
第七周学习总结
2020-2021-1 20201307 《信息安全专业导论》第7周学习总结
作业信息
教材学习内容总结
本周在计算机科学概论这本书中学习了第8章,抽象数据类型与子程序,首先学习的是列表,栈(stack),队列(queue)和图(graph),他们对数据的处理过程不同,有自己的特点,二叉树倒是比较有趣的一种算法,从上到下,由亲代传到子代。在程序设计导论中最重要的是学到了字典这一东西,可以用于我的自定义索引,还有我的一个之前学过的模块random,随机选择。
教材学习中的问题及解决过程
1.抽象数据类型的属性是否与该数据类型的实现层紧密相关?抽象数据类型的属性是否与该数据类型的实现层紧密相关,那么什么是这个视图?是实现层吗?
回答:这个视图是指在抽象数据类型中,特定问题中的数据的视图,实现层只明确的表示了存放数据项的结构,并用程序设计语言对数据的操作进行编码。而应用(或用户层)是特定问题中的数据的视图,所以抽象数据类型的属性和数据类型的应用(用户)层有关。
2.深度优先搜索和广度优先搜索的区别是啥?
回答:上网查找资料:https://blog.csdn.net/qq_35558364/article/details/102673776
网站上给的例子特别鲜明,以二叉数为例,深度优先搜索就是按照一条路一直走下去,走到终点之后换下一条路搜索,广度优先搜索就是先搜寻同一级的所有值,然后再换下一层,和他们的名字很像
代码调试的问题和解决过程
在学习字典这一内容时,我在云班课上看到了这样的问题
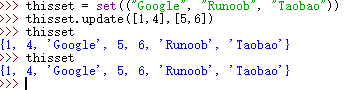
就是说,在对字典进行更新时,为什么字典中元素的顺序会改变,有什么规律吗
我通过上网学习后,亲自验证测试给出了这样的答案
因为元素存储到dict的时候,都经过hash()计算,且存储的实际上是key对应的hash值,所以dict中各个元素是无序的,或者说无法保证顺序
也就是说,字典更新后中元素的排列顺序是依据哈希值来排的,而我几周前刚刚学习了哈希加密,能把学习的东西结合起来很开心
感悟
-
字典是实现我个性化检索的重要工具,顺序的排列是按每个元素的哈希值
-
在书上看不懂的东西可能在网上有很鲜明直观的讲解,要学会及时转向
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | ||
|---|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | ||
| 第一周 | 65/65 | 2/2 | 17/17 | ||
| 第二周 | 65/130 | 4/6 | 10/27 | ||
| 第三周 | 260/390 | 3/9 | 20/47 | ||
| 第四周 | 60/450 | 2/11 | 10/57 | ||
| 第五周 | 300/750 | 2/13 | 10/67 | ||
| 第六周 | 330/1080 | 3/16 | 10/77 | ||
| 第七周 | 400/1480 | 1/17 | 12/90 |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术