获取一个分配给该块的缓冲区。然后,它将数据写人缓冲区,将缓冲区标记为脏,以延迟写入,并将其释放到缓冲区缓存中。由于脏缓冲区包含有效的数据,因此可以使用它来满足对同一块的后续读/写请求,而不会引起实际磁盘I/O。脏缓冲区只有在被重新分配到不同的块时才会写人磁盘。
bread(dev, blk)函数:
BUFFER *bread(dev,blk) // return a buffer containing valid data
{
BUFFER *bp = getblk(dev,blk); // get a buffer for (dev,blk)
if (bp data valid)
return bp;
bp->opcode = READ; // issue READ operation
start_io(bp); // start I/O on device
wait for I/O completion;
return bp;
}
write_block(dev, blk, data)函数:
write_block(devf blk, data)
{
BUFFER *bp = bread(dev,blk); // read in the disk block first
write data to bp;
(synchronous write)? bwrite(bp) : dwrite(bp);
}
12.2 Unix I/O缓冲区管理算法
(1) Unix缓冲区管理子系统
- I/O 缓冲区:内核中的一系列NBUF缓冲区用作缓冲区缓存。每个缓冲区用一个结构体表示。
typdef struct buf{
struct buf *next_free; //freelist pointer
struct buf *next_dev; //dev_list pointer
int dev,blk; //assigned disk block;
int opcode; //READ|WRITE
int dirty; //buffer data modified
int async; //ASYNC write flag
int valid; //buffer data valid
int busy; //buffer is in use
int wanted; //some process needs this buffer
struct, semaphore lock=l ; //buffer locking semaphore; value=L
struct semaphore iodone=0; //for process to wait for I/O completion;
char buf[BLKSIZE]; //block data area
} BUFFER;
BUFFER buf[NBUF], *freelist; // NBUF buffers and free buffer list
缓冲区结构体由两部分组成; 用于缓冲区管理的缓冲头部分和用于数据块的数据部分。为了保护内核内存, 状态字段可以定义为一个位向扭, 其中每个位表示一个唯一的状态条件。
- 设备表:每个块设备用一个设备表结构表示。
每个设备表都有一个dev_Iist,包含当前分配给该设备的I/O缓冲区,还有一个io_queue,包含设备上等待I/O操作的缓冲区。I/O队列的组织方式应确保最佳I/O操作。Unix使用FIFO I/O队列。
- 缓冲区初始化:
当系统启动时,所有I/O缓冲区都在空闲列表中, 所有设备列表和I/O队列均为空。
- 缓冲区列表:
当缓冲区分配给 (dev, blk) 时, 它会被插人设备表的dev_list 中。 如果缓冲区当前正在使用, 则会将其标记为BUSY (繁忙)并从空闲列表中删除。繁忙缓冲区也可能会在设备表的 I/O 队列中。 由于一个缓冲区不能同时处于空闲状态和繁忙状态, 所以可通过使用相同的 next_free 指针来维护设备 I/O 队列。 当缓冲区不再繁忙时, 它会被释放回空闲列表, 但仍保留在 dev_list 中, 以便可能重用。 只有在重新分配时, 缓冲区才可能从一个 dev_list 更改到另一个 dev_list 中。 如前文所述, 读/写磁盘块可以表示为 bread 、 bwrite 和dwrite, 它们都要依赖于 getblk 和 brelse。
Unix算法的一些具体说明:
-
数据一致性:为了确保数据-致性,getblk一定不能给同一个(dev,blk)分配多个缓冲区。这可以通过让进程从休眠状态唤醒后再次执行“重试循环”来实现。读者可以验证分配的每个缓冲区都是唯一的。其次,脏缓冲区在重新分配之前被写出来,这保证了数据的一致性。
-
缓存效果:缓存效果可通过以下方法实现。释放的缓冲区保留在设备列表中,以便可能重用。标记为延迟写入的缓冲区不会立即产生I/O、并且可以重用。缓冲区会被释放到空闲列表的末尾,但分配是从空闲列表的前面开始的。这是基于LRU(最近最少使用)原则, 它有助于延长所分配缓冲区的使用期,从而提高它们的缓存效果。
-
临界区:设备中断处理程序可操作缓冲区列表,例如从设备表的I/O队列中删除 bp. 更改其状态并调用brelse(bp)。所以,在getblk和brelse中,设备中断在这些临界区中会被屏蔽。这些都是隐含的,但没有在算法中表现出来。
Unix算法的缺点:
- 效率低下:该算法依赖于重试循环。例如,释放缓冲区可能会唤醒两组进程:需要释放的缓冲区的进程,以及只需要空闲缓冲区的进程。由于只有一个进程可以获取释放的缓冲区,所以,其他所有被唤醒的进程必须重新进入休眠状态。从休眠状态唤醒后,每个被唤醒的进程必须从头开始重新执行算法,因为所需的缓冲区可能已经存在。这会导致过多的进程切换。
- 缓存效果不可预知:在Unix算法中,每个释放的缓冲区都可被获取。如果缓冲区由需要空闲绥冲区的进程获取,那么将会重新分配缓冲区.即使有些进程仍然需要当前的缓冲区。
- 可能会出现饥饿:Unix算法基于"自由经济"原则,即每个进程都有尝试的机会,但不能保证成功。因此,可能会出现进程饥饿。
- 该算法使用只适用于单处理器系统的休眠/唤醒操作。
12.3 新的I/O缓冲区管理算法
与休眠/唤醒相比,信号量的主要优点是:
- (1)计数信号量可用来表示可用资源的数量,例如:空闲缓冲区的数量。
- (2)当多个进程等待一个资源时,信号量上的V操作只会释放一个等待进程,该进程不必重试,因为它保证拥有资源。
使用信号量上的P/V来设计缓冲区管理算法要满足以下条件:
- 缓冲区唯一性
- 无重试循环
- 无不必要唤醒
- 缓存效果
- 无死锁和饥饿
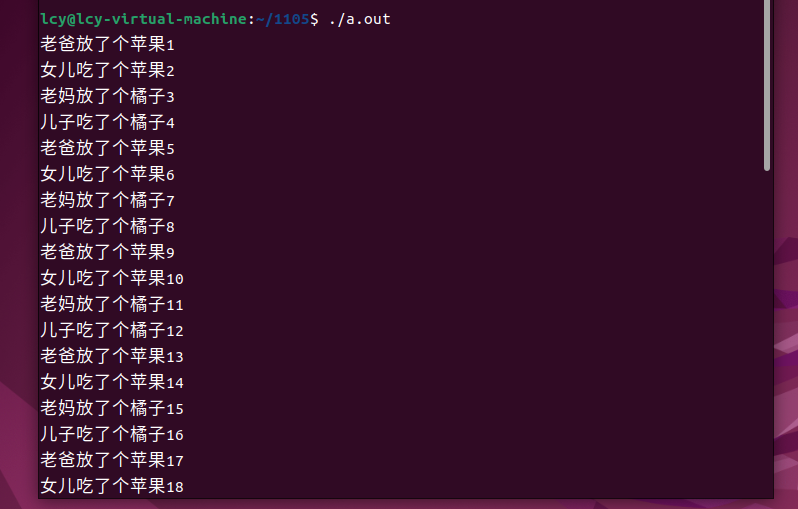
二、实践截图
参考链接:p/v算法实现
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <pthread.h>
#include<semaphore.h>
#define P sem_wait
#define V sem_post
#define full_apple &fullA
#define full_orange &fullB
#define empty &empty_aha
sem_t fullA;
sem_t fullB;
sem_t empty_aha;
int num=0;
void* Dad(void *p)
{
while(num<50)
{
P(empty);
num++;
printf("老爸放了个苹果%d\n",num);
V(full_apple);
}
}
void* Dangter(void *p)
{
while(num<50)
{
P(full_apple);
num++;
printf("女儿吃了个苹果%d\n",num);
V(empty);
}
}
void* Mum(void *p)
{
while(num<50)
{
P(empty);
num++;
printf("老妈放了个橘子%d\n",num);
V(full_orange);
}
}
void* Son(void *p)
{
while(num<50)
{
P(full_orange);
num++;
printf("儿子吃了个橘子%d\n",num);
V(empty);
}
}
int main()
{
sem_init(full_apple, 0, 0);
sem_init(full_orange, 0, 0);
sem_init(empty, 0, 1);
pthread_t tid0;
pthread_t tid1;
pthread_t tid2;
pthread_t tid3;
pthread_create(&tid0, NULL, Dad, NULL);
pthread_create(&tid1, NULL, Mum, NULL);
pthread_create(&tid2, NULL, Son, NULL);
pthread_create(&tid3, NULL, Dangter, NULL);
getchar();
pthread_exit(0);
return 0;
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术