
python3 爬虫
一.网络爬虫(Web Crawler)
1.网络爬虫:是一种按照一定的规则,自动地抓取网上信息的程序或者脚本。
2.爬虫:为了获取网上大量的我们能看的到或看不到的数据
3.基本步骤:(1)定位要爬的网页地址;(2)获取网址的html文档;(3)解析网址的html文档;(4)搜寻要下载的数据并保存到本地;(5)循环上面四步
4.爬虫改进:(1)若要爬取的信息较多,应考虑开启多个线程或用分布式架构去并发地爬取网页,负载均衡;(2)对于不同各个url,应区别对待,设定优先级;(3)DNS缓存;(4)网页去重;(5)数据存储;(6)进程间通信...
二.HTML 简介
1.HTML 教程:http://www.w3school.com.cn/html/html_primary.asp
2.HTML 指的是超文本标记语言 (Hyper Text Markup Language),是一种标记语言,使用标记标签来描述网页。即:HTML 文档 (嵌套的元素)(标签+文本)= 网页
3.HTML 元素:(1)指的是从开始标签到结束标签的所有代码(2)大多数 HTML 元素可拥有属性(3)大多数 HTML 元素可以嵌套(4)HTML元素包括:标签、属性、内容
4.HTML 标签(tag):(1)由尖括号包围的关键词,比如<xxx>(2)成对出现(起始和结束),比如<xxx>和</xxx>,(开始标签和 ' /' 结束标签)
5.HTML 属性:(1)属性提供了有关 HTML 元素的更多的信息(2)属性总是以名称/值对的形式出现,比如:name="value"(3)属性总是在 HTML 元素的开始标签中规定
6.URL(Uniform Resource Locator):统一资源定位符,也被称为网页地址,简称网址。一般是由模式(或称协议)、服务器名称(或IP地址)、域名和根目录下的默认网页组成。比如:https://baike.baidu.com/item/url/110640?fr=aladdin
7.一些基本标签:(1)<html>HTML文档</html>(2)<head>文档信息</head>(3)<body> 文档主体(可见的页面内容)</body>(4)<h1>HTML标题 </h1>(h1大标题-h6小标题)
(5)<p>段落 </p> ;(5)<a>超链接</a>(6)<img>图像(7)<div>文档中的一个部分</div>(8)<base>页面中所有链接的基准 URL</base>(9)<span>组合文档中的行内元素</span>
8.一些基本属性:(1)class 规定元素的类名(2)title 规定有关元素的额外信息(3)id规定元素的唯一 ID(4)href 指向另一个文档的链接(5)name 文档内的书签(#使用)(6)src 源属性
二.定位要爬的网页地址
1.推荐使用浏览器chorme和firefox
2.检查单个元素:在待爬网页上,在待爬内容上,右击:检查;可以直接查看该内容的相关html描述,双击选择,复制
3.查看html结构和通信记录:F12开发者工具---network(刷新)---选择要查看的内容的类型(img图像,或doc文档,或者其他)---在name栏选择要的内容(根据preview预览对比)---查看该内容的url:(headers---general---request URL),然后复制
三.利用代码获取网页HTML文档
1.urllib库--urlopen().read().decode()


1 from urllib.request import urlopen
2 url='https://baike.baidu.com/item/url'
3 html = urlopen(url).read().decode('utf-8')
4 #urlopen打开网页的链接,read读取,decode解码
5 print(html)
6 --------------------------------------------------------------
7 <!DOCTYPE html>
8 <!--STATUS OK-->
9 <html>
10
11
12
13 <head>
14 <meta charset="UTF-8">
15 <meta http-equiv="X-UA-Compatible" content="IE=Edge" />
16
17 .........................
18
19 .src=d+"?v="+~(new Date/864e5)+~(new Date/864e5),f=b.getElementsByTagName(c)[0],f.parentNode.insertBefore(e,f)}),j())}}(window,document,"script","/hunter/alog/dp.min.js");
20 </script>
21 </html>
1 from urllib import request
2 url='https://baike.baidu.com/item/url'
3 html=request.urlopen(url).read().decode('utf-8')
4 print(html)
5 ------------------------------------
6 <!DOCTYPE html>
7 <!--STATUS OK-->
8 <html>
9
10
11
12 <head>
13 <meta charset="UTF-8">
14 <meta http-equiv="X-UA-Compatible" content="IE=Edge" />
15
16 ...............................
17
18 .insertBefore(e,f)}),j())}}(window,document,"script","/hunter/alog/dp.min.js");
19 </script>
20 </html>
2.requests库:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
(1)get方法:发送请求,返回包含网页数据的response,可以搭配一些关键字
1 import requests
2 url='https://baike.baidu.com/item/url'
3 html=requests.get(url,allow_redirects=False)
4 #get获取网页回应;allow_redirects=False禁止重定向
5 print(type(html))
6 print(html)#response对象的属性
7 print("#"*60)
8
9 #添加关键字
10 param = {"wd": "url"} # 关键字
11 r=requests.get(url,params=param,allow_redirects=False)
12
13 #(1)直接打开网页
14 import webbrowser
15 webbrowser.open(r.url)#浏览器自动打开链接
16
17 #(2)显示html文档
18 html=r.text.encode(r.encoding).decode('utf-8')#对应文本进行编码解码,text方法获取文本
19 print(html)
20 ----------------------------------------------------------------------
21 <class 'requests.models.Response'>
22 <Response [302]>
23 ############################################################
24 <html>
25 <head><title>302 Found</title></head>
26 <body bgcolor="white">
27 <center><h1>302 Found</h1></center>
28 <hr><center>nginx</center>
29 </body>
30 </html>
(2)post方法:给服务器发送个性化请求,比如将你的账号密码传给服务器, 让它给你返回一个含有你个人信息的HTML
1 import requests
2 url="http://httpbin.org/post"
3
4 #发送请求
5 #请求登录,data(登录信息)(form表单)
6 payload = {'key1': 'value1', 'key2': 'value2'}
7 r = requests.post(url, data=payload)
8 print(r.text)
9
10 #请求上传文件
11 file = {'uploadFile': open('./image.png', 'rb')}
12 r1 = requests.post(url,files=file)
13 print(r1.text)
14
15 #登录使用 1.post 方法登录了第一个 url;2.post 的时候, 使用了 Form data 中的用户名和密码;3.生成了一些 cookies
16 #因为打开网页时, 每一个页面都是不连续的, 没有关联的, cookies 就是用来衔接一个页面和另一个页面的关系
17 # 比如说当我登录以后, 浏览器为了保存我的登录信息, 将这些信息存放在了 cookie 中.
18 # 然后我访问第二个页面的时候, 保存的 cookie 被调用, 服务器知道我之前做了什么, 浏览了些什么.
19 print(r.cookies.get_dict())#返回r中生成的cookie信息
20 r = requests.get('http://pythonscraping.com/pages/cookies/profile.php', cookies=r.cookies)
21 #使用cookie请求登录
22 print(r.text)
23 ----------------------------------------------------------------
24 {"args":{},"data":"","files":{},"form":{"key1":"value1","key2":"value2"},"headers":{"Accept":"*/*","Accept-Encoding":"gzip, deflate","Connection":"close","Content-Length":"23","Content-Type":"application/x-www-form-urlencoded","Host":"httpbin.org","User-Agent":"python-requests/2.18.4"},"json":null,"origin":"58.223.192.18","url":"http://httpbin.org/post"}
25
26 {"args":{},"data":"","files":{"uploadFile":"data:application/octet-stream;base64,iVBORw0KGgoAAAANSUhEUgAAAgsAAAKUCAYAAACKb3tYAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsMAAA7DAcdvqGQAAEOPSURBVHhe7d3P6xzXlf///B1a6i/Q0mTxMQyMV9ZuDLMQDNaILCIYyIgPBPGBQRgkYfgSnEUQA4P4QhDWmK
27 ...................................
28 </div> <!-- /#wrap --> </body>
29 </html>
(3)session登录:在一次会话(session)中, 我们的 cookies 信息都是相连通的,session自动帮我们传递这些 cookies 信息.
1 import requests
2 s = requests.Session()#获取会话对象,其中保存了cookie以及其他一些信息
3 s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
4 r = s.get("http://httpbin.org/cookies")
5 print(r.text)
6
7 r1 = s.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
8 print(r1.text)
9
10 r2 = s.get('http://httpbin.org/cookies')
11 print(r2.text)
12 -------------------------------------------------------
13 {"cookies":{"sessioncookie":"123456789"}}
14
15 {"cookies":{"from-my":"browser","sessioncookie":"123456789"}}
16
17 {"cookies":{"sessioncookie":"123456789"}}
(4)requests相关:


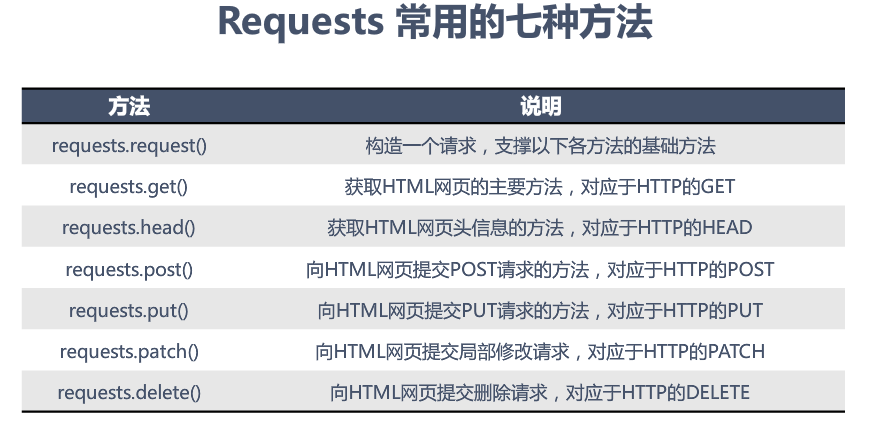
四.解析网页
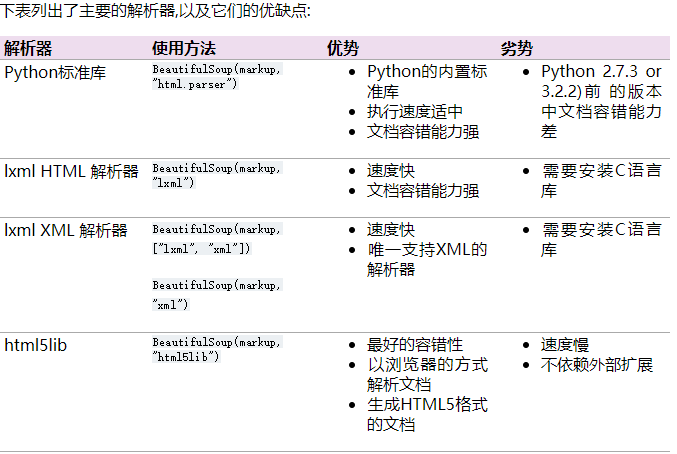
1.BeautifulSoup:实质上把获取的网页字符串变成一个benutifulsoup对象,该对象与原网页相对应,比如soup.head对应原网页head部分
(1)https://www.crummy.com/software/BeautifulSoup/bs4/doc/
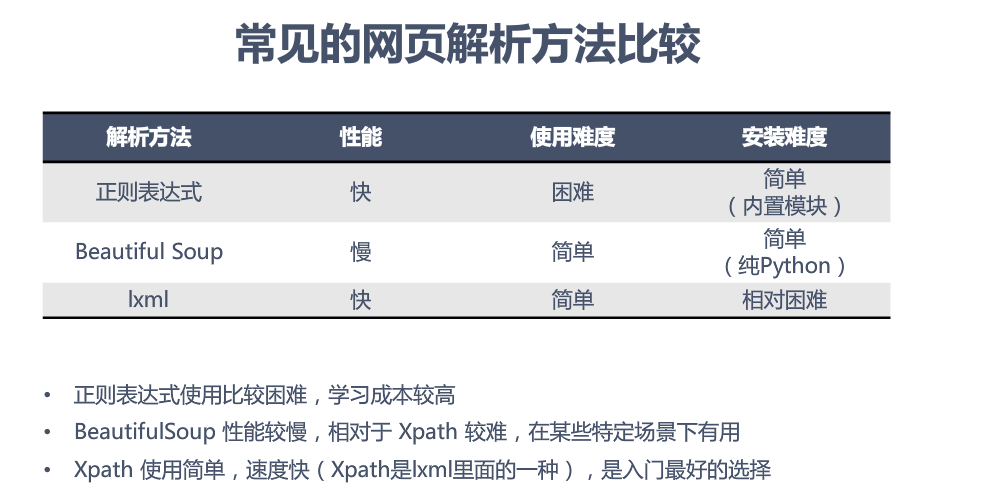
(2)beautifulsoup支持的解析器,一般选择使用lxml解析器,需自己安装
1 from urllib.request import urlopen
2 url='https://baike.baidu.com/item/url'
3 html = urlopen(url).read().decode('utf-8')#html文档字符串
4
5 from bs4 import BeautifulSoup#BeautifulSoup4库
6 soup = BeautifulSoup(html, features='lxml')
7 #把html以lxml的方式解析加载进beautifulsoup,然后soup中有着html的所有信息
8 #如果你要输出 <h1> 标题, 可以就直接 soup.h1
9 # print(soup)
10 # print(soup.prettify())#格式化输出soup对象的内容
11 print(soup.h1)#获取h1的内容
12 print(soup.p)#获取<p>的内容
13 print(soup.name)#获取名字
14 print(soup.attrs)#获取属性
15 print(soup.p.attrs)#获取<p>中属性attrs
16 soup.p['title']='修改属性'#修改内容或属性
17 print(soup.p)
18 del soup.p['title']#删除属性
19 print(soup.p)
20 -----------------------------------------------------------------
21 <h1>url</h1>
22 <p title="致力于权威的科学传播">致力于权威的科学传播</p>
23 [document]
24 {}
25 {'title': '致力于权威的科学传播'}
26 <p title="修改属性">致力于权威的科学传播</p>
27 <p>致力于权威的科学传播</p>
1 from bs4 import BeautifulSoup#BeautifulSoup4库
2 soup = BeautifulSoup(html, features='lxml')
3
4 print(soup.a)#找到soup的第一个a,相当于find
5 print(soup.find('a'))#返回包含一个元素的列表,
6
7 # find_all(self, name=None, attrs={}, recursive=True, text=None,limit=None, **kwargs)
8 print(soup.find_all('a',href= 'https://www.baidu.com/' ))#找到a中满足herf属性的内容,列表
9 all_href = soup.find_all('a')#找到所有的<a>的内容,列表形式
10 # print(all_href)
11 all_href1 = [l['href'] for l in all_href[0:10]]#显示前10个链接,用key来读取l["href"],可以看做a中的属性
12 print(all_href1)
(3)解析网页CSS:CSS 主要用途就是装饰你 “骨感” HTML 页面;https://www.w3schools.com/css/;CSS 的 Class(类):CSS 在装饰每一个网页部件的时候, 都会给它一个名字. 而且一个类型的部件, 名字都可以一样.
1 from bs4 import BeautifulSoup#BeautifulSoup4库
2 soup = BeautifulSoup(html, features='lxml')
3
4 print(soup.select('h1'))#通过标签查找,找出含有h1标签的元素
5 print(soup.select('#title'))#通过id查找,找出id为title的元素,id前面加#
6 print(soup.select('.link'))#通过类名查找,找出class为link的元素,class前面加.
7 print(soup.select('a[href="https://www.baidu.com/"]'))#属性查找,属性用中括号括起
8 print(soup.select('h1 #url'))#组合查找,查找h1标签中,id等于url的内容
9 print(soup.select('head > h1'))#组合查找,直接子标签查找
10 ------------------------------------------------------------------------
11 [<h1>url</h1>]
12 []
13 []
14 [<a data-href="https://www.baidu.com/s?ie=utf-8&fr=bks0000&wd=" href="https://www.baidu.com/" nslog="normal" nslog-type="10600112">网页</a>]
15 []
16 []
2.re正则表达式:匹配字符串,与beautifulsoup配合使用
1 import re
2 #爬取图片链接,图片<td><img src...>
3 img_links = soup.find_all("img", {"src": re.compile('.*?\.jpg')})
4 #r'.*?\.jpg'选取jpg形式的图片
5 print(img_links)#tag
6 print('*'*60)
7 for link in img_links:
8 print(link['src'])
9 print('*'*60)
10
11 #找到以。。。开头的链接
12 course_links = soup.find_all('a', {'href': re.compile('/science.*')})
13 for link in course_links:
14 print(link['href'])
15 ------------------------------------------------------------------
16 [<img src="https://gss0.bdstatic.com/94o3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=1cb342771ad8bc3ec60801ccbab0c123/279759ee3d6d55fbc2c9816b6e224f4a20a4dd74.jpg"/>, <img alt="权威编辑" onload="this.style.width = '50px';this.style.display='';" src="https://baike.baidu.com/cms/rc/QQ%E5%9B%BE%E7%89%8720141121003618.jpg" style="display: none" title="权威编辑"/>]
17 ************************************************************
18 https://gss0.bdstatic.com/94o3dSag_xI4khGkpoWK1HF6hhy/baike/w%3D268%3Bg%3D0/sign=1cb342771ad8bc3ec60801ccbab0c123/279759ee3d6d55fbc2c9816b6e224f4a20a4dd74.jpg
19 https://baike.baidu.com/cms/rc/QQ%E5%9B%BE%E7%89%8720141121003618.jpg
20 ************************************************************
21 /science
22 /science/medicalcenter?lemmaId=110640&name=%E5%BC%A0%E6%96%B0%E7%94%9F&fromModule=professional
23 /science/medicalcenter?lemmaId=110640&name=%E5%BC%A0%E8%8B%B1%E6%B5%B7&fromModule=professional
24 /science/medicalcenter?lemmaId=110640&name=%E6%AF%9B%E8%B0%A6&fromModule=professional
25 /science/medicalcenter?lemmaId=110640&name=%E5%94%90%E9%9B%84%E7%87%95&fromModule=professional
26 /science/medicalcenter?lemmaId=110640&name=%E4%BD%95%E5%AE%9D%E5%AE%8F&fromModule=professional
27 /science/medicalcenter?lemmaId=110640&name=%E8%92%8B%E8%BF%9C&fromModule=professional
28 /science/medicalcenter?lemmaId=110640&name=%E7%BD%97%E5%9C%A3%E7%BE%8E&fromModule=professional
29 /science/medicalcenter?lemmaId=110640&name=%E7%8E%87%E9%B9%8F&fromModule=professional
3.xpath(XML路径语言)(XML Path Language):用来确定XML文档中某部分位置
1 from lxml import etree
2 url='https://baike.baidu.com/item/url'
3 s=etree.HTML(url)
4 print(s)
5 film=s.xpath('/html/body/div[4]/div[2]/div/div[2]/div[3]/div/a')
6 print(film)
7 -----------------------------
8 <Element html at 0xc53e4e0>
9 []
五.存储数据
1.操作文件夹和文件---os
2.分析和存储表格型数据---pandas
3.存储数据到mysql---pymysql
4.存储数据到SQLite---sqlite3
5.解析API返回的Json数据---json
6....
1 #下载文件
2 #1.通过检查文件,查找文件存储的src
3 #2.通过网页原来的url和src补全文件的完整url
4 #3.通过链接下载文件到文件夹
5 import os
6 os.makedirs('./img/', exist_ok=True)
7 #下载到特定文件夹中,如果没有就创建一个
8 IMAGE_URL = "https://morvanzhou.github.io/static/img/description/learning_step_flowchart.png"
9 #规定图片下载地址
10
11 ################################
12 # #methods 1
13 from urllib.request import urlretrieve#下载功能 urlretrieve
14 #输入下载地址 IMAGE_URL 和要存放的位置. 图片就会被自动下载过去了
15 urlretrieve(IMAGE_URL, './img/image1.png') # whole document
16
17 ################################
18 # ##methods 2下载大文件
19 import requests
20 r = requests.get(IMAGE_URL)#获得链接
21 with open('./img/image2.png', 'wb') as f:#文件写入
22 f.write(r.content) # whole document整个文件的写入
23
24 #stream能让你下一点, 保存一点, 而不是要全部下载完才能保存去另外的地方.
25 r = requests.get(IMAGE_URL, stream=True) # stream loading流动性下载
26 with open('./img/image3.png', 'wb') as f:
27 # 这就是一个chunk一个chunk的下载.使用r.iter_content(chunk_size)来控制每个chunk的大小,
28 # 然后在文件中写入这个chunk大小的数据.
29 for chunk in r.iter_content(chunk_size=32):#写入
30 f.write(chunk)
1 #先找带有 img_list 的这种 <ul>, 然后在 <ul> 里面找 <img>
2 from bs4 import BeautifulSoup
3 import requests
4 URL = "http://www.nationalgeographic.com.cn/animals/"
5
6 html= requests .get(URL).text#通过url获取html文本
7 soup = BeautifulSoup(html, 'lxml')#解析
8 img_ul = soup.find_all('ul', {"class": "img_list"})#在ul中找class=img_list的内容
9
10 import os
11 os.makedirs('./img/', exist_ok=True)#创建存储的文件夹
12 #从 ul 中找到所有的 <img>, 然后提取 <img> 的 src 属性, 里面的就是图片的网址啦.
13 # 接着, 就用之前在 requests 下载那节内容里提到的一段段下载
14 for ul in img_ul:
15 imgs = ul.find_all('img')
16 for img in imgs:
17 url = img['src']
18 r = requests.get(url, stream=True)
19 image_name = url.split('/')[-1]
20 with open('./img/%s' % image_name, 'wb') as f:
21 for chunk in r.iter_content(chunk_size=128):
22 f.write(chunk)
23 print('Saved %s' % image_name)
六.循环爬取
1 his = ["/item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711"]
2
3 for i in range(20):#随机爬虫,循环20次
4 url = base_url + his[-1]
5
6 html = urlopen(url).read().decode('utf-8')
7 soup = BeautifulSoup(html, features='lxml')
8 print(i, soup.find('h1').get_text(), ' url: ', his[-1])
9
10 # find valid urls
11 sub_urls = soup.find_all("a", {"target": "_blank", "href": re.compile("/item/(%.{2})+$")})
12
13 if len(sub_urls) != 0:
14 his.append(random.sample(sub_urls, 1)[0]['href'])
15 else:
16 # no valid sub link found
17 his.pop()
18 ---------------------------------------------------------------------------
19 0 网络爬虫 url: /item/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/5162711
20 1 开放源代码 url: /item/%E5%BC%80%E6%94%BE%E6%BA%90%E4%BB%A3%E7%A0%81
21 2 林纳斯·托瓦兹 url: /item/%E6%9E%97%E7%BA%B3%E6%96%AF%C2%B7%E6%89%98%E7%93%A6%E5%85%B9
22 3 理查德·斯托曼 url: /item/%E7%90%86%E6%9F%A5%E5%BE%B7%C2%B7%E6%96%AF%E6%89%98%E6%9B%BC
23 4 布鲁塞尔大学 url: /item/%E5%B8%83%E9%B2%81%E5%A1%9E%E5%B0%94%E5%A4%A7%E5%AD%A6
24 5 卢森堡 url: /item/%E5%8D%A2%E6%A3%AE%E5%A0%A1
25 6 基督教社会党 url: /item/%E5%9F%BA%E7%9D%A3%E6%95%99%E7%A4%BE%E4%BC%9A%E5%85%9A
26 7 基督教社会党 url: /item/%E5%9F%BA%E7%9D%A3%E6%95%99%E7%A4%BE%E4%BC%9A%E5%85%9A
27 8 成立 url: /item/%E6%88%90%E7%AB%8B
28 9 行政部门 url: /item/%E8%A1%8C%E6%94%BF%E9%83%A8%E9%97%A8
29 10 三权分立 url: /item/%E4%B8%89%E6%9D%83%E5%88%86%E7%AB%8B
30 11 行政部门 url: /item/%E8%A1%8C%E6%94%BF%E9%83%A8%E9%97%A8
31 12 立法权 url: /item/%E7%AB%8B%E6%B3%95%E6%9D%83
32 13 三权分立 url: /item/%E4%B8%89%E6%9D%83%E5%88%86%E7%AB%8B
33 14 立法权 url: /item/%E7%AB%8B%E6%B3%95%E6%9D%83
34 15 何兆武 url: /item/%E4%BD%95%E5%85%86%E6%AD%A6
35 16 口述历史 url: /item/%E5%8F%A3%E8%BF%B0%E5%8E%86%E5%8F%B2
36 17 何兆武 url: /item/%E4%BD%95%E5%85%86%E6%AD%A6
37 18 梁思成 url: /item/%E6%A2%81%E6%80%9D%E6%88%90
38 19 程应铨 url: /item/%E7%A8%8B%E5%BA%94%E9%93%A8
七.加速爬虫
1 import multiprocessing as mp
2 import time
3 from urllib.request import urlopen, urljoin
4 from bs4 import BeautifulSoup
5 import re
6
7 #一般爬虫
8 base_url = "http://127.0.0.1:4000/"
9 # base_url = 'https://morvanzhou.github.io/'
10
11 # DON'T OVER CRAWL THE WEBSITE OR YOU MAY NEVER VISIT AGAIN
12 ##如果不是一样的url,则限制爬取
13 if base_url != "http://127.0.0.1:4000/":
14 restricted_crawl = True
15 else:
16 restricted_crawl = False
17
18 def crawl(url):#定义爬取网页功能
19 response = urlopen(url)
20 # time.sleep(0.1) # 下载延迟设定1秒,slightly delay for downloading
21 return response.read().decode()#返回原始的html页面
22
23 def parse(html):#定义解析网页功能
24 soup = BeautifulSoup(html, 'lxml')
25 urls = soup.find_all('a', {"href": re.compile('^/.+?/$')})
26 title = soup.find('h1').get_text().strip()
27 page_urls = set([urljoin(base_url, url['href']) for url in urls])
28 url = soup.find('meta', {'property': "og:url"})['content']
29 return title, page_urls, url
30
31 unseen = set([base_url, ])#未爬取的网页
32 seen = set()#看过的网页
33
34 count, t1 = 1, time.time()
35
36 while len(unseen) != 0: # still get some url to visit如果有没看过的网页
37 if restricted_crawl and len(seen) > 20:
38 break
39
40 print('\nDistributed Crawling...')
41 htmls = [crawl(url) for url in unseen]#爬取
42
43 print('\nDistributed Parsing...')
44 results = [parse(html) for html in htmls]#解析
45
46 print('\nAnalysing...')#分析
47 seen.update(unseen) # seen the crawled
48 unseen.clear() # nothing unseen
49
50 for title, page_urls, url in results:
51 print(count, title, url)
52 count += 1
53 unseen.update(page_urls - seen) # get new url to crawl
54 print('Total time: %.1f s' % (time.time() - t1,)) # 运行时间
1 # #多进程爬虫
2 import multiprocessing as mp
3 import time
4 from urllib.request import urlopen, urljoin
5 from bs4 import BeautifulSoup
6 import re
7 base_url = "http://127.0.0.1:4000/"
8 unseen = set([base_url,])
9 seen = set()
10
11 if base_url != "http://127.0.0.1:4000/":
12 restricted_crawl = True
13 else:
14 restricted_crawl = False
15
16 def crawl(url):#定义爬取网页功能
17 response = urlopen(url)
18 # time.sleep(0.1) # 下载延迟设定1秒,slightly delay for downloading
19 return response.read().decode()#返回原始的html页面
20 def parse(html):#定义解析网页功能
21 soup = BeautifulSoup(html, 'lxml')
22 urls = soup.find_all('a', {"href": re.compile('^/.+?/$')})
23 title = soup.find('h1').get_text().strip()
24 page_urls = set([urljoin(base_url, url['href']) for url in urls])
25 url = soup.find('meta', {'property': "og:url"})['content']
26 return title, page_urls, url
27
28 pool = mp.Pool(processes=1)
29 count, t1 = 1, time.time()
30 while len(unseen) != 0: # still get some url to visit
31 if restricted_crawl and len(seen) > 20:
32 break
33 print('\nDistributed Crawling...')
34 crawl_jobs = [pool.apply_async(crawl, args=(url,)) for url in unseen]
35 htmls = [j.get() for j in crawl_jobs] # request connection
36
37 print('\nDistributed Parsing...')
38 parse_jobs = [pool.apply_async(parse, args=(html,)) for html in htmls]
39 results = [j.get() for j in parse_jobs] # parse html
40
41 print('\nAnalysing...')
42 seen.update(unseen) # seen the crawled
43 unseen.clear() # nothing unseen
44
45 for title, page_urls, url in results:
46 print(count, title, url)
47 count += 1
48 unseen.update(page_urls - seen) # get new url to crawl
49 print('Total time: %.1f s' % (time.time()-t1, )) #
1 #异步加速爬虫
2 #在单线程里使用异步计算, 下载网页的时候和处理网页的时候是不连续的, 更有效利用了等待下载的这段时间.
3 import time
4 import asyncio
5 # asyncio 不是多进程, 也不是多线程, 单单是一个线程
6
7 #不用asyncio
8 def job(t):
9 print('Start job ', t)
10 time.sleep(t) # wait for "t" seconds
11 print('Job ', t, ' takes ', t, ' s')
12 def main():
13 [job(t) for t in range(1, 3)]
14 t1 = time.time()
15 main()
16 print("NO async total time : ", time.time() - t1)
17
18 #用asyncio
19 async def job(t):
20 print('Start job ', t)
21 await asyncio.sleep(t) # wait for "t" seconds, it will look for another job while await
22 #使用await不管上一步有没有运行完,运行下一步,休眠t秒
23 print('Job ', t, ' takes ', t, ' s')
24 async def main(loop):
25 tasks = [loop.create_task(job(t)) for t in range(1, 3)] # just create, not run job
26 await asyncio.wait(tasks) # run jobs and wait for all tasks done
27 #在 Python 的功能间切换着执行. 切换的点用 await 来标记
28 t1 = time.time()
29 loop = asyncio.get_event_loop()#获得loop
30 loop.run_until_complete(main(loop))#loop等待所有内容结束
31 # loop.close() # Ipython notebook gives error if close loop
32 print("Async total time : ", time.time() - t1)
33 -------------------------------------------
34 Start job 1
35 Job 1 takes 1 s
36 Start job 2
37 Job 2 takes 2 s
38 NO async total time : 3.000403881072998
39 Start job 1
40 Start job 2
41 Job 1 takes 1 s
42 Job 2 takes 2 s
43 Async total time : 2.0041451454162598
1 import aiohttp
2 import asyncio
3 import time
4
5 async def job(session):
6 response = await session.get('https://morvanzhou.github.io/')
7 return str(response.url)
8
9 async def main(loop):
10 async with aiohttp.ClientSession() as session:
11 tasks = [loop.create_task(job(session)) for _ in range(2)]
12 finished, unfinished = await asyncio.wait(tasks)
13 all_results = [r.result() for r in finished] # get return from job
14 print(all_results)
15
16 t1 = time.time()
17 loop = asyncio.get_event_loop()
18 loop.run_until_complete(main(loop))
19 # loop.close() # Ipython notebook gives error if close loop
20 print("Async total time:", time.time() - t1)
21 ---------------------------------------------------
22 ['https://morvanzhou.github.io/', 'https://morvanzhou.github.io/']
23 Async total time: 1.379730463027954
1 import aiohttp#基于asyncio的爬取模块
2 import asyncio
3 import time
4 from bs4 import BeautifulSoup
5 from urllib.request import urljoin
6 import re
7 import multiprocessing as mp
8
9 base_url = "https://morvanzhou.github.io/"
10
11 seen = set()
12 unseen = set([base_url])
13
14 def parse(html):
15 soup = BeautifulSoup(html, 'lxml')
16 urls = soup.find_all('a', {"href": re.compile('^/.+?/$')})
17 title = soup.find('h1').get_text().strip()
18 page_urls = set([urljoin(base_url, url['href']) for url in urls])
19 url = soup.find('meta', {'property': "og:url"})['content']
20 return title, page_urls, url
21
22 async def crawl(url, session):
23 r = await session.get(url)
24 html = await r.text()
25 await asyncio.sleep(0.1) # slightly delay for downloading
26 return html
27
28 async def main(loop):
29 pool = mp.Pool(8) # slightly affected
30 async with aiohttp.ClientSession() as session:
31 count = 1
32 while len(unseen) != 0:
33 print('\nAsync Crawling...')
34 tasks = [loop.create_task(crawl(url, session)) for url in unseen]
35 finished, unfinished = await asyncio.wait(tasks)
36 htmls = [f.result() for f in finished]
37
38 print('\nDistributed Parsing...')
39 parse_jobs = [pool.apply_async(parse, args=(html,)) for html in htmls]
40 results = [j.get() for j in parse_jobs]
41
42 print('\nAnalysing...')
43 seen.update(unseen)
44 unseen.clear()
45 for title, page_urls, url in results:
46 # print(count, title, url)
47 unseen.update(page_urls - seen)
48 count += 1
49
50 if __name__ == "__main__":
51 t1 = time.time()
52 loop = asyncio.get_event_loop()
53 loop.run_until_complete(main(loop))
54 # loop.close()
55 print("Async total time: ", time.time() - t1)
56 -------------------------------------------------------------
57
58 Async Crawling...
59
60 Distributed Parsing...
61
62 Analysing...
63
64 Async Crawling...
65
66 Distributed Parsing...
67
68 Analysing...
69
70 Async Crawling...
71
72 Distributed Parsing...
73
74 Analysing...
75 Async total time: 12.158562183380127
八.高级爬虫
1.Selenium:它能控制你的浏览器, 有模有样地学人类”看”网页
http://selenium-python.readthedocs.io/
2.scrapy爬虫,整合了的爬虫框架
官网:https://scrapy.org/
文档:https://docs.scrapy.org/en/latest/
中文文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/

九.scrapy
1.安装:(1)python (2)pywin32 (3)pip离线安装lxml
https://sourceforge.net/projects/pywin32/files/pywin32/
www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
https://blog.csdn.net/nima1994/article/details/74931621?locationNum=10&fps=1
https://www.cnblogs.com/leenid/p/7029015.html
2.创建scrapy项目
命令行:scrapy startproject tutorial 创建一个名字为tutorial的scrapy项目
创建的项目中包含文件:


3.item
(1)从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selector

(2)selector四个基本的方法

1 #spiders中新建爬虫文件
2 import scrapy
3
4 class GanjiSpider(scrapy.Spider):#定义爬虫类
5 name = "zufang"#爬虫的名称
6 start_urls = [#开始的爬虫路径
7 'https://bj.ganji.com/fang1/chaoyang/',
8 ]
9 def parse(self, response):#爬虫启动时,爬取链接成功后自动回调的函数,默认parse(self,response)
10 print(response)
11 titie_list=response.xpath(".//[@class='f-list-item']/d1/dd[1]/a/text()").extract()
12 #获取标题列表
13 #response网址服务器响应请求,发回响应信息
14 #xpath用来从网页中提取数据
15 #extract序列化为Unicode字符串
16 money_list=response.xpath(".//[@class='f-list-item']/d1/dd[5]/div[1]/span[1]/text()").extract()
17 #获取租金
18 for i,j in zip(titie_list,money_list):
19 print(i,':')
20
21 #命令行:
22 #scrapy shell 网址 打开网站
23 #scrpy list列取当前目录下存在的爬虫脚本 >>>zufang
24 #scrapy crawl zufang利用scrapy框架对爬虫脚本(zufang)进行爬虫
4.存储 scrapy crawl dmoz -o items.json

 浙公网安备 33010602011771号
浙公网安备 33010602011771号