
20201307梁辰鱼第11章学习总结
第11章 EXT2文件系统
1 知识点归纳
1.1 EX2文件系统
多年来,Linux 一直使用EXT2(Card等1995)作为默认文件系统。EXT3(EXT3,2014)是EXT2的扩展。EXT3中增加的主要内容是一个日志文件,它将文件系统的变更 记录在日志中°日志可在文件系统崩溃时更快地从错误中恢复。没有错误的EXT3文件系 统与EXT2文件系统相同。EXT3的最新扩展是EXT4 ( Cao等2007)。EXT4的主要变化是磁盘块的分配。在EXT4中,块编号为48位。EXT4不是分配不连续的磁盘块,而是分配连续的磁盘块区,称为区段。除了这些细微的更改之外,文件系统结构和文件操作保持不变。
1.2 EXT2文件系统数据结构
1.2.1 通过mkfs创建虚拟磁盘
mke2fs [-b blksize -N ninodes] device nblocks
在设备上创建一个带有nblocks个块(每个块大小为blksize字节)和ninodes个索引节点的EXT2文件系统。设备可以是真实设备,也可以是虚拟磁盘文件。如果未指定blksize,则默认块大小为1KB,如果未指定ninoides, mke2fs将根据nblocks计算一个默认的ninodes数。得到的EXT2文件系统可在Linux中使用。举个具体的例子,下面的命令
dd if=/dev/zero of=vdisk bs«1024 count«1440
mke2fs vdiek 1440
可在一个名为vdisk的虚拟磁盘文件上创建一个EXT2文件系统,有1440个大小为1KB的块。
1.2.2 虚拟磁盘布局
上述EXT2文件系统的布局如图11.1所示:

一开始,我们先使用这个基本文件系统布局进行假设。在适当的时候,我们会指出一些变化,包括硬盘上大型EXT2/3文件系统中的变化。下面来简要解释一下磁盘块的内容。
Block#0:引导块B0是引导块,文件系统不会使用它。它用来容纳一个引导程序,从磁盘引导操作系统。
1.2.3 超级块
Block#1:超级块(在硬盘分区中字节偏移量为1024)B1是超级块,用于容纳整个文件系统的信息。下文说明了超级块结构中的一些重要字段。
struct ext2_auper_block{
u32 s_inodes_count; /*Inodes count */
u32 s_blocks_count; /*Blocks count */
u32 s_r_blocks_count; /*Reserved blocks count */
u32 s_free_blocks_count; /*Free blocks count */
u32 s_free_inodes_count; /*Free inodes count */
u32 s_first_data_block; /*First Data Block */
u32 s_log_block_size; /*Block size */
u32 s_log_cluster_size; /*Allocation cluster size */
u32 s_blocks_per_group; /*# Blocks per group */
u32 s_clusters_per_group; /*# Fragments per group */
u32 s_inodes_per_group; /*# Inodes per group */
u32 s_mtime; /*Mount time */
u32 s_wtime; /*Write time */
U16 s_jnnt_count; /*Mount count */
S16 s_max_mnt_count; /*Maximal mount count */
ul6 s_magic; /*Magic signature */
// more non-essential fields
ul6 s_inode_size; /* size of inode structure */
}
大多数超级块字段的含义都非常明显。只有少数几个字段需要详细解释。
- s_first_data_block:0表示4KB块大小,1表示1KB块大小。它用于确定块组描述符的起始块,即 s_first_data_block+1。
- s_log_block_size:确定文件块大小,为1KB*(2**s_log_block_size),例如:0表示1KB块大小,1表示2KB块大小,2表示4KB块大小等。最常用的块大小是用于小文件系统的1KB和用于大文件系统的4KB。
- s_mnt_count:已挂载文件系统的次数。当挂载计数达到max_mnt_count时,fsck会话将被迫检查文件系统的一致性。
- s_magic:标识文件系统类型的幻数。EXT2/3/4文件系统的幻数是0xEF53。
1.2.4 块组描述符
Block#2:块组描述符块(硬盘上的s_first_data_block+1) EXT2将磁盘块分成几个组。 每个组有8192个块(硬盘上的大小为32K)。每组用一个块组描述符结构体来描述。
struct ext2_group_desc{
u32 bg_block_bitmap; //Bmap block number
u32 bg_inode_bicmap; //Imap block number
u32 bg_inode_table; //Inodes begin block number
ul6 bg_free_blocks_count; //THESE are OBVIOUS
U16 bg_free_inodes_count;
U16 bg_used_dirs_count;
ul6 bg_pad; //ignore these
u32 bg_reserved(3);
};
由于一个虚拟软盘(FD)只有1440个块,B2就只包含一个块组描述符。其余的都是0。在有大量块组的硬盘上,块组描述符可以跨越多个块。块组描述符中最重要的字段是bg_block_bitmap、bg_inode_bitmap和bg_inode_table,它们分别指向块组的块位图、索引节点位图和索引节点起始块。对于Linux格式的EXT2文件系统,保留了块3到块7。所以bmap=8,imap=9,inode_table= 10。
1.2.5 块和索引点位图
Block#8:块位图(Bmap)(bg_block_bitmap)位图是用来表示某种项的位序列,例如磁盘块或索引节点。位图用于分配和回收项。在位图中,0位表示对应项处于FREE状态,1位表示对应项处于IN_USE状态。一个软盘有1440个块,但是Block#。未被文件系统使用。所以,位图只有1439个有效位。无效位被视作IN_USE,设置为1。
Block#9:索引节点位图(Imap)(bg_inode_bitmap)一个索引节点就是用来代表一个文件的数据结构。EXT2文件系统是使用有限数量的索引节点创建的。各索引节点的状态用B9的Imap中的一个位表示。在EXT2 FS中,前10个索引节点是预留的。所以,空EXT2 FS的Imap以10个1开头,然后是0。无效位再次设置为1。
1.2.6 索引节点
Block#10:索引(开始)节点(bg_inode_table)每个文件都用一个128字节的唯一索引节点结构体表示。下面列出了主要索引节点字段。
struct ext2_inode {
ul6 i_mode; //16 bits = |tttt|ugs|rwx|rwx|rwx|
ul6 i_uid; //owner uid
u32 i_size; //file size in bytes
u32 i_atime; //time fields in seconds
u32 i_ctime; //since 00:00:00,1-1-1970
u32 i_mtime;
u32 i__dtime;
U16 i_gid; //group ID
u16 i_links_count; //hard-link count
u32 i_blocks; //number of 512-byte sectors
u32 i_flags; //IGNORE
u32 i_reserved1; //IGNORE
u32 i_block[15]; //See details below
u32 i_pad[7];; //for inode size = 128 bytes
}
在索引节点结构体中,i_mode为U16或2字节无符号整数。

在i_mode字段中,前4位指定了文件类型,例如:tttt=1000表示REG文件,0100表 示DIR文件等。接下来的3位ugs表示文件的特殊用法。最后9位是用于文件保护的rwx权限位。
i_size字段表示文件大小。各时间字段表示自1970年1月1日0时0分0秒以来经过的秒数。所以,每个时间字段都是一个非常大的无符号整数:可借助以下库函数将它们转换为日历形式:
char *ctime (&time_field)
将指针指向时间字段,然后返回一个日历形式的字符串。例如:
printf("%s", ctime(&inode.i_atime); // note: pass & of time field prints i_atime in calendar form.
i_block[15]数组包含指向文件磁盘块的指针,这些磁盘块有:
- 直接块:i_block[0] Mi_block[11],指向直接磁盘块。
- 间接块:i_block[12]指向一个包含256个块编号的磁盘块,每个块编号指向一个磁盘块。
- 双重间接块:i_block[13]指向一个指向256个块的块,每个块指向256个磁盘块。
- 三重间接块:i_block[14]是三重间接块。对于“小型” EXT2文件系统,可以忽略它。
索引节点大小(128或256 )用于平均分割块大小(1KB或4KB),所以,每个索引节点块都包含整数个索引节点在简単的EXT2文件系统中,索引节点的数量是184个(Linux默认值)。索引节点块数等于184/8-23个。因此,索引节点块为B10至B32。每个索引节点都有一个唯一的索引节点编号,即索引节点在索引节点块上的位置+1。注意,索引节点位置从0开始计数,而索引节点编号从1开始计数。0索引节点编号表示没有索引节点一根目录的索引节点编号为2。同样,磁盘块编号也从1开始计数,因为文件系统从未使用块0。块编号0表示没有磁盘块。
1.2.7 数据块
紧跟在索引节点块后面的是文件存储数据块,假设有184个索引节点,第一个实际数据块是B33,它就是根目录/的i_block[0]。
1.2.8 目录条目
目录包含dir_entry结构,即
struct ext2_dir_entry_2{
U32 inode; //inode number; count from 1; NOT 0
U16 rec_len; //this entry's length in bytes
U8 name_len; //name length in bytes
u8 file_type; //not used
char name[EXT2_NAME_LEN]; //name:1-255 chars, no ending NULL
dir_entry是一种可扩充结构。名称字段包含1到255个字符,不含终止NULL。所以 dir_entry的rec_len也各不相同。
2 实践内容与截图
2.1 dd命令
2.1.1 dd命令的默认用法
dd命令用于转换和复制文件,与其他的 Linux 程序不同,因为它的命令行选项格式为 选项=值,而不是更标准的 --选项 值 或 -选项=值。dd 默认从标准输入中读取,并写入到标准输出中,但可以用选项 if(input file,输入文件)和 of(output file,输出文件)改变。
通过学习后我发现,dd命令就是默认从标准输入中读取,并写入到标准输出中去,通过if选项,我们可以改变标准读入的位置,而通过of选项,我们可以改变标准输出的位置。
同时,参数bs(block size)用于指定块大小(缺省单位为 Byte),count 用于指定块数量。
如下图,当我们不加if和of参数时,dd命令会调用默认输入和默认输出,即从命令行输入(/dev/stdin),从命令行输出(/dev/stdout):
dd bs=10 count=1
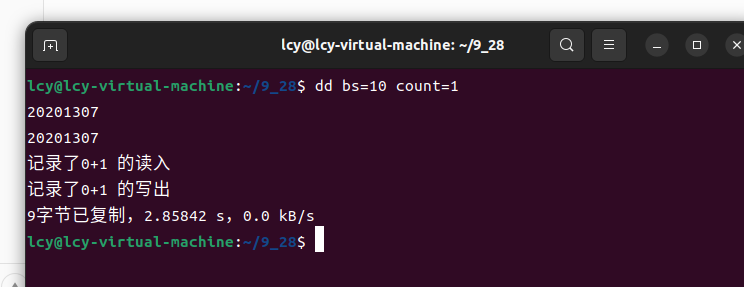
同样,当我们输入加上(/dev/stdin和/dev/stdout)时,具有和上面同样的效果
dd if=/dev/stdin of=/dev/stdout bs=10 count=1
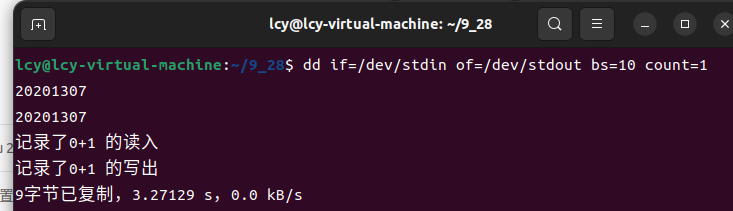
这时我们可能注意到,如果我们输入的字符串长度大于10个字符,会发生什么呢?
我们重复上述命令,但是这时我们输入11个字符,如:20201307lcy,结果如下图:
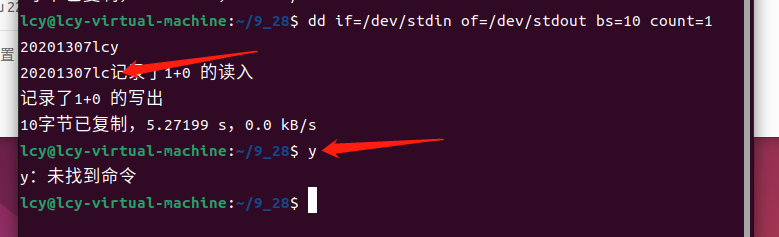
这时我们发现dd命令仅能读取到第10个字符c,而对于第11个字符y,并未能正常读取并打印,而是被输进了下一个命令行之中,所以我们在使用dd命令时,要注意输入的长度小于count所规定的值。
这时细心的同学可能会想到,如果我们恰好输入10个字符,即输入长度等于count的值,会发生什么呢?
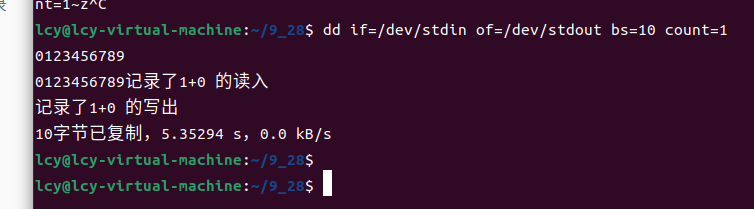
此时我们发现,换行符的读入出了小问题,被自动打在命令行中了,导致命令行空过了一行。
当我们在命令行中输入9个字符时,又会发生什么呢?
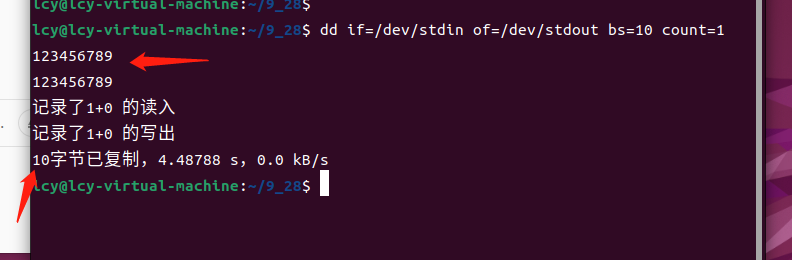
此时我们发现,我们只键入了9个数字,但系统却显示复制了10字节,这是因为dd命令在复制时把换行符也算在内了。
通过这个现象我们可以发现,输入的换行符也会算在读入字符中,所以我们在使用时也要考虑换行符,这时我们规定dd命令中的count参数可以适当增加1位。
2.1.2 dd命令的if、of参数
如上文,if参数与of参数可以使我们把dd命令从标准读入输出改变为自己想要的路径,下面我将逐步演示这个过程
(一)标准读入,自定义输出
自定义输出代表我们需要改写of参数,使输出从默认的命令行转移到我们想要的位置。
首先确保你想要写入的位置存在一个文件,然后把该文件的路径赋给of参数,例如:
dd of=/home/lcy/9_28/test1.txt bs=10 count=1
此时我们输入数据后,dd命令会把该数据写入到你所赋给of参数的路径:
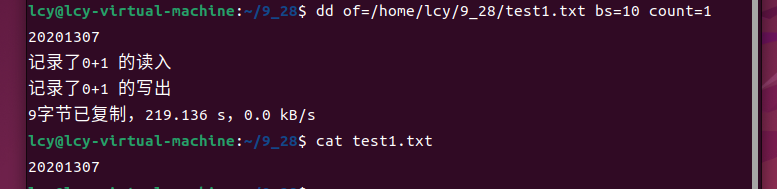
(二)自定义输入,标准输出
自定义输入代表我们需要改变if参数的值,把它改为我们想要读入文件的路径即可,之后我们会发现,不在需要从键盘中键入字符就可以直接输出:
dd if=/home/lcy/9_28/test1.txt bs=10 count=1
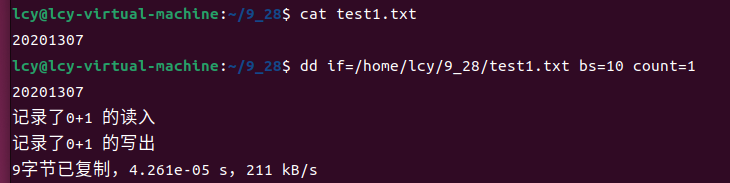
(三)自定义输入、自定义输出
读入和写出都想改为自定义的形式,需要我们同时修改if和of参数,这是我们可以发现,此时的dd命令与Linux
中的cp命令类似,如下图:
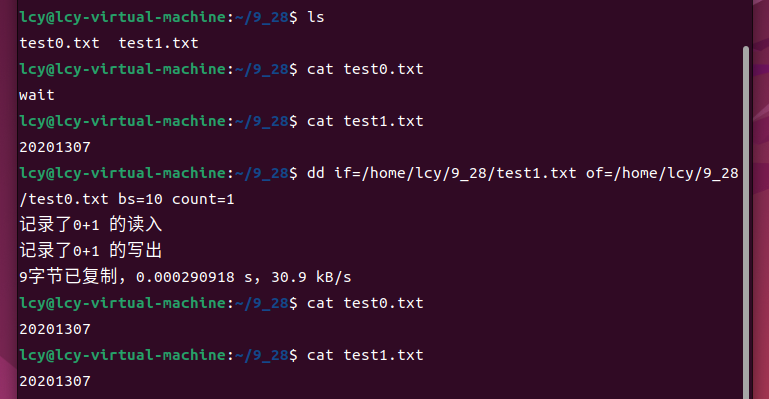
dd if=/home/lcy/9_28/test1.txt of=/home/lcy/9_28/test0.txt bs=10 count=1
实现了把test1.txt复制给test0.txt的过程
2.1.3 dd命令的conv参数
conv参数有以下11种:
- conversion:用指定的参数转换文件。
- ascii:转换ebcdic为ascii
- ebcdic:转换ascii为ebcdic
- ibm:转换ascii为alternate ebcdic
- block:把每一行转换为长度为cbs,不足部分用空格填充
- unblock:使每一行的长度都为cbs,不足部分用空格填充
- lcase:把大写字符转换为小写字符
- ucase:把小写字符转换为大写字符
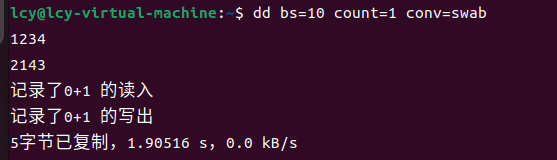
- swab:交换输入的每对字节
- noerror:出错时不停止
- notrunc:不截短输出文件
- sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
我们也可以通过man dd命令来查看dd命令的具体参数

我们以参数swab为例演示:
2.2 使用dd命令创建虚拟镜像文件
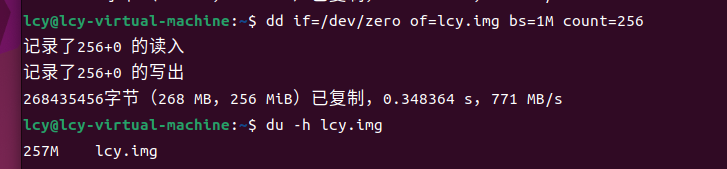
dd if=/dev/zero of=lcy.img bs=1M count=256
du -h lcy.img
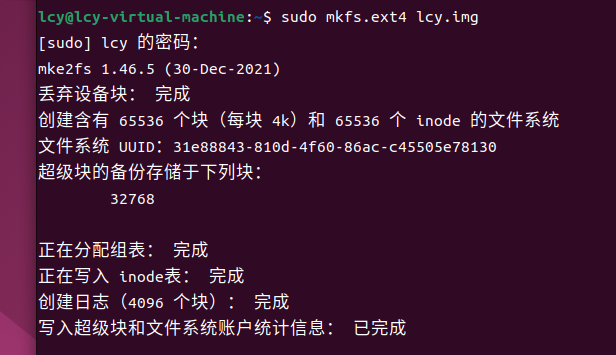
2.3 使用 mkfs 命令格式化磁盘
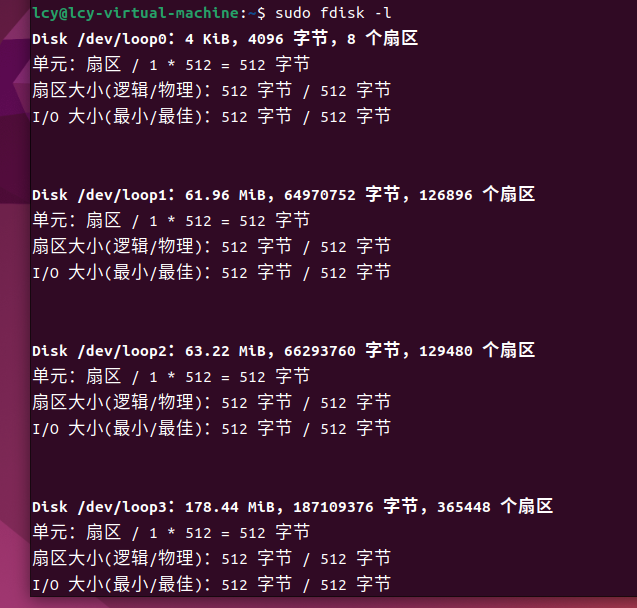
2.4 查看硬盘分区表信息
3 问题与解决方式
问题:对于超级块的理解不是很深。书上写的不是很明确
解决方案:学习链接:Linux虚拟文件系统
4 总结
本章主要讨论了EXT2文件系统,我对于本章设计到的dd、mkfs命令已经掌握的很好了,之后本章又有一些比较抽象的概念描述, 例如超级块、inode、dentry等,我也是通过大量的资料搜集才明白了一些,但是我对于dd命令的总结还是很到位的,也彻底明白了,希望能继续保持这样的状态。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
2020-10-02 2020-2021-1 20201307 《信息安全专业导论》第一周学习总结